 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFutureX-Pro: Extending Future Prediction to High-Value Vertical Domains
Jan 18, 2026Building upon FutureX, which established a live benchmark for general-purpose future prediction, this report introduces FutureX-Pro, including FutureX-Finance, FutureX-Retail, FutureX-PublicHealth, FutureX-NaturalDisaster, and FutureX-Search. These together form a specialized framework extending agentic future prediction to high-value vertical domains. While generalist agents demonstrate proficiency in open-domain search, their reliability in capital-intensive and safety-critical sectors remains under-explored. FutureX-Pro targets four economically and socially pivotal verticals: Finance, Retail, Public Health, and Natural Disaster. We benchmark agentic Large Language Models (LLMs) on entry-level yet foundational prediction tasks -- ranging from forecasting market indicators and supply chain demands to tracking epidemic trends and natural disasters. By adapting the contamination-free, live-evaluation pipeline of FutureX, we assess whether current State-of-the-Art (SOTA) agentic LLMs possess the domain grounding necessary for industrial deployment. Our findings reveal the performance gap between generalist reasoning and the precision required for high-value vertical applications.
FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning
Sep 16, 2025



Search has emerged as core infrastructure for LLM-based agents and is widely viewed as critical on the path toward more general intelligence. Finance is a particularly demanding proving ground: analysts routinely conduct complex, multi-step searches over time-sensitive, domain-specific data, making it ideal for assessing both search proficiency and knowledge-grounded reasoning. Yet no existing open financial datasets evaluate data searching capability of end-to-end agents, largely because constructing realistic, complicated tasks requires deep financial expertise and time-sensitive data is hard to evaluate. We present FinSearchComp, the first fully open-source agent benchmark for realistic, open-domain financial search and reasoning. FinSearchComp comprises three tasks -- Time-Sensitive Data Fetching, Simple Historical Lookup, and Complex Historical Investigation -- closely reproduce real-world financial analyst workflows. To ensure difficulty and reliability, we engage 70 professional financial experts for annotation and implement a rigorous multi-stage quality-assurance pipeline. The benchmark includes 635 questions spanning global and Greater China markets, and we evaluate 21 models (products) on it. Grok 4 (web) tops the global subset, approaching expert-level accuracy. DouBao (web) leads on the Greater China subset. Experimental analyses show that equipping agents with web search and financial plugins substantially improves results on FinSearchComp, and the country origin of models and tools impact performance significantly.By aligning with realistic analyst tasks and providing end-to-end evaluation, FinSearchComp offers a professional, high-difficulty testbed for complex financial search and reasoning.
Not All Frame Features Are Equal: Video-to-4D Generation via Decoupling Dynamic-Static Features
Feb 12, 2025Recently, the generation of dynamic 3D objects from a video has shown impressive results. Existing methods directly optimize Gaussians using whole information in frames. However, when dynamic regions are interwoven with static regions within frames, particularly if the static regions account for a large proportion, existing methods often overlook information in dynamic regions and are prone to overfitting on static regions. This leads to producing results with blurry textures. We consider that decoupling dynamic-static features to enhance dynamic representations can alleviate this issue. Thus, we propose a dynamic-static feature decoupling module (DSFD). Along temporal axes, it regards the portions of current frame features that possess significant differences relative to reference frame features as dynamic features. Conversely, the remaining parts are the static features. Then, we acquire decoupled features driven by dynamic features and current frame features. Moreover, to further enhance the dynamic representation of decoupled features from different viewpoints and ensure accurate motion prediction, we design a temporal-spatial similarity fusion module (TSSF). Along spatial axes, it adaptively selects a similar information of dynamic regions. Hinging on the above, we construct a novel approach, DS4D. Experimental results verify our method achieves state-of-the-art (SOTA) results in video-to-4D. In addition, the experiments on a real-world scenario dataset demonstrate its effectiveness on the 4D scene. Our code will be publicly available.
Long-Range Grouping Transformer for Multi-View 3D Reconstruction
Aug 17, 2023Nowadays, transformer networks have demonstrated superior performance in many computer vision tasks. In a multi-view 3D reconstruction algorithm following this paradigm, self-attention processing has to deal with intricate image tokens including massive information when facing heavy amounts of view input. The curse of information content leads to the extreme difficulty of model learning. To alleviate this problem, recent methods compress the token number representing each view or discard the attention operations between the tokens from different views. Obviously, they give a negative impact on performance. Therefore, we propose long-range grouping attention (LGA) based on the divide-and-conquer principle. Tokens from all views are grouped for separate attention operations. The tokens in each group are sampled from all views and can provide macro representation for the resided view. The richness of feature learning is guaranteed by the diversity among different groups. An effective and efficient encoder can be established which connects inter-view features using LGA and extract intra-view features using the standard self-attention layer. Moreover, a novel progressive upsampling decoder is also designed for voxel generation with relatively high resolution. Hinging on the above, we construct a powerful transformer-based network, called LRGT. Experimental results on ShapeNet verify our method achieves SOTA accuracy in multi-view reconstruction. Code will be available at https://github.com/LiyingCV/Long-Range-Grouping-Transformer.
UMIFormer: Mining the Correlations between Similar Tokens for Multi-View 3D Reconstruction
Feb 27, 2023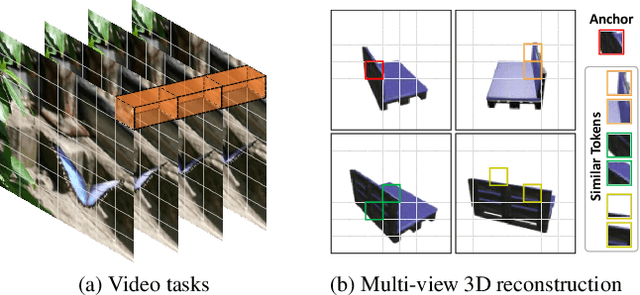
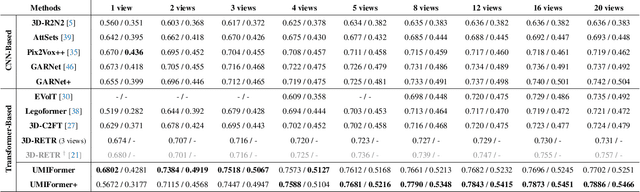
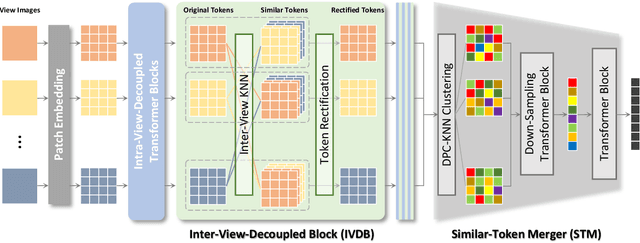
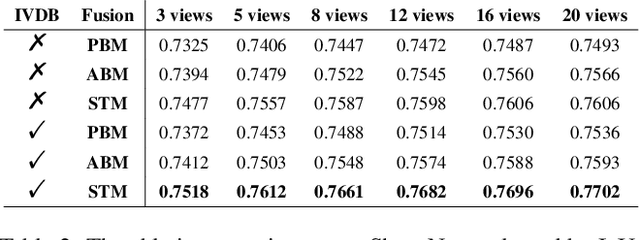
In recent years, many video tasks have achieved breakthroughs by utilizing the vision transformer and establishing spatial-temporal decoupling for feature extraction. Although multi-view 3D reconstruction also faces multiple images as input, it cannot immediately inherit their success due to completely ambiguous associations between unordered views. There is not usable prior relationship, which is similar to the temporally-coherence property in a video. To solve this problem, we propose a novel transformer network for Unordered Multiple Images (UMIFormer). It exploits transformer blocks for decoupled intra-view encoding and designed blocks for token rectification that mine the correlation between similar tokens from different views to achieve decoupled inter-view encoding. Afterward, all tokens acquired from various branches are compressed into a fixed-size compact representation while preserving rich information for reconstruction by leveraging the similarities between tokens. We empirically demonstrate on ShapeNet and confirm that our decoupled learning method is adaptable for unordered multiple images. Meanwhile, the experiments also verify our model outperforms existing SOTA methods by a large margin.
GARNet: Global-Aware Multi-View 3D Reconstruction Network and the Cost-Performance Tradeoff
Nov 04, 2022Deep learning technology has made great progress in multi-view 3D reconstruction tasks. At present, most mainstream solutions establish the mapping between views and shape of an object by assembling the networks of 2D encoder and 3D decoder as the basic structure while they adopt different approaches to obtain aggregation of features from several views. Among them, the methods using attention-based fusion perform better and more stable than the others, however, they still have an obvious shortcoming -- the strong independence of each view during predicting the weights for merging leads to a lack of adaption of the global state. In this paper, we propose a global-aware attention-based fusion approach that builds the correlation between each branch and the global to provide a comprehensive foundation for weights inference. In order to enhance the ability of the network, we introduce a novel loss function to supervise the shape overall and propose a dynamic two-stage training strategy that can effectively adapt to all reconstructors with attention-based fusion. Experiments on ShapeNet verify that our method outperforms existing SOTA methods while the amount of parameters is far less than the same type of algorithm, Pix2Vox++. Furthermore, we propose a view-reduction method based on maximizing diversity and discuss the cost-performance tradeoff of our model to achieve a better performance when facing heavy input amount and limited computational cost.