 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMIFormer: Mining the Correlations between Similar Tokens for Multi-View 3D Reconstruction
Feb 27, 2023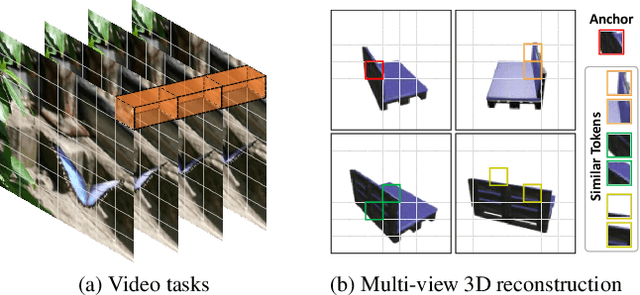
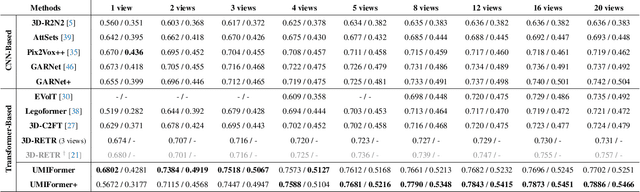
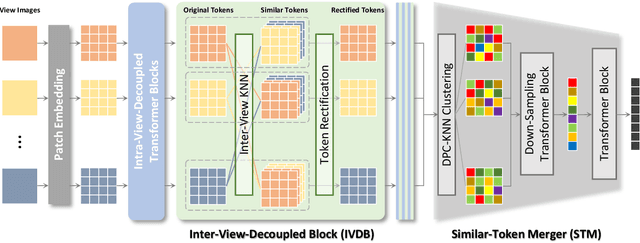
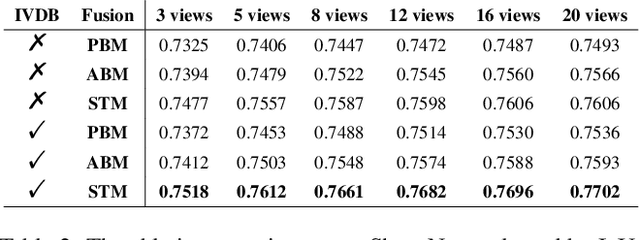
In recent years, many video tasks have achieved breakthroughs by utilizing the vision transformer and establishing spatial-temporal decoupling for feature extraction. Although multi-view 3D reconstruction also faces multiple images as input, it cannot immediately inherit their success due to completely ambiguous associations between unordered views. There is not usable prior relationship, which is similar to the temporally-coherence property in a video. To solve this problem, we propose a novel transformer network for Unordered Multiple Images (UMIFormer). It exploits transformer blocks for decoupled intra-view encoding and designed blocks for token rectification that mine the correlation between similar tokens from different views to achieve decoupled inter-view encoding. Afterward, all tokens acquired from various branches are compressed into a fixed-size compact representation while preserving rich information for reconstruction by leveraging the similarities between tokens. We empirically demonstrate on ShapeNet and confirm that our decoupled learning method is adaptable for unordered multiple images. Meanwhile, the experiments also verify our model outperforms existing SOTA methods by a large margin.
GARNet: Global-Aware Multi-View 3D Reconstruction Network and the Cost-Performance Tradeoff
Nov 04, 2022Deep learning technology has made great progress in multi-view 3D reconstruction tasks. At present, most mainstream solutions establish the mapping between views and shape of an object by assembling the networks of 2D encoder and 3D decoder as the basic structure while they adopt different approaches to obtain aggregation of features from several views. Among them, the methods using attention-based fusion perform better and more stable than the others, however, they still have an obvious shortcoming -- the strong independence of each view during predicting the weights for merging leads to a lack of adaption of the global state. In this paper, we propose a global-aware attention-based fusion approach that builds the correlation between each branch and the global to provide a comprehensive foundation for weights inference. In order to enhance the ability of the network, we introduce a novel loss function to supervise the shape overall and propose a dynamic two-stage training strategy that can effectively adapt to all reconstructors with attention-based fusion. Experiments on ShapeNet verify that our method outperforms existing SOTA methods while the amount of parameters is far less than the same type of algorithm, Pix2Vox++. Furthermore, we propose a view-reduction method based on maximizing diversity and discuss the cost-performance tradeoff of our model to achieve a better performance when facing heavy input amount and limited computational cost.