 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRACULA: Hunting for the Actions Users Want Deep Research Agents to Execute
Apr 26, 2026Scientific Deep Research (DR) agents answer user queries by synthesizing research papers into multi-section reports. User feedback can improve their utility, but existing protocols only score the final report, making it hard to study and learn which intermediate actions DR agents should take to improve reports. We collect DRACULA, the first dataset with user feedback on intermediate actions for DR. Over five weeks, nineteen expert CS researchers ask queries to a DR system that proposes actions (e.g., "Add a section on datasets"). Our users select actions they prefer, then judge whether an output report applied their selections successfully, yielding 8,103 action preferences and 5,230 execution judgments. After confirming a DR agent can execute DRACULA's actions, we study the predictability of user-preferred actions via simulation-how well LLMs predict the actions users select-a step toward learning to generate useful actions. We discover: (1) LLM judges initially struggle to predict action selections, but improve most when using a user's full selection history, rather than self-reported or extrapolated user context signals; (2) Users' selections for the same query differ based on unstated goals, bottlenecking simulation and motivating affordances that let users steer reports; and (3) Our simulation results inform an online intervention that generates new actions based on the user's past interactions, which users pick most often in follow-up studies. Overall, while work extensively studies execution, DRACULA reveals a key challenge is deciding which actions to execute in the first place. We open-source DRACULA's study design, user feedback, and simulation tasks to spur future work on action feedback for long-horizon agents.
Language Models Don't Know What You Want: Evaluating Personalization in Deep Research Needs Real Users
Mar 17, 2026Deep Research (DR) tools (e.g. OpenAI DR) help researchers cope with ballooning publishing counts. Such tools can synthesize scientific papers to answer researchers' queries, but lack understanding of their users. We change that in MyScholarQA (MySQA), a personalized DR tool that: 1) infers a profile of a user's research interests; 2) proposes personalized actions for a user's input query; and 3) writes a multi-section report for the query that follows user-approved actions. We first test MySQA with NLP's standard protocol: we design a benchmark of synthetic users and LLM judges, where MySQA beats baselines in citation metrics and personalized action-following. However, we suspect this process does not cover all aspects of personalized DR users value, so we interview users in an online version of MySQA to unmask them. We reveal nine nuanced errors of personalized DR undetectable by our LLM judges, and we study qualitative feedback to form lessons for future DR design. In all, we argue for a pillar of personalization that easy-to-use LLM judges can lead NLP to overlook: real progress in personalization is only possible with real users.
BenchMarker: An Education-Inspired Toolkit for Highlighting Flaws in Multiple-Choice Benchmarks
Feb 05, 2026Multiple-choice question answering (MCQA) is standard in NLP, but benchmarks lack rigorous quality control. We present BenchMarker, an education-inspired toolkit using LLM judges to flag three common MCQ flaws: 1) contamination - items appearing exactly online; 2) shortcuts - cues in the choices that enable guessing; and 3) writing errors - structural/grammatical issues based on a 19-rule education rubric. We validate BenchMarker with human annotations, then run the tool to audit 12 benchmarks, revealing: 2) contaminated MCQs tend to inflate accuracy, while writing errors tend to lower it and change rankings beyond random; and 3) prior benchmark repairs address their targeted issues (i.e., lowering accuracy with LLM-written distractors), but inadvertently add new flaws (i.e. implausible distractors, many correct answers). Overall, flaws in MCQs degrade NLP evaluation, but education research offers a path forward. We release BenchMarker to bridge the fields and improve MCQA benchmark design.
AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
Test-Time Reasoners Are Strategic Multiple-Choice Test-Takers
Oct 09, 2025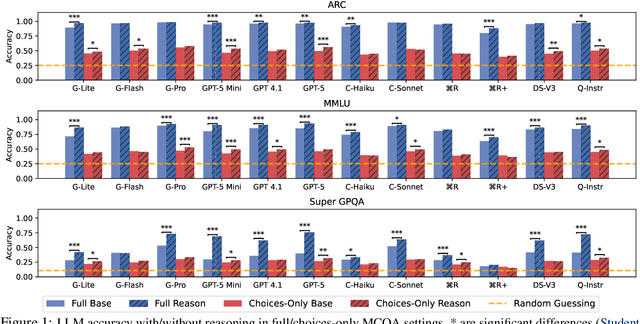

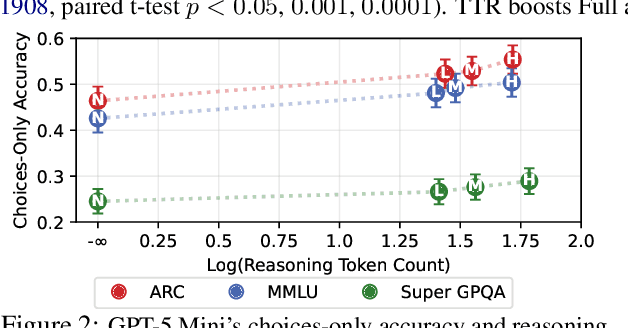
Large language models (LLMs) now give reasoning before answering, excelling in tasks like multiple-choice question answering (MCQA). Yet, a concern is that LLMs do not solve MCQs as intended, as work finds LLMs sans reasoning succeed in MCQA without using the question, i.e., choices-only. Such partial-input success is often deemed problematic, but reasoning traces could reveal if these strategies are truly shallow in choices-only settings. To study these strategies, reasoning LLMs solve MCQs in full and choices-only inputs; test-time reasoning often boosts accuracy on full and in choices-only half the time. While possibly due to shallow shortcuts, choices-only success is barely affected by the length of reasoning traces, and after finding traces pass faithfulness tests, we show they use less problematic strategies like inferring missing questions. In all, we challenge claims that partial-input success is always a flaw, so we discuss how reasoning traces could separate problematic data from less problematic reasoning.
Which of These Best Describes Multiple Choice Evaluation with LLMs? A) Forced B) Flawed C) Fixable D) All of the Above
Feb 19, 2025



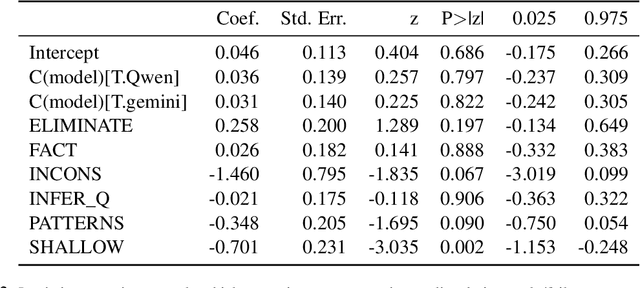
Multiple choice question answering (MCQA) is popular for LLM evaluation due to its simplicity and human-like testing, but we argue for its reform. We first reveal flaws in MCQA's format, as it struggles to: 1) test generation/subjectivity; 2) match LLM use cases; and 3) fully test knowledge. We instead advocate for generative formats based on human testing-where LLMs construct and explain answers-better capturing user needs and knowledge while remaining easy to score. We then show even when MCQA is a useful format, its datasets suffer from: leakage; unanswerability; shortcuts; and saturation. In each issue, we give fixes from education, like rubrics to guide MCQ writing; scoring methods to bridle guessing; and Item Response Theory to build harder MCQs. Lastly, we discuss LLM errors in MCQA-robustness, biases, and unfaithful explanations-showing how our prior solutions better measure or address these issues. While we do not need to desert MCQA, we encourage more efforts in refining the task based on educational testing, advancing evaluations.
Whose Boat Does it Float? Improving Personalization in Preference Tuning via Inferred User Personas
Jan 20, 2025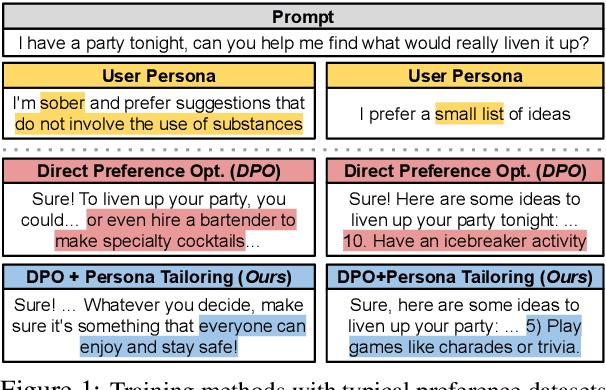

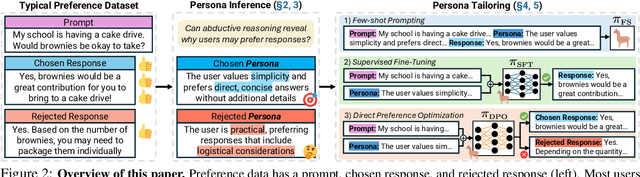
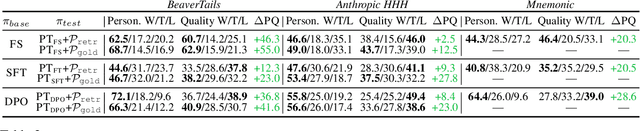
LLMs are tuned to follow instructions (aligned) by learning which of two outputs users prefer for a prompt. However, this preference data format does not convey why users prefer responses that are chosen or rejected, so LLMs trained on these datasets cannot tailor responses to varied user needs. To surface these parameters of personalization, we apply abductive reasoning to preference data, inferring needs and interests of users, i.e. personas, that may prefer each output. We test this idea in two steps: Persona Inference (PI)-abductively inferring personas of users who prefer chosen or rejected outputs-and Persona Tailoring (PT)-training models to tailor responses to personas from PI. We find: 1) LLMs infer personas accurately explaining why different users may prefer both chosen or rejected outputs; 2) Training on preference data augmented with PI personas via PT boosts personalization, enabling models to support user-written personas; and 3) Rejected response personas form harder personalization evaluations, showing PT better aids users with uncommon preferences versus typical alignment methods. We argue for an abductive view of preferences for personalization, asking not only which response is better but when, why, and for whom.
Reverse Question Answering: Can an LLM Write a Question so Hard (or Bad) that it Can't Answer?
Oct 20, 2024Question answering (QA)-producing correct answers for input questions-is popular, but we test a reverse question answering (RQA) task: given an input answer, generate a question with that answer. Past work tests QA and RQA separately, but we test them jointly, comparing their difficulty, aiding benchmark design, and assessing reasoning consistency. 16 LLMs run QA and RQA with trivia questions/answers, showing: 1) Versus QA, LLMs are much less accurate in RQA for numerical answers, but slightly more accurate in RQA for textual answers; 2) LLMs often answer their own invalid questions from RQA accurately in QA, so RQA errors are not from knowledge gaps alone; 3) RQA errors correlate with question difficulty and inversely correlate with answer frequencies in the Dolma corpus; and 4) LLMs struggle to give valid multi-hop questions. By finding question and answer types yielding RQA errors, we suggest improvements for LLM RQA reasoning.
Plausibly Problematic Questions in Multiple-Choice Benchmarks for Commonsense Reasoning
Oct 06, 2024Questions involving commonsense reasoning about everyday situations often admit many $\textit{possible}$ or $\textit{plausible}$ answers. In contrast, multiple-choice question (MCQ) benchmarks for commonsense reasoning require a hard selection of a single correct answer, which, in principle, should represent the $\textit{most}$ plausible answer choice. On $250$ MCQ items sampled from two commonsense reasoning benchmarks, we collect $5,000$ independent plausibility judgments on answer choices. We find that for over 20% of the sampled MCQs, the answer choice rated most plausible does not match the benchmark gold answers; upon manual inspection, we confirm that this subset exhibits higher rates of problems like ambiguity or semantic mismatch between question and answer choices. Experiments with LLMs reveal low accuracy and high variation in performance on the subset, suggesting our plausibility criterion may be helpful in identifying more reliable benchmark items for commonsense evaluation.
Is Your Large Language Model Knowledgeable or a Choices-Only Cheater?
Jul 02, 2024



Recent work shows that large language models (LLMs) can answer multiple-choice questions using only the choices, but does this mean that MCQA leaderboard rankings of LLMs are largely influenced by abilities in choices-only settings? To answer this, we use a contrast set that probes if LLMs over-rely on choices-only shortcuts in MCQA. While previous works build contrast sets via expensive human annotations or model-generated data which can be biased, we employ graph mining to extract contrast sets from existing MCQA datasets. We use our method on UnifiedQA, a group of six commonsense reasoning datasets with high choices-only accuracy, to build an 820-question contrast set. After validating our contrast set, we test 12 LLMs, finding that these models do not exhibit reliance on choice-only shortcuts when given both the question and choices. Thus, despite the susceptibility~of MCQA to high choices-only accuracy, we argue that LLMs are not obtaining high ranks on MCQA leaderboards just due to their ability to exploit choices-only shortcuts.