 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFKAN: Time-Frequency KAN for Long-Term Time Series Forecasting
Jun 15, 2025Kolmogorov-Arnold Networks (KANs) are highly effective in long-term time series forecasting due to their ability to efficiently represent nonlinear relationships and exhibit local plasticity. However, prior research on KANs has predominantly focused on the time domain, neglecting the potential of the frequency domain. The frequency domain of time series data reveals recurring patterns and periodic behaviors, which complement the temporal information captured in the time domain. To address this gap, we explore the application of KANs in the frequency domain for long-term time series forecasting. By leveraging KANs' adaptive activation functions and their comprehensive representation of signals in the frequency domain, we can more effectively learn global dependencies and periodic patterns. To integrate information from both time and frequency domains, we propose the $\textbf{T}$ime-$\textbf{F}$requency KAN (TFKAN). TFKAN employs a dual-branch architecture that independently processes features from each domain, ensuring that the distinct characteristics of each domain are fully utilized without interference. Additionally, to account for the heterogeneity between domains, we introduce a dimension-adjustment strategy that selectively upscales only in the frequency domain, enhancing efficiency while capturing richer frequency information. Experimental results demonstrate that TFKAN consistently outperforms state-of-the-art (SOTA) methods across multiple datasets. The code is available at https://github.com/LcWave/TFKAN.
Empowering Economic Simulation for Massively Multiplayer Online Games through Generative Agent-Based Modeling
Jun 05, 2025Within the domain of Massively Multiplayer Online (MMO) economy research, Agent-Based Modeling (ABM) has emerged as a robust tool for analyzing game economics, evolving from rule-based agents to decision-making agents enhanced by reinforcement learning. Nevertheless, existing works encounter significant challenges when attempting to emulate human-like economic activities among agents, particularly regarding agent reliability, sociability, and interpretability. In this study, we take a preliminary step in introducing a novel approach using Large Language Models (LLMs) in MMO economy simulation. Leveraging LLMs' role-playing proficiency, generative capacity, and reasoning aptitude, we design LLM-driven agents with human-like decision-making and adaptability. These agents are equipped with the abilities of role-playing, perception, memory, and reasoning, addressing the aforementioned challenges effectively. Simulation experiments focusing on in-game economic activities demonstrate that LLM-empowered agents can promote emergent phenomena like role specialization and price fluctuations in line with market rules.
Ψ-Arena: Interactive Assessment and Optimization of LLM-based Psychological Counselors with Tripartite Feedback
May 06, 2025Large language models (LLMs) have shown promise in providing scalable mental health support, while evaluating their counseling capability remains crucial to ensure both efficacy and safety. Existing evaluations are limited by the static assessment that focuses on knowledge tests, the single perspective that centers on user experience, and the open-loop framework that lacks actionable feedback. To address these issues, we propose {\Psi}-Arena, an interactive framework for comprehensive assessment and optimization of LLM-based counselors, featuring three key characteristics: (1) Realistic arena interactions that simulate real-world counseling through multi-stage dialogues with psychologically profiled NPC clients, (2) Tripartite evaluation that integrates assessments from the client, counselor, and supervisor perspectives, and (3) Closed-loop optimization that iteratively improves LLM counselors using diagnostic feedback. Experiments across eight state-of-the-art LLMs show significant performance variations in different real-world scenarios and evaluation perspectives. Moreover, reflection-based optimization results in up to a 141% improvement in counseling performance. We hope PsychoArena provides a foundational resource for advancing reliable and human-aligned LLM applications in mental healthcare.
Crisp: Cognitive Restructuring of Negative Thoughts through Multi-turn Supportive Dialogues
Apr 24, 2025Cognitive Restructuring (CR) is a psychotherapeutic process aimed at identifying and restructuring an individual's negative thoughts, arising from mental health challenges, into more helpful and positive ones via multi-turn dialogues. Clinician shortage and stigma urge the development of human-LLM interactive psychotherapy for CR. Yet, existing efforts implement CR via simple text rewriting, fixed-pattern dialogues, or a one-shot CR workflow, failing to align with the psychotherapeutic process for effective CR. To address this gap, we propose CRDial, a novel framework for CR, which creates multi-turn dialogues with specifically designed identification and restructuring stages of negative thoughts, integrates sentence-level supportive conversation strategies, and adopts a multi-channel loop mechanism to enable iterative CR. With CRDial, we distill Crisp, a large-scale and high-quality bilingual dialogue dataset, from LLM. We then train Crispers, Crisp-based conversational LLMs for CR, at 7B and 14B scales. Extensive human studies show the superiority of Crispers in pointwise, pairwise, and intervention evaluations.
EasyCraft: A Robust and Efficient Framework for Automatic Avatar Crafting
Mar 03, 2025Character customization, or 'face crafting,' is a vital feature in role-playing games (RPGs), enhancing player engagement by enabling the creation of personalized avatars. Existing automated methods often struggle with generalizability across diverse game engines due to their reliance on the intermediate constraints of specific image domain and typically support only one type of input, either text or image. To overcome these challenges, we introduce EasyCraft, an innovative end-to-end feedforward framework that automates character crafting by uniquely supporting both text and image inputs. Our approach employs a translator capable of converting facial images of any style into crafting parameters. We first establish a unified feature distribution in the translator's image encoder through self-supervised learning on a large-scale dataset, enabling photos of any style to be embedded into a unified feature representation. Subsequently, we map this unified feature distribution to crafting parameters specific to a game engine, a process that can be easily adapted to most game engines and thus enhances EasyCraft's generalizability. By integrating text-to-image techniques with our translator, EasyCraft also facilitates precise, text-based character crafting. EasyCraft's ability to integrate diverse inputs significantly enhances the versatility and accuracy of avatar creation. Extensive experiments on two RPG games demonstrate the effectiveness of our method, achieving state-of-the-art results and facilitating adaptability across various avatar engines.
Digital Player: Evaluating Large Language Models based Human-like Agent in Games
Feb 28, 2025With the rapid advancement of Large Language Models (LLMs), LLM-based autonomous agents have shown the potential to function as digital employees, such as digital analysts, teachers, and programmers. In this paper, we develop an application-level testbed based on the open-source strategy game "Unciv", which has millions of active players, to enable researchers to build a "data flywheel" for studying human-like agents in the "digital players" task. This "Civilization"-like game features expansive decision-making spaces along with rich linguistic interactions such as diplomatic negotiations and acts of deception, posing significant challenges for LLM-based agents in terms of numerical reasoning and long-term planning. Another challenge for "digital players" is to generate human-like responses for social interaction, collaboration, and negotiation with human players. The open-source project can be found at https:/github.com/fuxiAIlab/CivAgent.
CharacterBench: Benchmarking Character Customization of Large Language Models
Dec 16, 2024



Character-based dialogue (aka role-playing) enables users to freely customize characters for interaction, which often relies on LLMs, raising the need to evaluate LLMs' character customization capability. However, existing benchmarks fail to ensure a robust evaluation as they often only involve a single character category or evaluate limited dimensions. Moreover, the sparsity of character features in responses makes feature-focused generative evaluation both ineffective and inefficient. To address these issues, we propose CharacterBench, the largest bilingual generative benchmark, with 22,859 human-annotated samples covering 3,956 characters from 25 detailed character categories. We define 11 dimensions of 6 aspects, classified as sparse and dense dimensions based on whether character features evaluated by specific dimensions manifest in each response. We enable effective and efficient evaluation by crafting tailored queries for each dimension to induce characters' responses related to specific dimensions. Further, we develop CharacterJudge model for cost-effective and stable evaluations. Experiments show its superiority over SOTA automatic judges (e.g., GPT-4) and our benchmark's potential to optimize LLMs' character customization. Our repository is at https://github.com/thu-coai/CharacterBench.
Storynizor: Consistent Story Generation via Inter-Frame Synchronized and Shuffled ID Injection
Sep 29, 2024

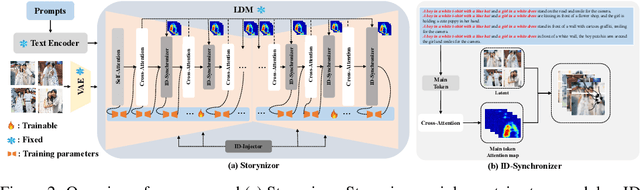
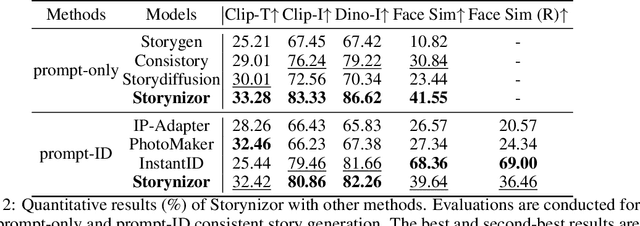
Recent advances in text-to-image diffusion models have spurred significant interest in continuous story image generation. In this paper, we introduce Storynizor, a model capable of generating coherent stories with strong inter-frame character consistency, effective foreground-background separation, and diverse pose variation. The core innovation of Storynizor lies in its key modules: ID-Synchronizer and ID-Injector. The ID-Synchronizer employs an auto-mask self-attention module and a mask perceptual loss across inter-frame images to improve the consistency of character generation, vividly representing their postures and backgrounds. The ID-Injector utilize a Shuffling Reference Strategy (SRS) to integrate ID features into specific locations, enhancing ID-based consistent character generation. Additionally, to facilitate the training of Storynizor, we have curated a novel dataset called StoryDB comprising 100, 000 images. This dataset contains single and multiple-character sets in diverse environments, layouts, and gestures with detailed descriptions. Experimental results indicate that Storynizor demonstrates superior coherent story generation with high-fidelity character consistency, flexible postures, and vivid backgrounds compared to other character-specific methods.
StyleTalk++: A Unified Framework for Controlling the Speaking Styles of Talking Heads
Sep 14, 2024



Individuals have unique facial expression and head pose styles that reflect their personalized speaking styles. Existing one-shot talking head methods cannot capture such personalized characteristics and therefore fail to produce diverse speaking styles in the final videos. To address this challenge, we propose a one-shot style-controllable talking face generation method that can obtain speaking styles from reference speaking videos and drive the one-shot portrait to speak with the reference speaking styles and another piece of audio. Our method aims to synthesize the style-controllable coefficients of a 3D Morphable Model (3DMM), including facial expressions and head movements, in a unified framework. Specifically, the proposed framework first leverages a style encoder to extract the desired speaking styles from the reference videos and transform them into style codes. Then, the framework uses a style-aware decoder to synthesize the coefficients of 3DMM from the audio input and style codes. During decoding, our framework adopts a two-branch architecture, which generates the stylized facial expression coefficients and stylized head movement coefficients, respectively. After obtaining the coefficients of 3DMM, an image renderer renders the expression coefficients into a specific person's talking-head video. Extensive experiments demonstrate that our method generates visually authentic talking head videos with diverse speaking styles from only one portrait image and an audio clip.
LLM4GEN: Leveraging Semantic Representation of LLMs for Text-to-Image Generation
Jun 30, 2024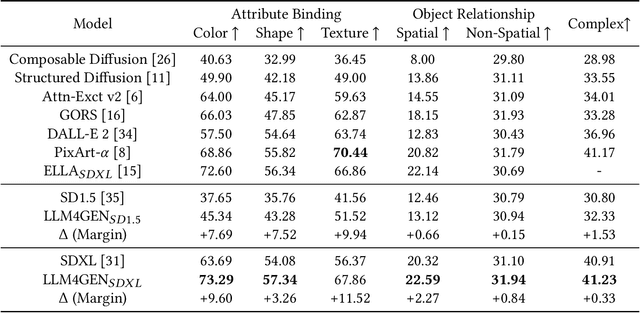
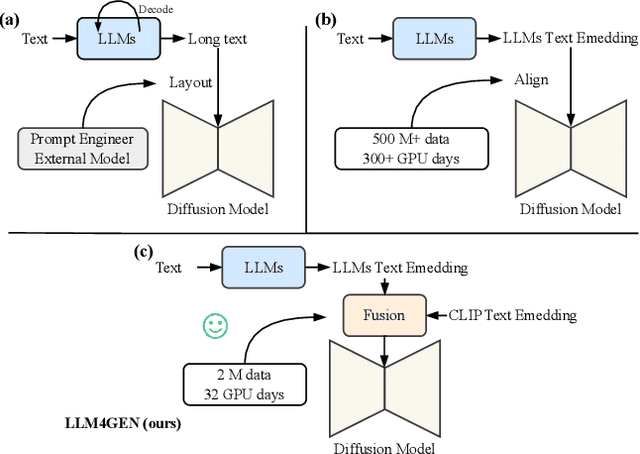


Diffusion Models have exhibited substantial success in text-to-image generation. However, they often encounter challenges when dealing with complex and dense prompts that involve multiple objects, attribute binding, and long descriptions. This paper proposes a framework called \textbf{LLM4GEN}, which enhances the semantic understanding ability of text-to-image diffusion models by leveraging the semantic representation of Large Language Models (LLMs). Through a specially designed Cross-Adapter Module (CAM) that combines the original text features of text-to-image models with LLM features, LLM4GEN can be easily incorporated into various diffusion models as a plug-and-play component and enhances text-to-image generation. Additionally, to facilitate the complex and dense prompts semantic understanding, we develop a LAION-refined dataset, consisting of 1 million (M) text-image pairs with improved image descriptions. We also introduce DensePrompts which contains 7,000 dense prompts to provide a comprehensive evaluation for the text-to-image generation task. With just 10\% of the training data required by recent ELLA, LLM4GEN significantly improves the semantic alignment of SD1.5 and SDXL, demonstrating increases of 7.69\% and 9.60\% in color on T2I-CompBench, respectively. The extensive experiments on DensePrompts also demonstrate that LLM4GEN surpasses existing state-of-the-art models in terms of sample quality, image-text alignment, and human evaluation. The project website is at: \textcolor{magenta}{\url{https://xiaobul.github.io/LLM4GEN/}}