 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyCraft: A Robust and Efficient Framework for Automatic Avatar Crafting
Mar 03, 2025Character customization, or 'face crafting,' is a vital feature in role-playing games (RPGs), enhancing player engagement by enabling the creation of personalized avatars. Existing automated methods often struggle with generalizability across diverse game engines due to their reliance on the intermediate constraints of specific image domain and typically support only one type of input, either text or image. To overcome these challenges, we introduce EasyCraft, an innovative end-to-end feedforward framework that automates character crafting by uniquely supporting both text and image inputs. Our approach employs a translator capable of converting facial images of any style into crafting parameters. We first establish a unified feature distribution in the translator's image encoder through self-supervised learning on a large-scale dataset, enabling photos of any style to be embedded into a unified feature representation. Subsequently, we map this unified feature distribution to crafting parameters specific to a game engine, a process that can be easily adapted to most game engines and thus enhances EasyCraft's generalizability. By integrating text-to-image techniques with our translator, EasyCraft also facilitates precise, text-based character crafting. EasyCraft's ability to integrate diverse inputs significantly enhances the versatility and accuracy of avatar creation. Extensive experiments on two RPG games demonstrate the effectiveness of our method, achieving state-of-the-art results and facilitating adaptability across various avatar engines.
StyleTalk++: A Unified Framework for Controlling the Speaking Styles of Talking Heads
Sep 14, 2024



Individuals have unique facial expression and head pose styles that reflect their personalized speaking styles. Existing one-shot talking head methods cannot capture such personalized characteristics and therefore fail to produce diverse speaking styles in the final videos. To address this challenge, we propose a one-shot style-controllable talking face generation method that can obtain speaking styles from reference speaking videos and drive the one-shot portrait to speak with the reference speaking styles and another piece of audio. Our method aims to synthesize the style-controllable coefficients of a 3D Morphable Model (3DMM), including facial expressions and head movements, in a unified framework. Specifically, the proposed framework first leverages a style encoder to extract the desired speaking styles from the reference videos and transform them into style codes. Then, the framework uses a style-aware decoder to synthesize the coefficients of 3DMM from the audio input and style codes. During decoding, our framework adopts a two-branch architecture, which generates the stylized facial expression coefficients and stylized head movement coefficients, respectively. After obtaining the coefficients of 3DMM, an image renderer renders the expression coefficients into a specific person's talking-head video. Extensive experiments demonstrate that our method generates visually authentic talking head videos with diverse speaking styles from only one portrait image and an audio clip.
TalkCLIP: Talking Head Generation with Text-Guided Expressive Speaking Styles
Apr 01, 2023In order to produce facial-expression-specified talking head videos, previous audio-driven one-shot talking head methods need to use a reference video with a matching speaking style (i.e., facial expressions). However, finding videos with a desired style may not be easy, potentially restricting their application. In this work, we propose an expression-controllable one-shot talking head method, dubbed TalkCLIP, where the expression in a speech is specified by the natural language. This would significantly ease the difficulty of searching for a video with a desired speaking style. Here, we first construct a text-video paired talking head dataset, in which each video has alternative prompt-alike descriptions. Specifically, our descriptions involve coarse-level emotion annotations and facial action unit (AU) based fine-grained annotations. Then, we introduce a CLIP-based style encoder that first projects natural language descriptions to the CLIP text embedding space and then aligns the textual embeddings to the representations of speaking styles. As extensive textual knowledge has been encoded by CLIP, our method can even generalize to infer a speaking style whose description has not been seen during training. Extensive experiments demonstrate that our method achieves the advanced capability of generating photo-realistic talking heads with vivid facial expressions guided by text descriptions.
StyleTalk: One-shot Talking Head Generation with Controllable Speaking Styles
Jan 03, 2023



Different people speak with diverse personalized speaking styles. Although existing one-shot talking head methods have made significant progress in lip sync, natural facial expressions, and stable head motions, they still cannot generate diverse speaking styles in the final talking head videos. To tackle this problem, we propose a one-shot style-controllable talking face generation framework. In a nutshell, we aim to attain a speaking style from an arbitrary reference speaking video and then drive the one-shot portrait to speak with the reference speaking style and another piece of audio. Specifically, we first develop a style encoder to extract dynamic facial motion patterns of a style reference video and then encode them into a style code. Afterward, we introduce a style-controllable decoder to synthesize stylized facial animations from the speech content and style code. In order to integrate the reference speaking style into generated videos, we design a style-aware adaptive transformer, which enables the encoded style code to adjust the weights of the feed-forward layers accordingly. Thanks to the style-aware adaptation mechanism, the reference speaking style can be better embedded into synthesized videos during decoding. Extensive experiments demonstrate that our method is capable of generating talking head videos with diverse speaking styles from only one portrait image and an audio clip while achieving authentic visual effects. Project Page: https://github.com/FuxiVirtualHuman/styletalk.
FlowFace: Semantic Flow-guided Shape-aware Face Swapping
Dec 06, 2022In this work, we propose a semantic flow-guided two-stage framework for shape-aware face swapping, namely FlowFace. Unlike most previous methods that focus on transferring the source inner facial features but neglect facial contours, our FlowFace can transfer both of them to a target face, thus leading to more realistic face swapping. Concretely, our FlowFace consists of a face reshaping network and a face swapping network. The face reshaping network addresses the shape outline differences between the source and target faces. It first estimates a semantic flow (i.e., face shape differences) between the source and the target face, and then explicitly warps the target face shape with the estimated semantic flow. After reshaping, the face swapping network generates inner facial features that exhibit the identity of the source face. We employ a pre-trained face masked autoencoder (MAE) to extract facial features from both the source face and the target face. In contrast to previous methods that use identity embedding to preserve identity information, the features extracted by our encoder can better capture facial appearances and identity information. Then, we develop a cross-attention fusion module to adaptively fuse inner facial features from the source face with the target facial attributes, thus leading to better identity preservation. Extensive quantitative and qualitative experiments on in-the-wild faces demonstrate that our FlowFace outperforms the state-of-the-art significantly.
Transformer-based Multimodal Information Fusion for Facial Expression Analysis
Mar 23, 2022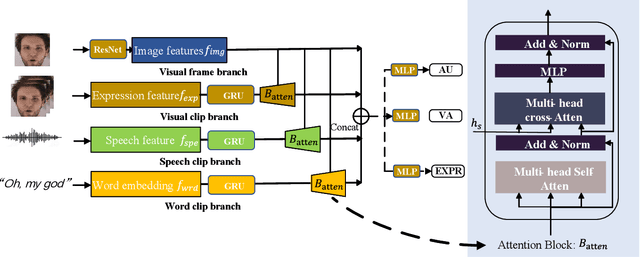
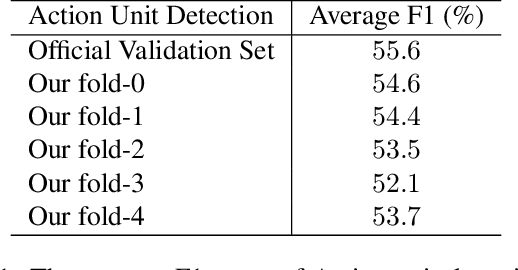

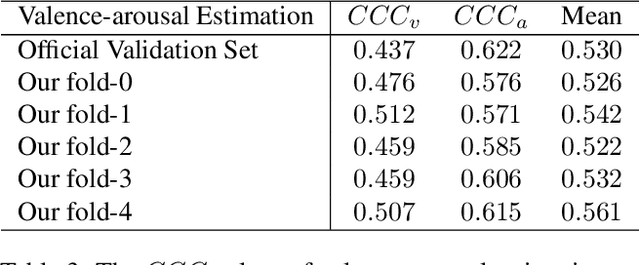
Facial expression analysis has been a crucial research problem in the computer vision area. With the recent development of deep learning techniques and large-scale in-the-wild annotated datasets, facial expression analysis is now aimed at challenges in real world settings. In this paper, we introduce our submission to CVPR2022 Competition on Affective Behavior Analysis in-the-wild (ABAW) that defines four competition tasks, including expression classification, action unit detection, valence-arousal estimation, and a multi-task-learning. The available multimodal information consist of spoken words, speech prosody, and visual expression in videos. Our work proposes four unified transformer-based network frameworks to create the fusion of the above multimodal information. The preliminary results on the official Aff-Wild2 dataset are reported and demonstrate the effectiveness of our proposed method.
One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning
Dec 06, 2021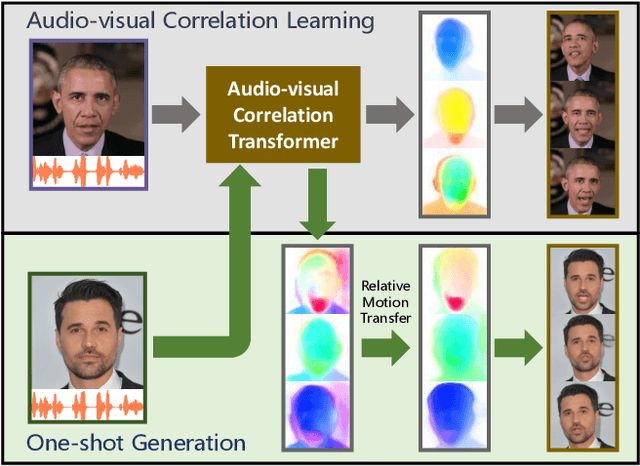
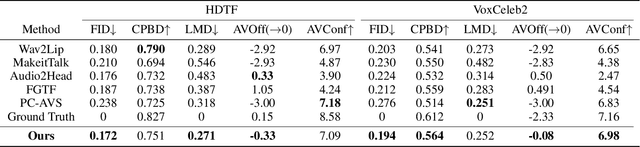
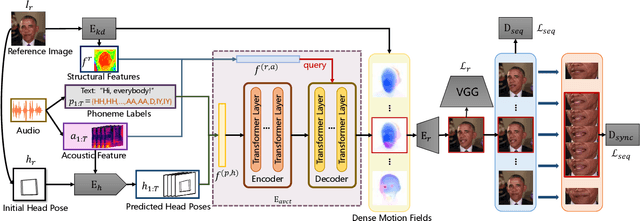
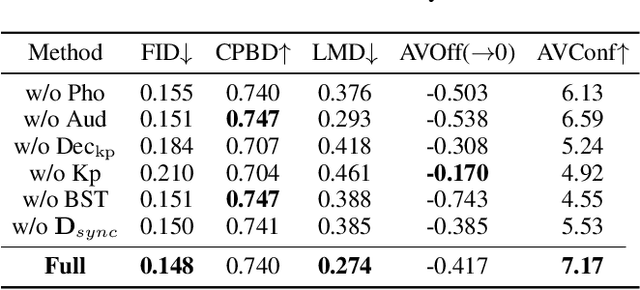
Audio-driven one-shot talking face generation methods are usually trained on video resources of various persons. However, their created videos often suffer unnatural mouth shapes and asynchronous lips because those methods struggle to learn a consistent speech style from different speakers. We observe that it would be much easier to learn a consistent speech style from a specific speaker, which leads to authentic mouth movements. Hence, we propose a novel one-shot talking face generation framework by exploring consistent correlations between audio and visual motions from a specific speaker and then transferring audio-driven motion fields to a reference image. Specifically, we develop an Audio-Visual Correlation Transformer (AVCT) that aims to infer talking motions represented by keypoint based dense motion fields from an input audio. In particular, considering audio may come from different identities in deployment, we incorporate phonemes to represent audio signals. In this manner, our AVCT can inherently generalize to audio spoken by other identities. Moreover, as face keypoints are used to represent speakers, AVCT is agnostic against appearances of the training speaker, and thus allows us to manipulate face images of different identities readily. Considering different face shapes lead to different motions, a motion field transfer module is exploited to reduce the audio-driven dense motion field gap between the training identity and the one-shot reference. Once we obtained the dense motion field of the reference image, we employ an image renderer to generate its talking face videos from an audio clip. Thanks to our learned consistent speaking style, our method generates authentic mouth shapes and vivid movements. Extensive experiments demonstrate that our synthesized videos outperform the state-of-the-art in terms of visual quality and lip-sync.
* Accepted by AAAI 2022
Audio2Head: Audio-driven One-shot Talking-head Generation with Natural Head Motion
Jul 20, 2021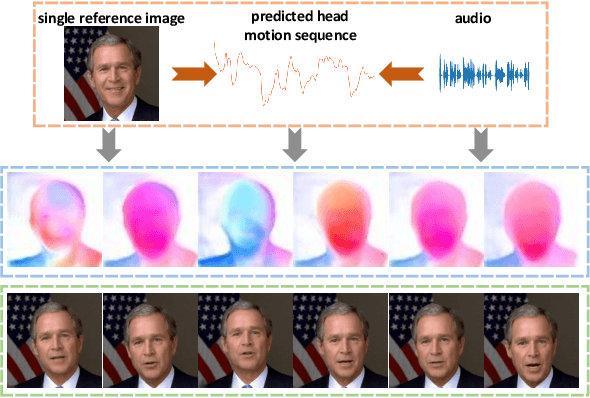
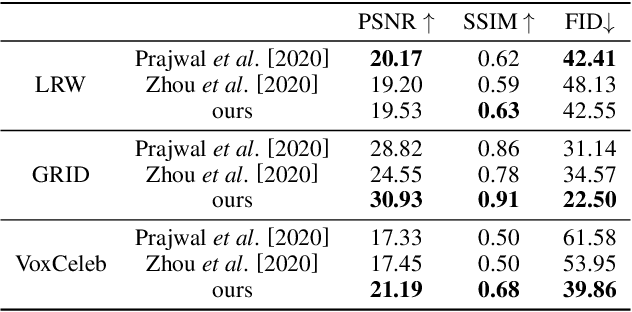
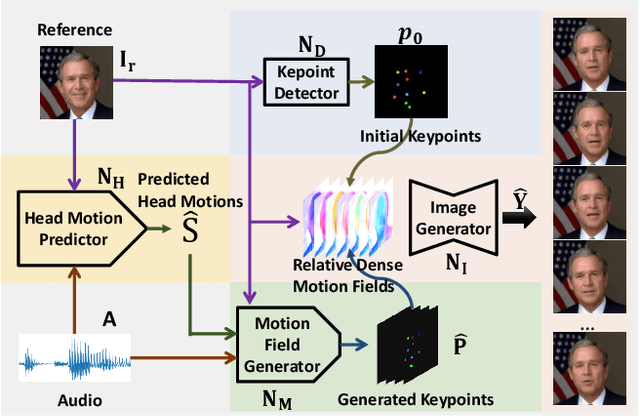

We propose an audio-driven talking-head method to generate photo-realistic talking-head videos from a single reference image. In this work, we tackle two key challenges: (i) producing natural head motions that match speech prosody, and (ii) maintaining the appearance of a speaker in a large head motion while stabilizing the non-face regions. We first design a head pose predictor by modeling rigid 6D head movements with a motion-aware recurrent neural network (RNN). In this way, the predicted head poses act as the low-frequency holistic movements of a talking head, thus allowing our latter network to focus on detailed facial movement generation. To depict the entire image motions arising from audio, we exploit a keypoint based dense motion field representation. Then, we develop a motion field generator to produce the dense motion fields from input audio, head poses, and a reference image. As this keypoint based representation models the motions of facial regions, head, and backgrounds integrally, our method can better constrain the spatial and temporal consistency of the generated videos. Finally, an image generation network is employed to render photo-realistic talking-head videos from the estimated keypoint based motion fields and the input reference image. Extensive experiments demonstrate that our method produces videos with plausible head motions, synchronized facial expressions, and stable backgrounds and outperforms the state-of-the-art.
Write-a-speaker: Text-based Emotional and Rhythmic Talking-head Generation
May 07, 2021
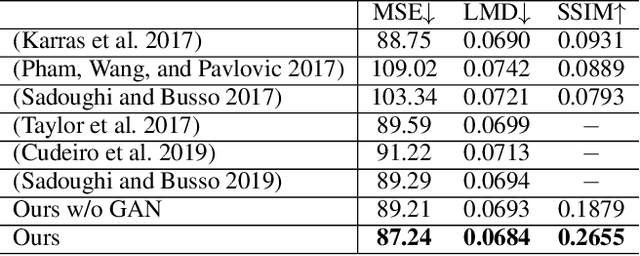
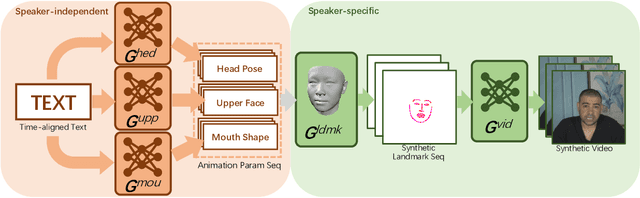
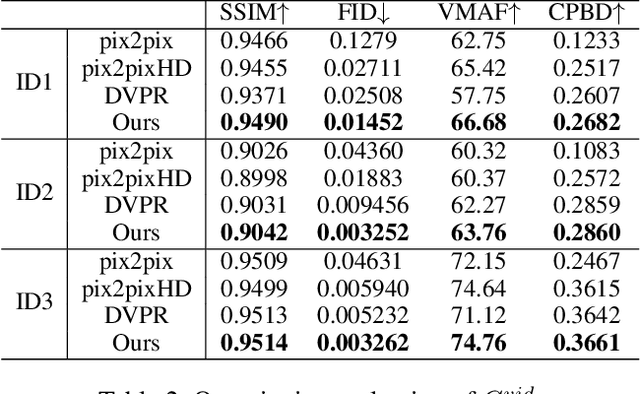
In this paper, we propose a novel text-based talking-head video generation framework that synthesizes high-fidelity facial expressions and head motions in accordance with contextual sentiments as well as speech rhythm and pauses. To be specific, our framework consists of a speaker-independent stage and a speaker-specific stage. In the speaker-independent stage, we design three parallel networks to generate animation parameters of the mouth, upper face, and head from texts, separately. In the speaker-specific stage, we present a 3D face model guided attention network to synthesize videos tailored for different individuals. It takes the animation parameters as input and exploits an attention mask to manipulate facial expression changes for the input individuals. Furthermore, to better establish authentic correspondences between visual motions (i.e., facial expression changes and head movements) and audios, we leverage a high-accuracy motion capture dataset instead of relying on long videos of specific individuals. After attaining the visual and audio correspondences, we can effectively train our network in an end-to-end fashion. Extensive experiments on qualitative and quantitative results demonstrate that our algorithm achieves high-quality photo-realistic talking-head videos including various facial expressions and head motions according to speech rhythms and outperforms the state-of-the-art.
Imbalance-XGBoost: Leveraging Weighted and Focal Losses for Binary Label-Imbalanced Classification with XGBoost
Aug 05, 2019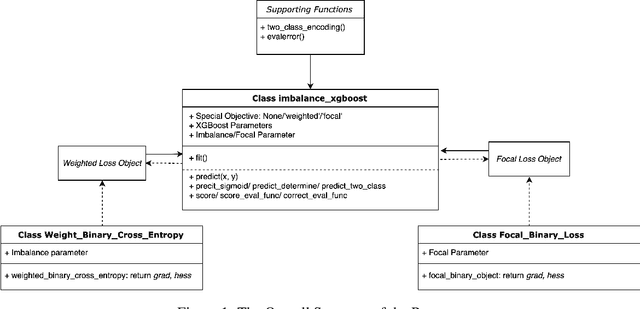

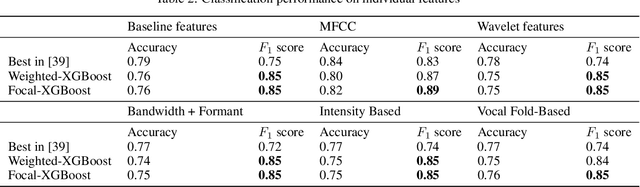
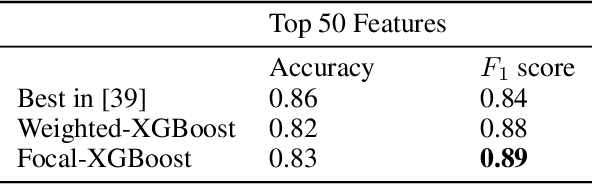
The paper presents Imbalance-XGBoost, a Python package that combines the powerful XGBoost software with weighted and focal losses to tackle binary label-imbalanced classification tasks. Though a small-scale program in terms of size, the package is, to the best of the authors' knowledge, the first of its kind which provides an integrated implementation for the two losses on XGBoost and brings a general-purpose extension on XGBoost for label-imbalanced scenarios. In this paper, the design and usage of the package are described with exemplar code listings, and its convenience to be integrated into Python-driven Machine Learning projects is illustrated. Furthermore, as the first- and second-order derivatives of the loss functions are essential for the implementations, the algebraic derivation is discussed and it can be deemed as a separate algorithmic contribution. The performances of the algorithms implemented in the package are empirically evaluated on Parkinson's disease classification data set, and multiple state-of-the-art performances have been observed. Given the scalable nature of XGBoost, the package has great potentials to be applied to real-life binary classification tasks, which are usually of large-scale and label-imbalanced.