 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Derivation and Elimination: Audio Visual Segmentation with Enhanced Audio Semantics
Mar 17, 2025Sound-guided object segmentation has drawn considerable attention for its potential to enhance multimodal perception. Previous methods primarily focus on developing advanced architectures to facilitate effective audio-visual interactions, without fully addressing the inherent challenges posed by audio natures, \emph{\ie}, (1) feature confusion due to the overlapping nature of audio signals, and (2) audio-visual matching difficulty from the varied sounds produced by the same object. To address these challenges, we propose Dynamic Derivation and Elimination (DDESeg): a novel audio-visual segmentation framework. Specifically, to mitigate feature confusion, DDESeg reconstructs the semantic content of the mixed audio signal by enriching the distinct semantic information of each individual source, deriving representations that preserve the unique characteristics of each sound. To reduce the matching difficulty, we introduce a discriminative feature learning module, which enhances the semantic distinctiveness of generated audio representations. Considering that not all derived audio representations directly correspond to visual features (e.g., off-screen sounds), we propose a dynamic elimination module to filter out non-matching elements. This module facilitates targeted interaction between sounding regions and relevant audio semantics. By scoring the interacted features, we identify and filter out irrelevant audio information, ensuring accurate audio-visual alignment. Comprehensive experiments demonstrate that our framework achieves superior performance in AVS datasets.
Robust Audio-Visual Segmentation via Audio-Guided Visual Convergent Alignment
Mar 17, 2025Accurately localizing audible objects based on audio-visual cues is the core objective of audio-visual segmentation. Most previous methods emphasize spatial or temporal multi-modal modeling, yet overlook challenges from ambiguous audio-visual correspondences such as nearby visually similar but acoustically different objects and frequent shifts in objects' sounding status. Consequently, they may struggle to reliably correlate audio and visual cues, leading to over- or under-segmentation. To address these limitations, we propose a novel framework with two primary components: an audio-guided modality alignment (AMA) module and an uncertainty estimation (UE) module. Instead of indiscriminately correlating audio-visual cues through a global attention mechanism, AMA performs audio-visual interactions within multiple groups and consolidates group features into compact representations based on their responsiveness to audio cues, effectively directing the model's attention to audio-relevant areas. Leveraging contrastive learning, AMA further distinguishes sounding regions from silent areas by treating features with strong audio responses as positive samples and weaker responses as negatives. Additionally, UE integrates spatial and temporal information to identify high-uncertainty regions caused by frequent changes in sound state, reducing prediction errors by lowering confidence in these areas. Experimental results demonstrate that our approach achieves superior accuracy compared to existing state-of-the-art methods, particularly in challenging scenarios where traditional approaches struggle to maintain reliable segmentation.
7ABAW-Compound Expression Recognition via Curriculum Learning
Mar 11, 2025With the advent of deep learning, expression recognition has made significant advancements. However, due to the limited availability of annotated compound expression datasets and the subtle variations of compound expressions, Compound Emotion Recognition (CE) still holds considerable potential for exploration. To advance this task, the 7th Affective Behavior Analysis in-the-wild (ABAW) competition introduces the Compound Expression Challenge based on C-EXPR-DB, a limited dataset without labels. In this paper, we present a curriculum learning-based framework that initially trains the model on single-expression tasks and subsequently incorporates multi-expression data. This design ensures that our model first masters the fundamental features of basic expressions before being exposed to the complexities of compound emotions. Specifically, our designs can be summarized as follows: 1) Single-Expression Pre-training: The model is first trained on datasets containing single expressions to learn the foundational facial features associated with basic emotions. 2) Dynamic Compound Expression Generation: Given the scarcity of annotated compound expression datasets, we employ CutMix and Mixup techniques on the original single-expression images to create hybrid images exhibiting characteristics of multiple basic emotions. 3) Incremental Multi-Expression Integration: After performing well on single-expression tasks, the model is progressively exposed to multi-expression data, allowing the model to adapt to the complexity and variability of compound expressions. The official results indicate that our method achieves the \textbf{best} performance in this competition track with an F-score of 0.6063. Our code is released at https://github.com/YenanLiu/ABAW7th.
EasyCraft: A Robust and Efficient Framework for Automatic Avatar Crafting
Mar 03, 2025Character customization, or 'face crafting,' is a vital feature in role-playing games (RPGs), enhancing player engagement by enabling the creation of personalized avatars. Existing automated methods often struggle with generalizability across diverse game engines due to their reliance on the intermediate constraints of specific image domain and typically support only one type of input, either text or image. To overcome these challenges, we introduce EasyCraft, an innovative end-to-end feedforward framework that automates character crafting by uniquely supporting both text and image inputs. Our approach employs a translator capable of converting facial images of any style into crafting parameters. We first establish a unified feature distribution in the translator's image encoder through self-supervised learning on a large-scale dataset, enabling photos of any style to be embedded into a unified feature representation. Subsequently, we map this unified feature distribution to crafting parameters specific to a game engine, a process that can be easily adapted to most game engines and thus enhances EasyCraft's generalizability. By integrating text-to-image techniques with our translator, EasyCraft also facilitates precise, text-based character crafting. EasyCraft's ability to integrate diverse inputs significantly enhances the versatility and accuracy of avatar creation. Extensive experiments on two RPG games demonstrate the effectiveness of our method, achieving state-of-the-art results and facilitating adaptability across various avatar engines.
Multimodal Latent Diffusion Model for Complex Sewing Pattern Generation
Dec 19, 2024



Generating sewing patterns in garment design is receiving increasing attention due to its CG-friendly and flexible-editing nature. Previous sewing pattern generation methods have been able to produce exquisite clothing, but struggle to design complex garments with detailed control. To address these issues, we propose SewingLDM, a multi-modal generative model that generates sewing patterns controlled by text prompts, body shapes, and garment sketches. Initially, we extend the original vector of sewing patterns into a more comprehensive representation to cover more intricate details and then compress them into a compact latent space. To learn the sewing pattern distribution in the latent space, we design a two-step training strategy to inject the multi-modal conditions, \ie, body shapes, text prompts, and garment sketches, into a diffusion model, ensuring the generated garments are body-suited and detail-controlled. Comprehensive qualitative and quantitative experiments show the effectiveness of our proposed method, significantly surpassing previous approaches in terms of complex garment design and various body adaptability. Our project page: https://shengqiliu1.github.io/SewingLDM.
Revealing Directions for Text-guided 3D Face Editing
Oct 07, 2024



3D face editing is a significant task in multimedia, aimed at the manipulation of 3D face models across various control signals. The success of 3D-aware GAN provides expressive 3D models learned from 2D single-view images only, encouraging researchers to discover semantic editing directions in its latent space. However, previous methods face challenges in balancing quality, efficiency, and generalization. To solve the problem, we explore the possibility of introducing the strength of diffusion model into 3D-aware GANs. In this paper, we present Face Clan, a fast and text-general approach for generating and manipulating 3D faces based on arbitrary attribute descriptions. To achieve disentangled editing, we propose to diffuse on the latent space under a pair of opposite prompts to estimate the mask indicating the region of interest on latent codes. Based on the mask, we then apply denoising to the masked latent codes to reveal the editing direction. Our method offers a precisely controllable manipulation method, allowing users to intuitively customize regions of interest with the text description. Experiments demonstrate the effectiveness and generalization of our Face Clan for various pre-trained GANs. It offers an intuitive and wide application for text-guided face editing that contributes to the landscape of multimedia content creation.
Affective Behaviour Analysis via Progressive Learning
Jul 26, 2024



Affective Behavior Analysis aims to develop emotionally intelligent technology that can recognize and respond to human emotions. To advance this, the 7th Affective Behavior Analysis in-the-wild (ABAW) competition establishes two tracks: i.e., the Multi-task Learning (MTL) Challenge and the Compound Expression (CE) challenge based on Aff-Wild2 and C-EXPR-DB datasets. In this paper, we present our methods and experimental results for the two competition tracks. Specifically, it can be summarized in the following four aspects: 1) To attain high-quality facial features, we train a Masked-Auto Encoder in a self-supervised manner. 2) We devise a temporal convergence module to capture the temporal information between video frames and explore the impact of window size and sequence length on each sub-task. 3) To facilitate the joint optimization of various sub-tasks, we explore the impact of sub-task joint training and feature fusion from individual tasks on each task performance improvement. 4) We utilize curriculum learning to transition the model from recognizing single expressions to recognizing compound expressions, thereby improving the accuracy of compound expression recognition. Extensive experiments demonstrate the superiority of our designs.
HIMO: A New Benchmark for Full-Body Human Interacting with Multiple Objects
Jul 17, 2024



Generating human-object interactions (HOIs) is critical with the tremendous advances of digital avatars. Existing datasets are typically limited to humans interacting with a single object while neglecting the ubiquitous manipulation of multiple objects. Thus, we propose HIMO, a large-scale MoCap dataset of full-body human interacting with multiple objects, containing 3.3K 4D HOI sequences and 4.08M 3D HOI frames. We also annotate HIMO with detailed textual descriptions and temporal segments, benchmarking two novel tasks of HOI synthesis conditioned on either the whole text prompt or the segmented text prompts as fine-grained timeline control. To address these novel tasks, we propose a dual-branch conditional diffusion model with a mutual interaction module for HOI synthesis. Besides, an auto-regressive generation pipeline is also designed to obtain smooth transitions between HOI segments. Experimental results demonstrate the generalization ability to unseen object geometries and temporal compositions.
Affective Behaviour Analysis via Integrating Multi-Modal Knowledge
Mar 16, 2024



Affective Behavior Analysis aims to facilitate technology emotionally smart, creating a world where devices can understand and react to our emotions as humans do. To comprehensively evaluate the authenticity and applicability of emotional behavior analysis techniques in natural environments, the 6th competition on Affective Behavior Analysis in-the-wild (ABAW) utilizes the Aff-Wild2, Hume-Vidmimic2, and C-EXPR-DB datasets to set up five competitive tracks, i.e., Valence-Arousal (VA) Estimation, Expression (EXPR) Recognition, Action Unit (AU) Detection, Compound Expression (CE) Recognition, and Emotional Mimicry Intensity (EMI) Estimation. In this paper, we present our method designs for the five tasks. Specifically, our design mainly includes three aspects: 1) Utilizing a transformer-based feature fusion module to fully integrate emotional information provided by audio signals, visual images, and transcripts, offering high-quality expression features for the downstream tasks. 2) To achieve high-quality facial feature representations, we employ Masked-Auto Encoder as the visual features extraction model and fine-tune it with our facial dataset. 3) Considering the complexity of the video collection scenes, we conduct a more detailed dataset division based on scene characteristics and train the classifier for each scene. Extensive experiments demonstrate the superiority of our designs.
Text-Guided 3D Face Synthesis -- From Generation to Editing
Dec 01, 2023


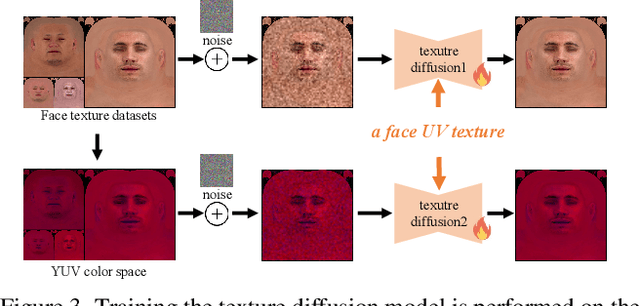
Text-guided 3D face synthesis has achieved remarkable results by leveraging text-to-image (T2I) diffusion models. However, most existing works focus solely on the direct generation, ignoring the editing, restricting them from synthesizing customized 3D faces through iterative adjustments. In this paper, we propose a unified text-guided framework from face generation to editing. In the generation stage, we propose a geometry-texture decoupled generation to mitigate the loss of geometric details caused by coupling. Besides, decoupling enables us to utilize the generated geometry as a condition for texture generation, yielding highly geometry-texture aligned results. We further employ a fine-tuned texture diffusion model to enhance texture quality in both RGB and YUV space. In the editing stage, we first employ a pre-trained diffusion model to update facial geometry or texture based on the texts. To enable sequential editing, we introduce a UV domain consistency preservation regularization, preventing unintentional changes to irrelevant facial attributes. Besides, we propose a self-guided consistency weight strategy to improve editing efficacy while preserving consistency. Through comprehensive experiments, we showcase our method's superiority in face synthesis. Project page: https://faceg2e.github.io/.