 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarco DeepResearch: Unlocking Efficient Deep Research Agents via Verification-Centric Design
Mar 30, 2026Deep research agents autonomously conduct open-ended investigations, integrating complex information retrieval with multi-step reasoning across diverse sources to solve real-world problems. To sustain this capability on long-horizon tasks, reliable verification is critical during both training and inference. A major bottleneck in existing paradigms stems from the lack of explicit verification mechanisms in QA data synthesis, trajectory construction, and test-time scaling. Errors introduced at each stage propagate downstream and degrade the overall agent performance. To address this, we present Marco DeepResearch, a deep research agent optimized with a verification-centric framework design at three levels: \textbf{(1)~QA Data Synthesis:} We introduce verification mechanisms to graph-based and agent-based QA synthesis to control question difficulty while ensuring answers are unique and correct; \textbf{(2)~Trajectory Construction:} We design a verification-driven trajectory synthesis method that injects explicit verification patterns into training trajectories; and \textbf{(3)~Test-time scaling:} We use Marco DeepResearch itself as a verifier at inference time and effectively improve performance on challenging questions. Extensive experimental results demonstrate that our proposed Marco DeepResearch agent significantly outperforms 8B-scale deep research agents on most challenging benchmarks, such as BrowseComp and BrowseComp-ZH. Crucially, under a maximum budget of 600 tool calls, Marco DeepResearch even surpasses or approaches several 30B-scale agents, like Tongyi DeepResearch-30B.
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
Large Language Models Are Effective Human Annotation Assistants, But Not Good Independent Annotators
Mar 09, 2025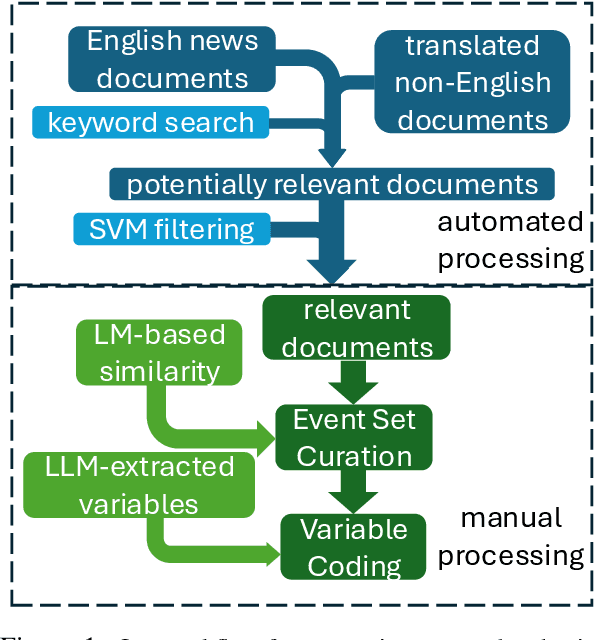
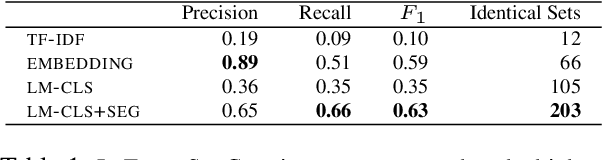

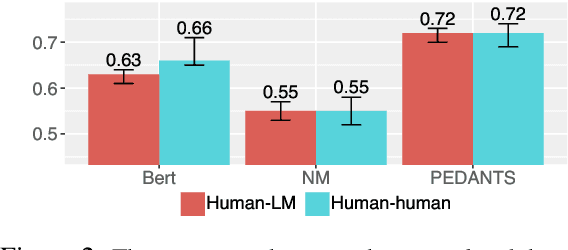
Event annotation is important for identifying market changes, monitoring breaking news, and understanding sociological trends. Although expert annotators set the gold standards, human coding is expensive and inefficient. Unlike information extraction experiments that focus on single contexts, we evaluate a holistic workflow that removes irrelevant documents, merges documents about the same event, and annotates the events. Although LLM-based automated annotations are better than traditional TF-IDF-based methods or Event Set Curation, they are still not reliable annotators compared to human experts. However, adding LLMs to assist experts for Event Set Curation can reduce the time and mental effort required for Variable Annotation. When using LLMs to extract event variables to assist expert annotators, they agree more with the extracted variables than fully automated LLMs for annotation.
Should I Trust You? Detecting Deception in Negotiations using Counterfactual RL
Feb 18, 2025An increasingly prevalent socio-technical problem is people being taken in by offers that sound ``too good to be true'', where persuasion and trust shape decision-making. This paper investigates how \abr{ai} can help detect these deceptive scenarios. We analyze how humans strategically deceive each other in \textit{Diplomacy}, a board game that requires both natural language communication and strategic reasoning. This requires extracting logical forms of proposed agreements in player communications and computing the relative rewards of the proposal using agents' value functions. Combined with text-based features, this can improve our deception detection. Our method detects human deception with a high precision when compared to a Large Language Model approach that flags many true messages as deceptive. Future human-\abr{ai} interaction tools can build on our methods for deception detection by triggering \textit{friction} to give users a chance of interrogating suspicious proposals.
LHRS-Bot-Nova: Improved Multimodal Large Language Model for Remote Sensing Vision-Language Interpretation
Nov 14, 2024

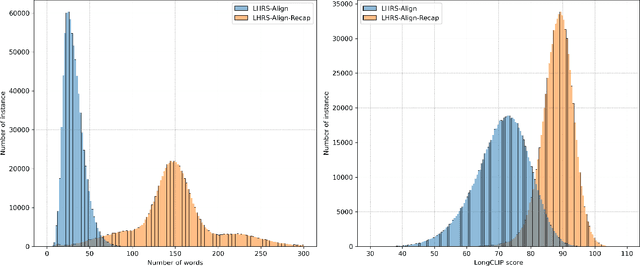

Automatically and rapidly understanding Earth's surface is fundamental to our grasp of the living environment and informed decision-making. This underscores the need for a unified system with comprehensive capabilities in analyzing Earth's surface to address a wide range of human needs. The emergence of multimodal large language models (MLLMs) has great potential in boosting the efficiency and convenience of intelligent Earth observation. These models can engage in human-like conversations, serve as unified platforms for understanding images, follow diverse instructions, and provide insightful feedbacks. In this study, we introduce LHRS-Bot-Nova, an MLLM specialized in understanding remote sensing (RS) images, designed to expertly perform a wide range of RS understanding tasks aligned with human instructions. LHRS-Bot-Nova features an enhanced vision encoder and a novel bridge layer, enabling efficient visual compression and better language-vision alignment. To further enhance RS-oriented vision-language alignment, we propose a large-scale RS image-caption dataset, generated through feature-guided image recaptioning. Additionally, we introduce an instruction dataset specifically designed to improve spatial recognition abilities. Extensive experiments demonstrate superior performance of LHRS-Bot-Nova across various RS image understanding tasks. We also evaluate different MLLM performances in complex RS perception and instruction following using a complicated multi-choice question evaluation benchmark, providing a reliable guide for future model selection and improvement. Data, code, and models will be available at https://github.com/NJU-LHRS/LHRS-Bot.
Personalized Help for Optimizing Low-Skilled Users' Strategy
Nov 14, 2024AIs can beat humans in game environments; however, how helpful those agents are to human remains understudied. We augment CICERO, a natural language agent that demonstrates superhuman performance in Diplomacy, to generate both move and message advice based on player intentions. A dozen Diplomacy games with novice and experienced players, with varying advice settings, show that some of the generated advice is beneficial. It helps novices compete with experienced players and in some instances even surpass them. The mere presence of advice can be advantageous, even if players do not follow it.
Reverse Question Answering: Can an LLM Write a Question so Hard (or Bad) that it Can't Answer?
Oct 20, 2024Question answering (QA)-producing correct answers for input questions-is popular, but we test a reverse question answering (RQA) task: given an input answer, generate a question with that answer. Past work tests QA and RQA separately, but we test them jointly, comparing their difficulty, aiding benchmark design, and assessing reasoning consistency. 16 LLMs run QA and RQA with trivia questions/answers, showing: 1) Versus QA, LLMs are much less accurate in RQA for numerical answers, but slightly more accurate in RQA for textual answers; 2) LLMs often answer their own invalid questions from RQA accurately in QA, so RQA errors are not from knowledge gaps alone; 3) RQA errors correlate with question difficulty and inversely correlate with answer frequencies in the Dolma corpus; and 4) LLMs struggle to give valid multi-hop questions. By finding question and answer types yielding RQA errors, we suggest improvements for LLM RQA reasoning.
More Victories, Less Cooperation: Assessing Cicero's Diplomacy Play
Jun 07, 2024The boardgame Diplomacy is a challenging setting for communicative and cooperative artificial intelligence. The most prominent communicative Diplomacy AI, Cicero, has excellent strategic abilities, exceeding human players. However, the best Diplomacy players master communication, not just tactics, which is why the game has received attention as an AI challenge. This work seeks to understand the degree to which Cicero succeeds at communication. First, we annotate in-game communication with abstract meaning representation to separate in-game tactics from general language. Second, we run two dozen games with humans and Cicero, totaling over 200 human-player hours of competition. While AI can consistently outplay human players, AI-Human communication is still limited because of AI's difficulty with deception and persuasion. This shows that Cicero relies on strategy and has not yet reached the full promise of communicative and cooperative AI.
A Neighbor-Searching Discrepancy-based Drift Detection Scheme for Learning Evolving Data
May 23, 2024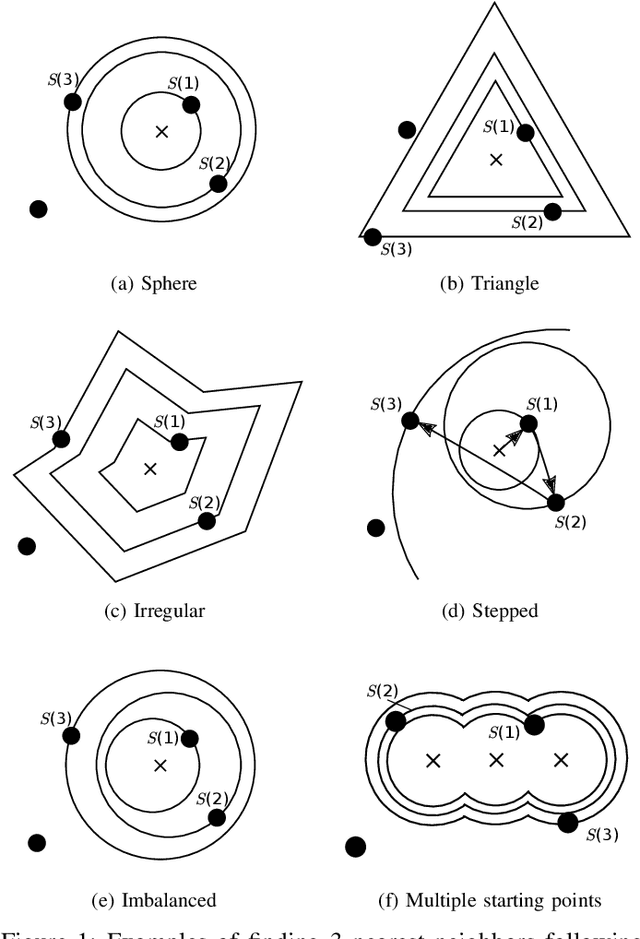
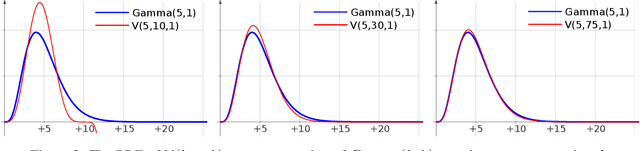
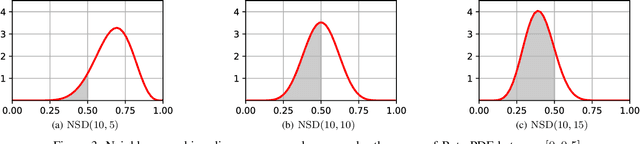
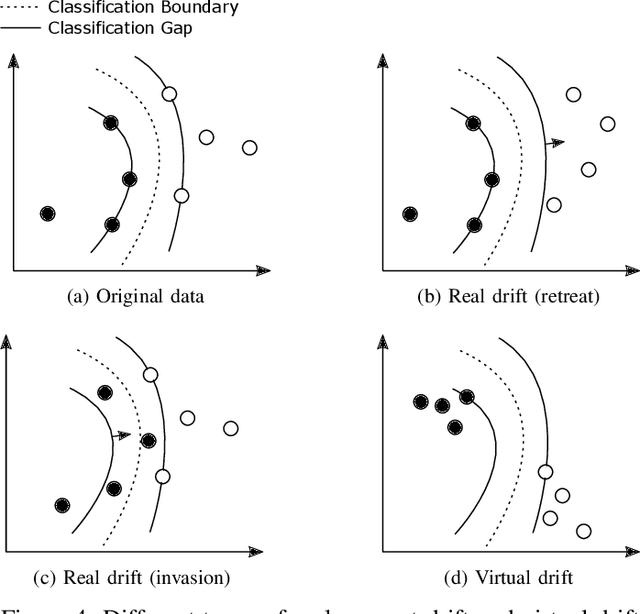
Uncertain changes in data streams present challenges for machine learning models to dynamically adapt and uphold performance in real-time. Particularly, classification boundary change, also known as real concept drift, is the major cause of classification performance deterioration. However, accurately detecting real concept drift remains challenging because the theoretical foundations of existing drift detection methods - two-sample distribution tests and monitoring classification error rate, both suffer from inherent limitations such as the inability to distinguish virtual drift (changes not affecting the classification boundary, will introduce unnecessary model maintenance), limited statistical power, or high computational cost. Furthermore, no existing detection method can provide information on the trend of the drift, which could be invaluable for model maintenance. This work presents a novel real concept drift detection method based on Neighbor-Searching Discrepancy, a new statistic that measures the classification boundary difference between two samples. The proposed method is able to detect real concept drift with high accuracy while ignoring virtual drift. It can also indicate the direction of the classification boundary change by identifying the invasion or retreat of a certain class, which is also an indicator of separability change between classes. A comprehensive evaluation of 11 experiments is conducted, including empirical verification of the proposed theory using artificial datasets, and experimental comparisons with commonly used drift handling methods on real-world datasets. The results show that the proposed theory is robust against a range of distributions and dimensions, and the drift detection method outperforms state-of-the-art alternative methods.
LHRS-Bot: Empowering Remote Sensing with VGI-Enhanced Large Multimodal Language Model
Feb 07, 2024
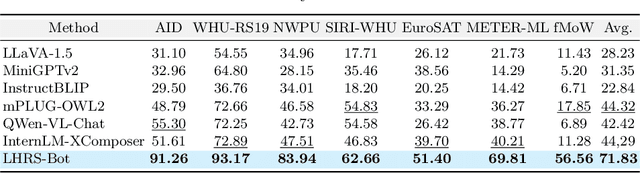


The revolutionary capabilities of large language models (LLMs) have paved the way for multimodal large language models (MLLMs) and fostered diverse applications across various specialized domains. In the remote sensing (RS) field, however, the diverse geographical landscapes and varied objects in RS imagery are not adequately considered in recent MLLM endeavors. To bridge this gap, we construct a large-scale RS image-text dataset, LHRS-Align, and an informative RS-specific instruction dataset, LHRS-Instruct, leveraging the extensive volunteered geographic information (VGI) and globally available RS images. Building on this foundation, we introduce LHRS-Bot, an MLLM tailored for RS image understanding through a novel multi-level vision-language alignment strategy and a curriculum learning method. Comprehensive experiments demonstrate that LHRS-Bot exhibits a profound understanding of RS images and the ability to perform nuanced reasoning within the RS domain.