 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Control of An Aerial Manipulator Based on A Variable Inertia Parameters Model
Jan 09, 2024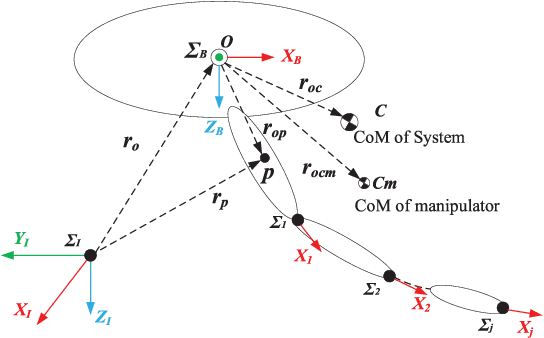
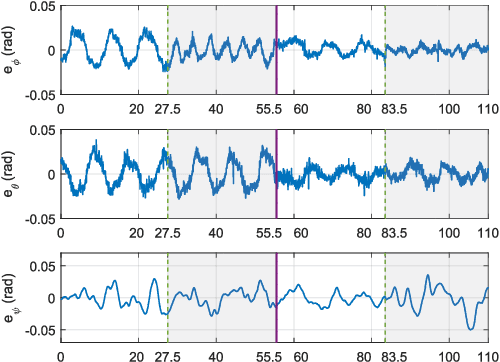
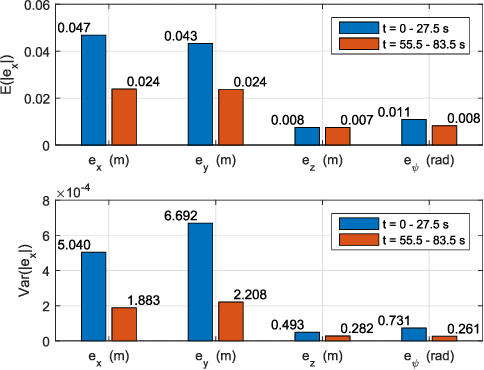
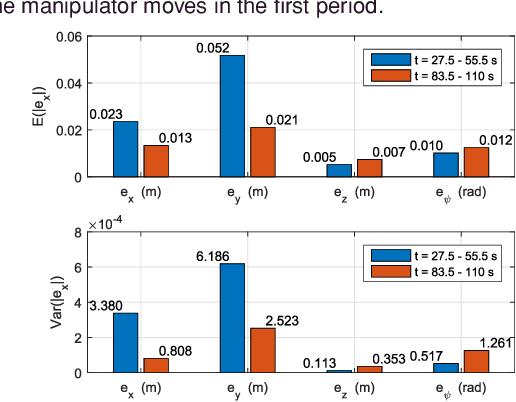
Aerial manipulator, which is composed of an UAV (Unmanned Aerial Vehicle) and a multi-link manipulator and can perform aerial manipulation, has shown great potential of applications. However, dynamic coupling between the UAV and the manipulator makes it difficult to control the aerial manipulator with high performance. In this paper, system modeling and control problem of the aerial manipulator are studied. Firstly, an UAV dynamic model is proposed with consideration of the dynamic coupling from an attached manipulator, which is treated as disturbance for the UAV. In the dynamic model, the disturbance is affected by the variable inertia parameters of the aerial manipulator system. Then, based on the proposed dynamic model, a disturbance compensation robust $H_{\infty}$ controller is designed to stabilize flight of the UAV while the manipulator is in operation. Finally, experiments are conducted and the experimental results demonstrate the feasibility and validity of the proposed control scheme.
An Aerial Manipulator for Robot-to-robot Torch Relay Task: System Design and Control Scheme
Jan 08, 2024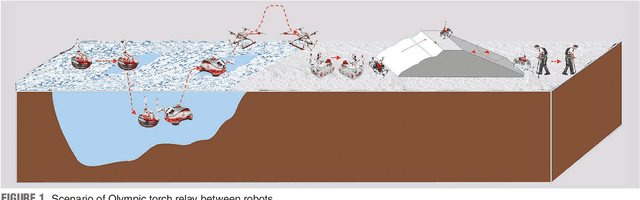
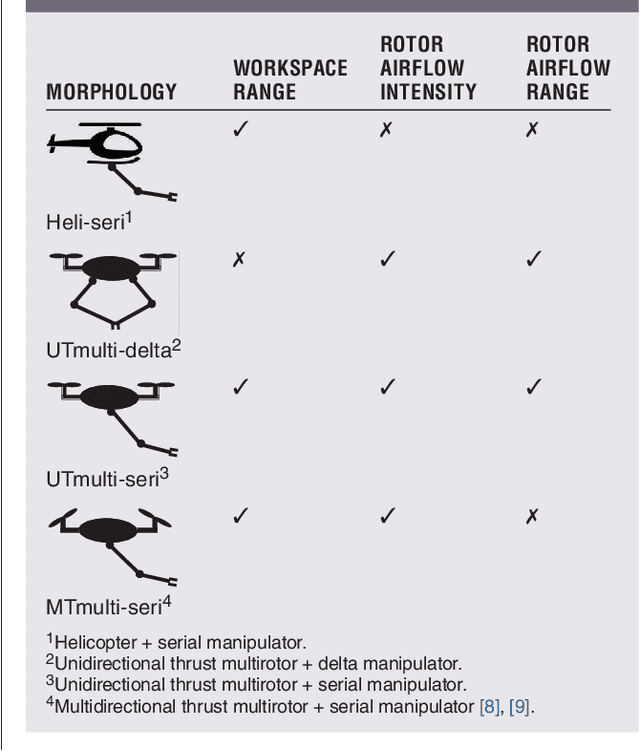
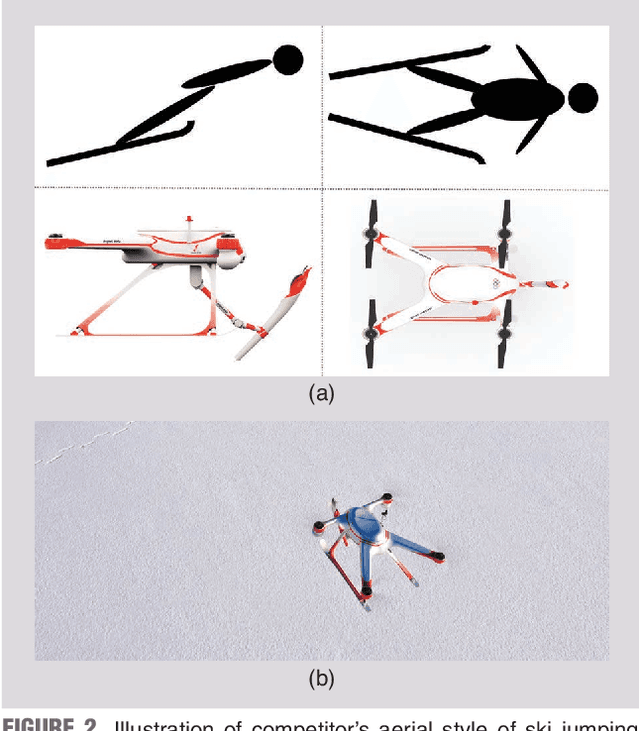
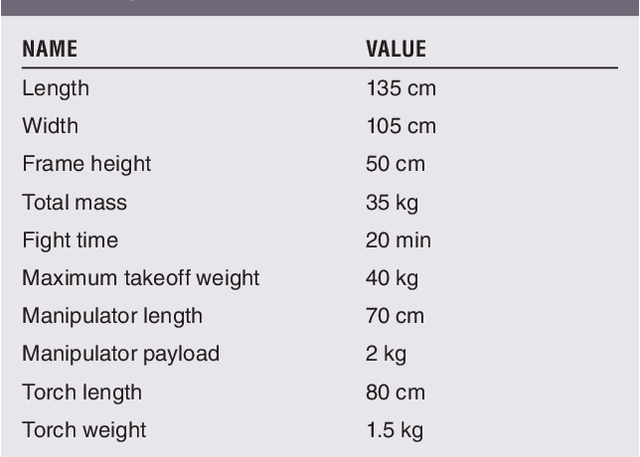
Torch relay is an important tradition of the Olympics and heralds the start of the Games. Robots applied in the torch relay activity can not only demonstrate the technological capability of humans to the world but also provide a sight of human lives with robots in the future. This article presents an aerial manipulator designed for the robot-to-robot torch relay task of the Beijing 2022 Winter Olympics. This aerial manipulator system is composed of a quadrotor, a 3 DoF (Degree of Freedom) manipulator, and a monocular camera. This article primarily describes the system design and system control scheme of the aerial manipulator. The experimental results demonstrate that it can complete robot-to-robot torch relay task under the guidance of vision in the ice and snow field.
Guided Time-optimal Model Predictive Control of a Multi-rotor
Jan 08, 2024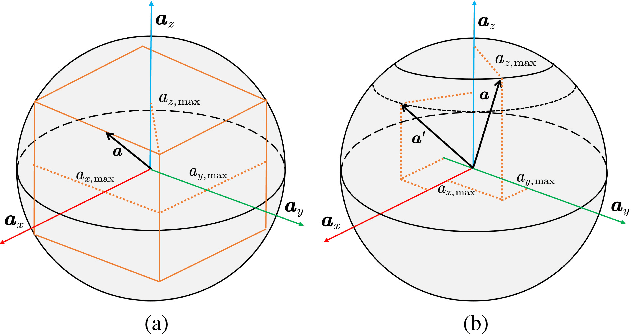

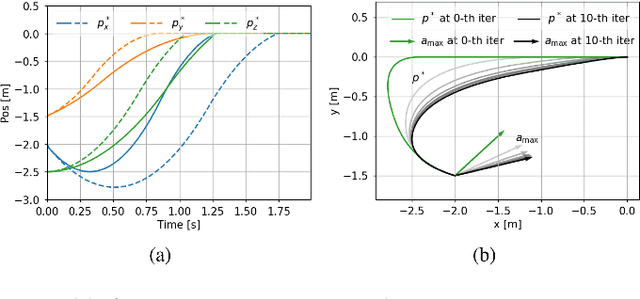
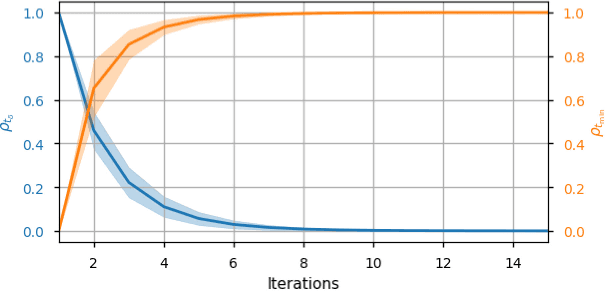
Time-optimal control of a multi-rotor remains an open problem due to the under-actuation and nonlinearity of its dynamics, which make it difficult to solve this problem directly. In this paper, the time-optimal control problem of the multi-rotor is studied. Firstly, a thrust limit optimal decomposition method is proposed, which can reasonably decompose the limited thrust into three directions according to the current state and the target state. As a result, the thrust limit constraint is decomposed as a linear constraint. With the linear constraint and decoupled dynamics, a time-optimal guidance trajectory can be obtained. Then, a cost function is defined based on the time-optimal guidance trajectory, which has a quadratic form and can be used to evaluate the time-optimal performance of the system outputs. Finally, based on the cost function, the time-optimal control problem is reformulated as an MPC (Model Predictive Control) problem. The experimental results demonstrate the feasibility and validity of the proposed methods.
* 6 pages, 5 figures
SCR-Graph: Spatial-Causal Relationships based Graph Reasoning Network for Human Action Prediction
Nov 22, 2019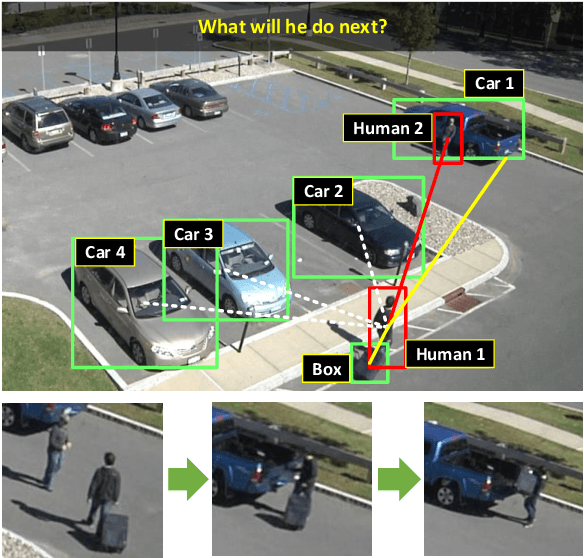


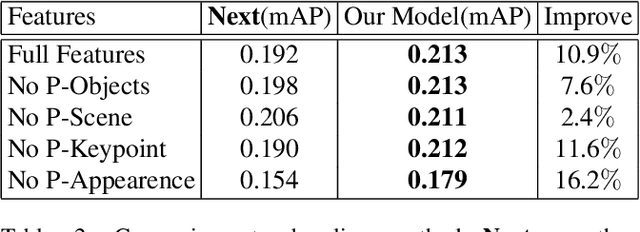
Technologies to predict human actions are extremely important for applications such as human robot cooperation and autonomous driving. However, a majority of the existing algorithms focus on exploiting visual features of the videos and do not consider the mining of relationships, which include spatial relationships between human and scene elements as well as causal relationships in temporal action sequences. In fact, human beings are good at using spatial and causal relational reasoning mechanism to predict the actions of others. Inspired by this idea, we proposed a Spatial and Causal Relationship based Graph Reasoning Network (SCR-Graph), which can be used to predict human actions by modeling the action-scene relationship, and causal relationship between actions, in spatial and temporal dimensions respectively. Here, in spatial dimension, a hierarchical graph attention module is designed by iteratively aggregating the features of different kinds of scene elements in different level. In temporal dimension, we designed a knowledge graph based causal reasoning module and map the past actions to temporal causal features through Diffusion RNN. Finally, we integrated the causality features into the heterogeneous graph in the form of shadow node, and introduced a self-attention module to determine the time when the knowledge graph information should be activated. Extensive experimental results on the VIRAT datasets demonstrate the favorable performance of the proposed framework.
MRS-VPR: a multi-resolution sampling based global visual place recognition method
Feb 26, 2019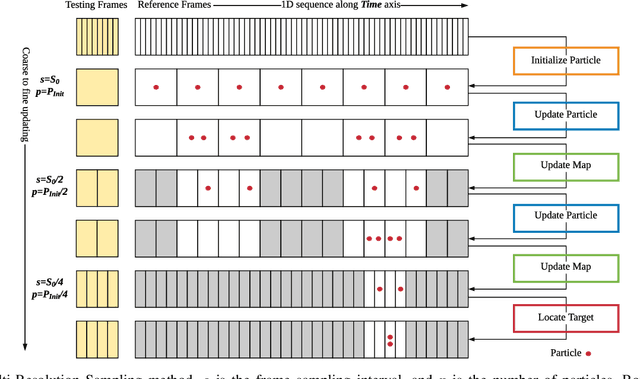
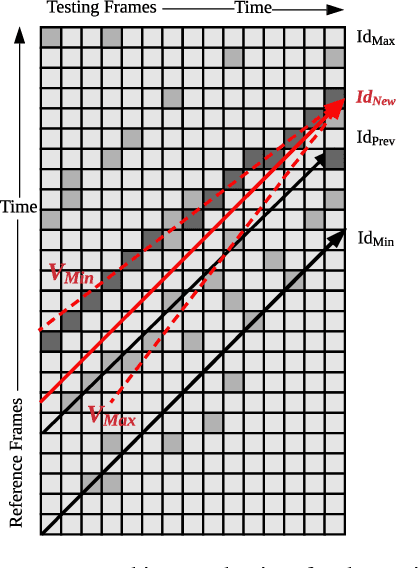
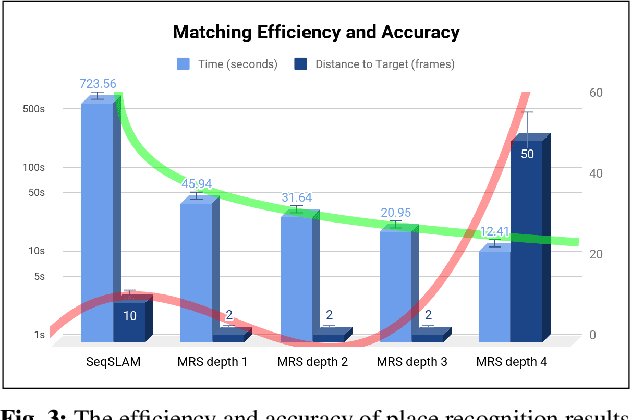
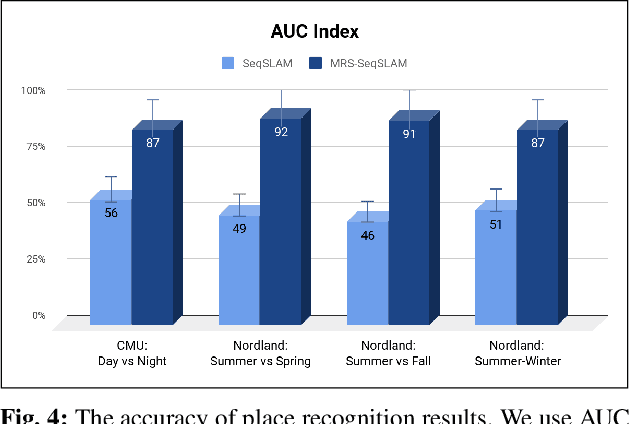
Place recognition and loop closure detection are challenging for long-term visual navigation tasks. SeqSLAM is considered to be one of the most successful approaches to achieving long-term localization under varying environmental conditions and changing viewpoints. It depends on a brute-force, time-consuming sequential matching method. We propose MRS-VPR, a multi-resolution, sampling-based place recognition method, which can significantly improve the matching efficiency and accuracy in sequential matching. The novelty of this method lies in the coarse-to-fine searching pipeline and a particle filter-based global sampling scheme, that can balance the matching efficiency and accuracy in the long-term navigation task. Moreover, our model works much better than SeqSLAM when the testing sequence has a much smaller scale than the reference sequence. Our experiments demonstrate that the proposed method is efficient in locating short temporary trajectories within long-term reference ones without losing accuracy compared to SeqSLAM.
A Multi-Domain Feature Learning Method for Visual Place Recognition
Feb 26, 2019
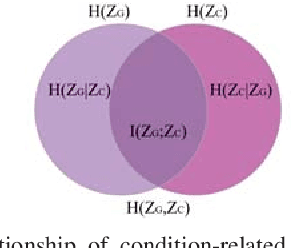


Visual Place Recognition (VPR) is an important component in both computer vision and robotics applications, thanks to its ability to determine whether a place has been visited and where specifically. A major challenge in VPR is to handle changes of environmental conditions including weather, season and illumination. Most VPR methods try to improve the place recognition performance by ignoring the environmental factors, leading to decreased accuracy decreases when environmental conditions change significantly, such as day versus night. To this end, we propose an end-to-end conditional visual place recognition method. Specifically, we introduce the multi-domain feature learning method (MDFL) to capture multiple attribute-descriptions for a given place, and then use a feature detaching module to separate the environmental condition-related features from those that are not. The only label required within this feature learning pipeline is the environmental condition. Evaluation of the proposed method is conducted on the multi-season \textit{NORDLAND} dataset, and the multi-weather \textit{GTAV} dataset. Experimental results show that our method improves the feature robustness against variant environmental conditions.
Synchronous Adversarial Feature Learning for LiDAR based Loop Closure Detection
Apr 05, 2018
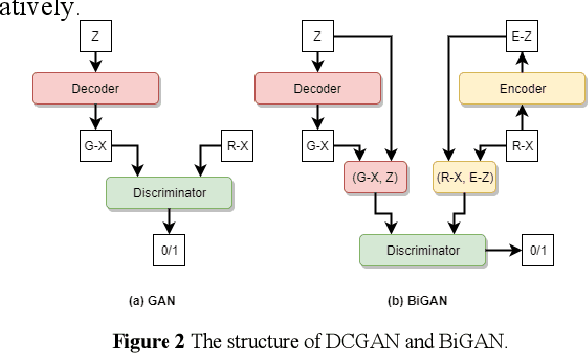
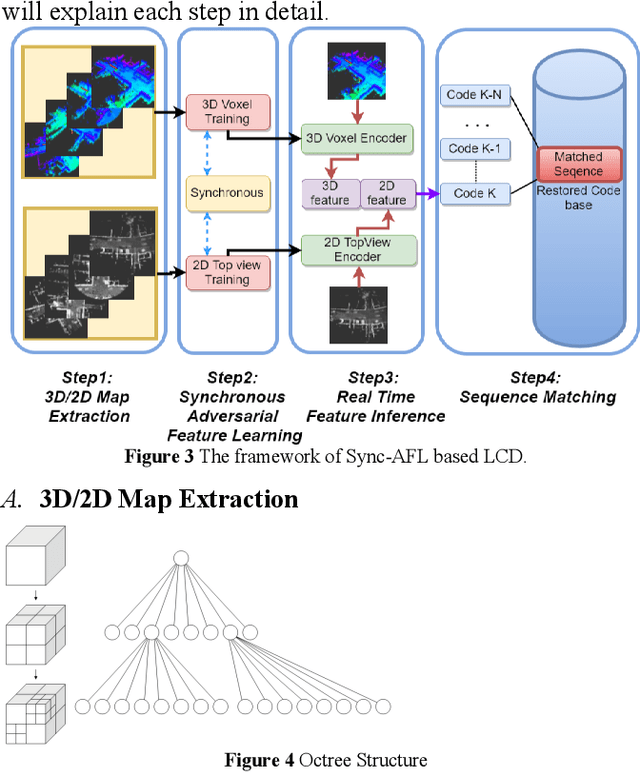
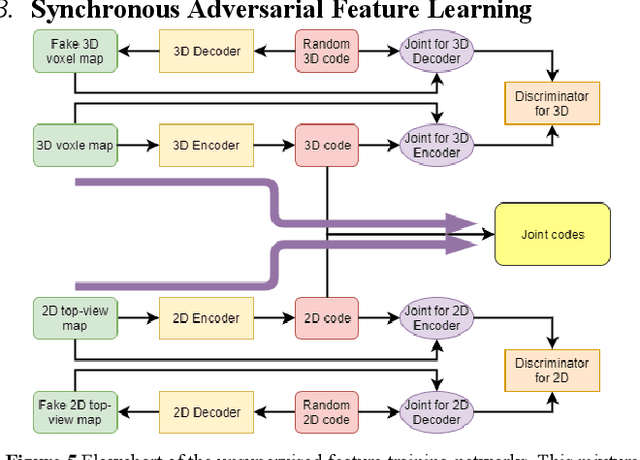
Loop Closure Detection (LCD) is the essential module in the simultaneous localization and mapping (SLAM) task. In the current appearance-based SLAM methods, the visual inputs are usually affected by illumination, appearance and viewpoints changes. Comparing to the visual inputs, with the active property, light detection and ranging (LiDAR) based point-cloud inputs are invariant to the illumination and appearance changes. In this paper, we extract 3D voxel maps and 2D top view maps from LiDAR inputs, and the former could capture the local geometry into a simplified 3D voxel format, the later could capture the local road structure into a 2D image format. However, the most challenge problem is to obtain efficient features from 3D and 2D maps to against the viewpoints difference. In this paper, we proposed a synchronous adversarial feature learning method for the LCD task, which could learn the higher level abstract features from different domains without any label data. To the best of our knowledge, this work is the first to extract multi-domain adversarial features for the LCD task in real time. To investigate the performance, we test the proposed method on the KITTI odometry dataset. The extensive experiments results show that, the proposed method could largely improve LCD accuracy even under huge viewpoints differences.
Condition directed Multi-domain Adversarial Learning for Loop Closure Detection
Nov 21, 2017
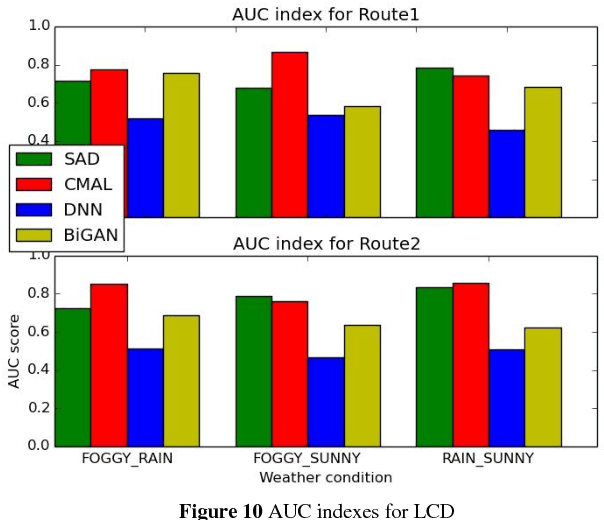

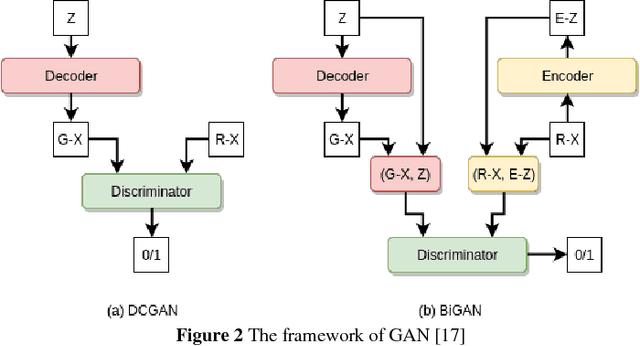
Loop closure detection (LCD) is the key module in appearance based simultaneously localization and mapping (SLAM). However, in the real life, the appearance of visual inputs are usually affected by the illumination changes and texture changes under different weather conditions. Traditional methods in LCD usually rely on handcraft features, however, such methods are unable to capture the common descriptions under different weather conditions, such as rainy, foggy and sunny. Furthermore, traditional handcraft features could not capture the highly level understanding for the local scenes. In this paper, we proposed a novel condition directed multi-domain adversarial learning method, where we use the weather condition as the direction for feature inference. Based on the generative adversarial networks (GANs) and a classification networks, the proposed method could extract the high-level weather-invariant features directly from the raw data. The only labels required here are the weather condition of each visual input. Experiments are conducted in the GTAV game simulator, which could generated lifelike outdoor scenes under different weather conditions. The performance of LCD results shows that our method outperforms the state-of-arts significantly.