 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-as-context: Modulating Explicit 3D in Scene-consistent Video Generation to Geometry Context
Feb 25, 2026Scene-consistent video generation aims to create videos that explore 3D scenes based on a camera trajectory. Previous methods rely on video generation models with external memory for consistency, or iterative 3D reconstruction and inpainting, which accumulate errors during inference due to incorrect intermediary outputs, non-differentiable processes, and separate models. To overcome these limitations, we introduce ``geometry-as-context". It iteratively completes the following steps using an autoregressive camera-controlled video generation model: (1) estimates the geometry of the current view necessary for 3D reconstruction, and (2) simulates and restores novel view images rendered by the 3D scene. Under this multi-task framework, we develop the camera gated attention module to enhance the model's capability to effectively leverage camera poses. During the training phase, text contexts are utilized to ascertain whether geometric or RGB images should be generated. To ensure that the model can generate RGB-only outputs during inference, the geometry context is randomly dropped from the interleaved text-image-geometry training sequence. The method has been tested on scene video generation with one-direction and forth-and-back trajectories. The results show its superiority over previous approaches in maintaining scene consistency and camera control.
Tele-Omni: a Unified Multimodal Framework for Video Generation and Editing
Feb 10, 2026Recent advances in diffusion-based video generation have substantially improved visual fidelity and temporal coherence. However, most existing approaches remain task-specific and rely primarily on textual instructions, limiting their ability to handle multimodal inputs, contextual references, and diverse video generation and editing scenarios within a unified framework. Moreover, many video editing methods depend on carefully engineered pipelines tailored to individual operations, which hinders scalability and composability. In this paper, we propose Tele-Omni, a unified multimodal framework for video generation and editing that follows multimodal instructions, including text, images, and reference videos, within a single model. Tele-Omni leverages pretrained multimodal large language models to parse heterogeneous instructions and infer structured generation or editing intents, while diffusion-based generators perform high-quality video synthesis conditioned on these structured signals. To enable joint training across heterogeneous video tasks, we introduce a task-aware data processing pipeline that unifies multimodal inputs into a structured instruction format while preserving task-specific constraints. Tele-Omni supports a wide range of video-centric tasks, including text-to-video generation, image-to-video generation, first-last-frame video generation, in-context video generation, and in-context video editing. By decoupling instruction parsing from video synthesis and combining it with task-aware data design, Tele-Omni achieves flexible multimodal control while maintaining strong temporal coherence and visual consistency. Experimental results demonstrate that Tele-Omni achieves competitive performance across multiple tasks.
HEDN: A Hard-Easy Dual Network with Task Difficulty Assessment for EEG Emotion Recognition
Nov 10, 2025Multi-source domain adaptation represents an effective approach to addressing individual differences in cross-subject EEG emotion recognition. However, existing methods treat all source domains equally, neglecting the varying transfer difficulties between different source domains and the target domain. This oversight can lead to suboptimal adaptation. To address this challenge, we propose a novel Hard-Easy Dual Network (HEDN), which dynamically identifies "Hard Source" and "Easy Source" through a Task Difficulty Assessment (TDA) mechanism and establishes two specialized knowledge adaptation branches. Specifically, the Hard Network is dedicated to handling "Hard Source" with higher transfer difficulty by aligning marginal distribution differences between source and target domains. Conversely, the Easy Network focuses on "Easy Source" with low transfer difficulty, utilizing a prototype classifier to model intra-class clustering structures while generating reliable pseudo-labels for the target domain through a prototype-guided label propagation algorithm. Extensive experiments on two benchmark datasets, SEED and SEED-IV, demonstrate that HEDN achieves state-of-the-art performance in cross-subject EEG emotion recognition, with average accuracies of 93.58\% on SEED and 79.82\% on SEED-IV, respectively. These results confirm the effectiveness and generalizability of HEDN in cross-subject EEG emotion recognition.
FA^{3}-CLIP: Frequency-Aware Cues Fusion and Attack-Agnostic Prompt Learning for Unified Face Attack Detection
Apr 01, 2025



Facial recognition systems are vulnerable to physical (e.g., printed photos) and digital (e.g., DeepFake) face attacks. Existing methods struggle to simultaneously detect physical and digital attacks due to: 1) significant intra-class variations between these attack types, and 2) the inadequacy of spatial information alone to comprehensively capture live and fake cues. To address these issues, we propose a unified attack detection model termed Frequency-Aware and Attack-Agnostic CLIP (FA\textsuperscript{3}-CLIP), which introduces attack-agnostic prompt learning to express generic live and fake cues derived from the fusion of spatial and frequency features, enabling unified detection of live faces and all categories of attacks. Specifically, the attack-agnostic prompt module generates generic live and fake prompts within the language branch to extract corresponding generic representations from both live and fake faces, guiding the model to learn a unified feature space for unified attack detection. Meanwhile, the module adaptively generates the live/fake conditional bias from the original spatial and frequency information to optimize the generic prompts accordingly, reducing the impact of intra-class variations. We further propose a dual-stream cues fusion framework in the vision branch, which leverages frequency information to complement subtle cues that are difficult to capture in the spatial domain. In addition, a frequency compression block is utilized in the frequency stream, which reduces redundancy in frequency features while preserving the diversity of crucial cues. We also establish new challenging protocols to facilitate unified face attack detection effectiveness. Experimental results demonstrate that the proposed method significantly improves performance in detecting physical and digital face attacks, achieving state-of-the-art results.
Robust Audio-Visual Segmentation via Audio-Guided Visual Convergent Alignment
Mar 17, 2025Accurately localizing audible objects based on audio-visual cues is the core objective of audio-visual segmentation. Most previous methods emphasize spatial or temporal multi-modal modeling, yet overlook challenges from ambiguous audio-visual correspondences such as nearby visually similar but acoustically different objects and frequent shifts in objects' sounding status. Consequently, they may struggle to reliably correlate audio and visual cues, leading to over- or under-segmentation. To address these limitations, we propose a novel framework with two primary components: an audio-guided modality alignment (AMA) module and an uncertainty estimation (UE) module. Instead of indiscriminately correlating audio-visual cues through a global attention mechanism, AMA performs audio-visual interactions within multiple groups and consolidates group features into compact representations based on their responsiveness to audio cues, effectively directing the model's attention to audio-relevant areas. Leveraging contrastive learning, AMA further distinguishes sounding regions from silent areas by treating features with strong audio responses as positive samples and weaker responses as negatives. Additionally, UE integrates spatial and temporal information to identify high-uncertainty regions caused by frequent changes in sound state, reducing prediction errors by lowering confidence in these areas. Experimental results demonstrate that our approach achieves superior accuracy compared to existing state-of-the-art methods, particularly in challenging scenarios where traditional approaches struggle to maintain reliable segmentation.
Dynamic Derivation and Elimination: Audio Visual Segmentation with Enhanced Audio Semantics
Mar 17, 2025Sound-guided object segmentation has drawn considerable attention for its potential to enhance multimodal perception. Previous methods primarily focus on developing advanced architectures to facilitate effective audio-visual interactions, without fully addressing the inherent challenges posed by audio natures, \emph{\ie}, (1) feature confusion due to the overlapping nature of audio signals, and (2) audio-visual matching difficulty from the varied sounds produced by the same object. To address these challenges, we propose Dynamic Derivation and Elimination (DDESeg): a novel audio-visual segmentation framework. Specifically, to mitigate feature confusion, DDESeg reconstructs the semantic content of the mixed audio signal by enriching the distinct semantic information of each individual source, deriving representations that preserve the unique characteristics of each sound. To reduce the matching difficulty, we introduce a discriminative feature learning module, which enhances the semantic distinctiveness of generated audio representations. Considering that not all derived audio representations directly correspond to visual features (e.g., off-screen sounds), we propose a dynamic elimination module to filter out non-matching elements. This module facilitates targeted interaction between sounding regions and relevant audio semantics. By scoring the interacted features, we identify and filter out irrelevant audio information, ensuring accurate audio-visual alignment. Comprehensive experiments demonstrate that our framework achieves superior performance in AVS datasets.
Not All Frame Features Are Equal: Video-to-4D Generation via Decoupling Dynamic-Static Features
Feb 12, 2025Recently, the generation of dynamic 3D objects from a video has shown impressive results. Existing methods directly optimize Gaussians using whole information in frames. However, when dynamic regions are interwoven with static regions within frames, particularly if the static regions account for a large proportion, existing methods often overlook information in dynamic regions and are prone to overfitting on static regions. This leads to producing results with blurry textures. We consider that decoupling dynamic-static features to enhance dynamic representations can alleviate this issue. Thus, we propose a dynamic-static feature decoupling module (DSFD). Along temporal axes, it regards the portions of current frame features that possess significant differences relative to reference frame features as dynamic features. Conversely, the remaining parts are the static features. Then, we acquire decoupled features driven by dynamic features and current frame features. Moreover, to further enhance the dynamic representation of decoupled features from different viewpoints and ensure accurate motion prediction, we design a temporal-spatial similarity fusion module (TSSF). Along spatial axes, it adaptively selects a similar information of dynamic regions. Hinging on the above, we construct a novel approach, DS4D. Experimental results verify our method achieves state-of-the-art (SOTA) results in video-to-4D. In addition, the experiments on a real-world scenario dataset demonstrate its effectiveness on the 4D scene. Our code will be publicly available.
An Aerial Manipulator for Robot-to-robot Torch Relay Task: System Design and Control Scheme
Jan 08, 2024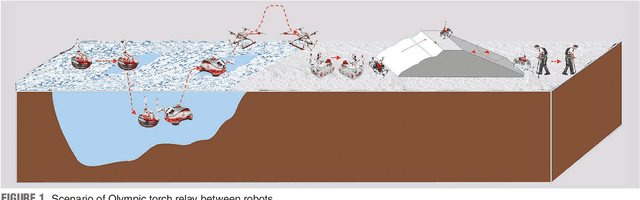
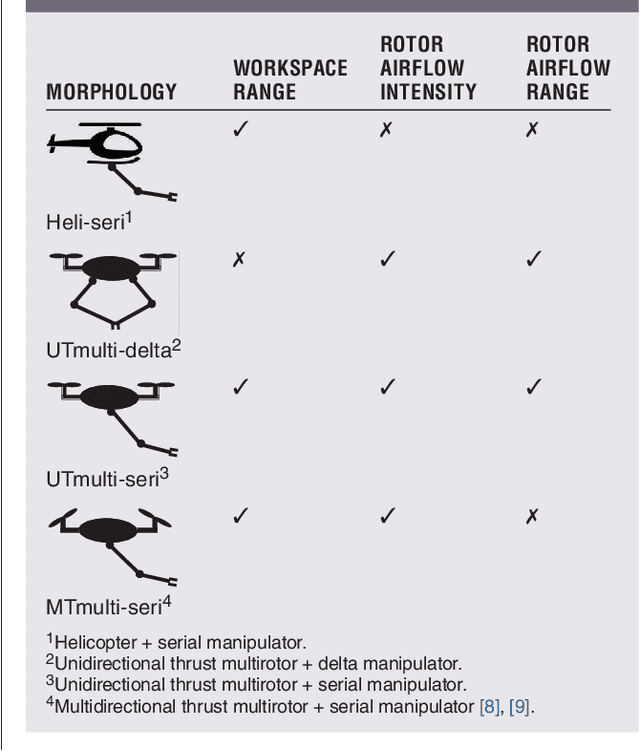
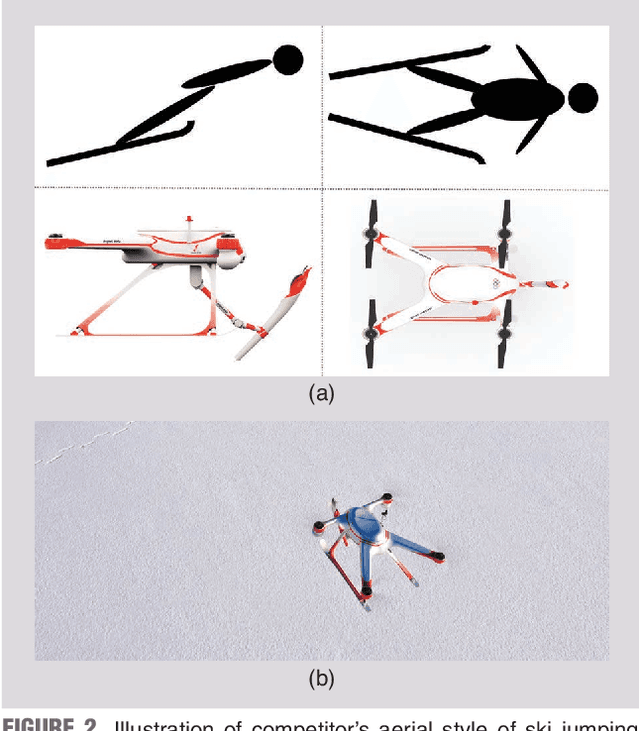
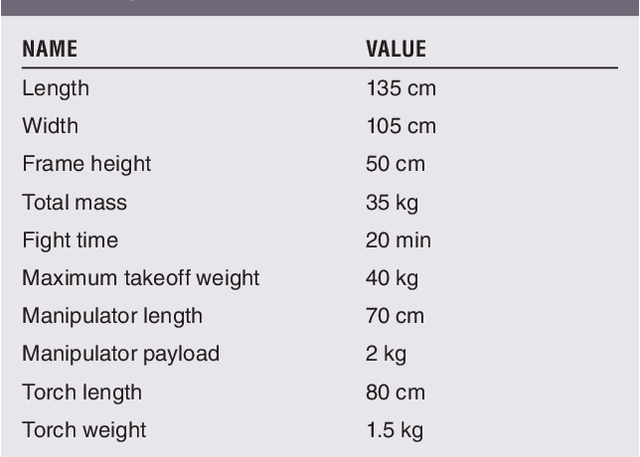
Torch relay is an important tradition of the Olympics and heralds the start of the Games. Robots applied in the torch relay activity can not only demonstrate the technological capability of humans to the world but also provide a sight of human lives with robots in the future. This article presents an aerial manipulator designed for the robot-to-robot torch relay task of the Beijing 2022 Winter Olympics. This aerial manipulator system is composed of a quadrotor, a 3 DoF (Degree of Freedom) manipulator, and a monocular camera. This article primarily describes the system design and system control scheme of the aerial manipulator. The experimental results demonstrate that it can complete robot-to-robot torch relay task under the guidance of vision in the ice and snow field.
Guided Time-optimal Model Predictive Control of a Multi-rotor
Jan 08, 2024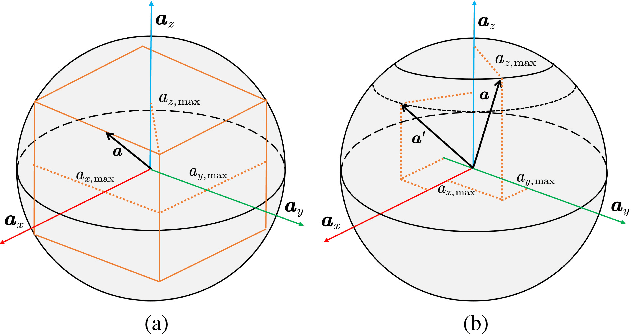

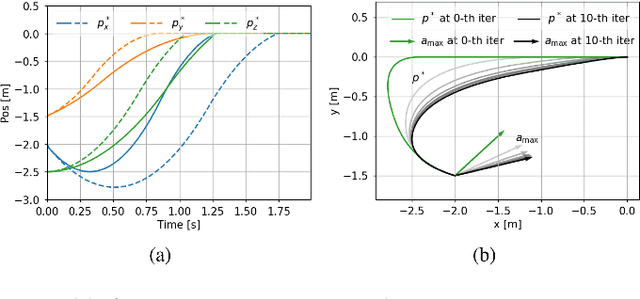
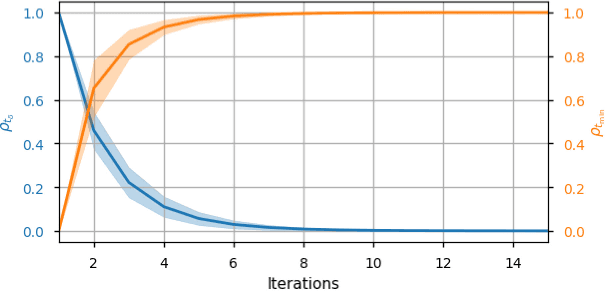
Time-optimal control of a multi-rotor remains an open problem due to the under-actuation and nonlinearity of its dynamics, which make it difficult to solve this problem directly. In this paper, the time-optimal control problem of the multi-rotor is studied. Firstly, a thrust limit optimal decomposition method is proposed, which can reasonably decompose the limited thrust into three directions according to the current state and the target state. As a result, the thrust limit constraint is decomposed as a linear constraint. With the linear constraint and decoupled dynamics, a time-optimal guidance trajectory can be obtained. Then, a cost function is defined based on the time-optimal guidance trajectory, which has a quadratic form and can be used to evaluate the time-optimal performance of the system outputs. Finally, based on the cost function, the time-optimal control problem is reformulated as an MPC (Model Predictive Control) problem. The experimental results demonstrate the feasibility and validity of the proposed methods.
* 6 pages, 5 figures
Long-Range Grouping Transformer for Multi-View 3D Reconstruction
Aug 17, 2023Nowadays, transformer networks have demonstrated superior performance in many computer vision tasks. In a multi-view 3D reconstruction algorithm following this paradigm, self-attention processing has to deal with intricate image tokens including massive information when facing heavy amounts of view input. The curse of information content leads to the extreme difficulty of model learning. To alleviate this problem, recent methods compress the token number representing each view or discard the attention operations between the tokens from different views. Obviously, they give a negative impact on performance. Therefore, we propose long-range grouping attention (LGA) based on the divide-and-conquer principle. Tokens from all views are grouped for separate attention operations. The tokens in each group are sampled from all views and can provide macro representation for the resided view. The richness of feature learning is guaranteed by the diversity among different groups. An effective and efficient encoder can be established which connects inter-view features using LGA and extract intra-view features using the standard self-attention layer. Moreover, a novel progressive upsampling decoder is also designed for voxel generation with relatively high resolution. Hinging on the above, we construct a powerful transformer-based network, called LRGT. Experimental results on ShapeNet verify our method achieves SOTA accuracy in multi-view reconstruction. Code will be available at https://github.com/LiyingCV/Long-Range-Grouping-Transformer.