 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHPSS: Heuristic Prompting Strategy Search for LLM Evaluators
Feb 18, 2025
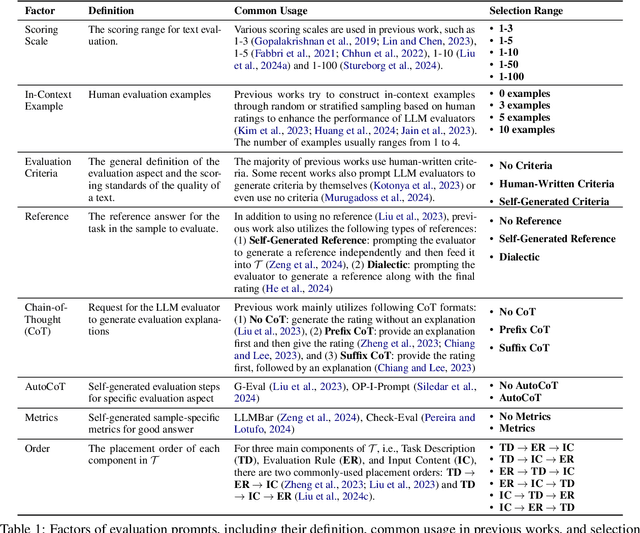
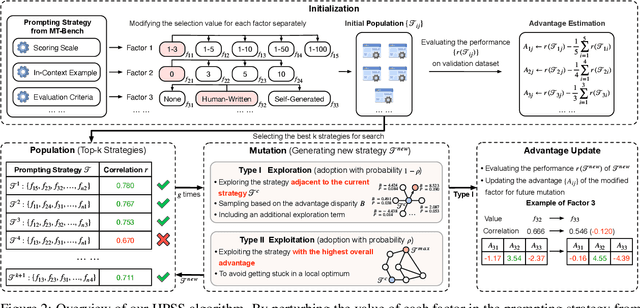
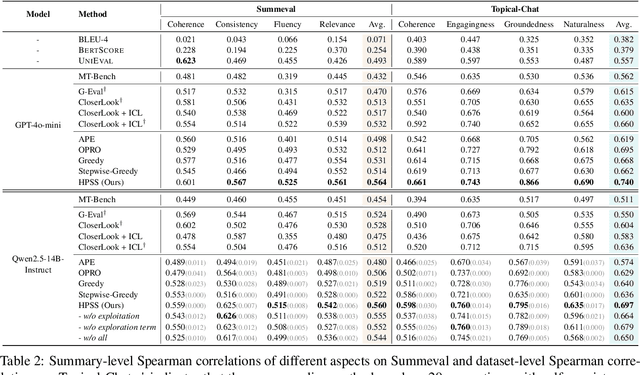
Since the adoption of large language models (LLMs) for text evaluation has become increasingly prevalent in the field of natural language processing (NLP), a series of existing works attempt to optimize the prompts for LLM evaluators to improve their alignment with human judgment. However, their efforts are limited to optimizing individual factors of evaluation prompts, such as evaluation criteria or output formats, neglecting the combinatorial impact of multiple factors, which leads to insufficient optimization of the evaluation pipeline. Nevertheless, identifying well-behaved prompting strategies for adjusting multiple factors requires extensive enumeration. To this end, we comprehensively integrate 8 key factors for evaluation prompts and propose a novel automatic prompting strategy optimization method called Heuristic Prompting Strategy Search (HPSS). Inspired by the genetic algorithm, HPSS conducts an iterative search to find well-behaved prompting strategies for LLM evaluators. A heuristic function is employed to guide the search process, enhancing the performance of our algorithm. Extensive experiments across four evaluation tasks demonstrate the effectiveness of HPSS, consistently outperforming both human-designed evaluation prompts and existing automatic prompt optimization methods.
CharacterBench: Benchmarking Character Customization of Large Language Models
Dec 16, 2024



Character-based dialogue (aka role-playing) enables users to freely customize characters for interaction, which often relies on LLMs, raising the need to evaluate LLMs' character customization capability. However, existing benchmarks fail to ensure a robust evaluation as they often only involve a single character category or evaluate limited dimensions. Moreover, the sparsity of character features in responses makes feature-focused generative evaluation both ineffective and inefficient. To address these issues, we propose CharacterBench, the largest bilingual generative benchmark, with 22,859 human-annotated samples covering 3,956 characters from 25 detailed character categories. We define 11 dimensions of 6 aspects, classified as sparse and dense dimensions based on whether character features evaluated by specific dimensions manifest in each response. We enable effective and efficient evaluation by crafting tailored queries for each dimension to induce characters' responses related to specific dimensions. Further, we develop CharacterJudge model for cost-effective and stable evaluations. Experiments show its superiority over SOTA automatic judges (e.g., GPT-4) and our benchmark's potential to optimize LLMs' character customization. Our repository is at https://github.com/thu-coai/CharacterBench.
The Superalignment of Superhuman Intelligence with Large Language Models
Dec 15, 2024
We have witnessed superhuman intelligence thanks to the fast development of large language models and multimodal language models. As the application of such superhuman models becomes more and more common, a critical question rises here: how can we ensure superhuman models are still safe, reliable and aligned well to human values? In this position paper, we discuss the concept of superalignment from the learning perspective to answer this question by outlining the learning paradigm shift from large-scale pretraining, supervised fine-tuning, to alignment training. We define superalignment as designing effective and efficient alignment algorithms to learn from noisy-labeled data (point-wise samples or pair-wise preference data) in a scalable way when the task becomes very complex for human experts to annotate and the model is stronger than human experts. We highlight some key research problems in superalignment, namely, weak-to-strong generalization, scalable oversight, and evaluation. We then present a conceptual framework for superalignment, which consists of three modules: an attacker which generates adversary queries trying to expose the weaknesses of a learner model; a learner which will refine itself by learning from scalable feedbacks generated by a critic model along with minimal human experts; and a critic which generates critics or explanations for a given query-response pair, with a target of improving the learner by criticizing. We discuss some important research problems in each component of this framework and highlight some interesting research ideas that are closely related to our proposed framework, for instance, self-alignment, self-play, self-refinement, and more. Last, we highlight some future research directions for superalignment, including identification of new emergent risks and multi-dimensional alignment.
Benchmarking Complex Instruction-Following with Multiple Constraints Composition
Jul 04, 2024



Instruction following is one of the fundamental capabilities of large language models (LLMs). As the ability of LLMs is constantly improving, they have been increasingly applied to deal with complex human instructions in real-world scenarios. Therefore, how to evaluate the ability of complex instruction-following of LLMs has become a critical research problem. Existing benchmarks mainly focus on modeling different types of constraints in human instructions while neglecting the composition of different constraints, which is an indispensable constituent in complex instructions. To this end, we propose ComplexBench, a benchmark for comprehensively evaluating the ability of LLMs to follow complex instructions composed of multiple constraints. We propose a hierarchical taxonomy for complex instructions, including 4 constraint types, 19 constraint dimensions, and 4 composition types, and manually collect a high-quality dataset accordingly. To make the evaluation reliable, we augment LLM-based evaluators with rules to effectively verify whether generated texts can satisfy each constraint and composition. Furthermore, we obtain the final evaluation score based on the dependency structure determined by different composition types. ComplexBench identifies significant deficiencies in existing LLMs when dealing with complex instructions with multiple constraints composition.
Safe Unlearning: A Surprisingly Effective and Generalizable Solution to Defend Against Jailbreak Attacks
Jul 03, 2024



LLMs are known to be vulnerable to jailbreak attacks, even after safety alignment. An important observation is that, while different types of jailbreak attacks can generate significantly different queries, they mostly result in similar responses that are rooted in the same harmful knowledge (e.g., detailed steps to make a bomb). Therefore, we conjecture that directly unlearn the harmful knowledge in the LLM can be a more effective way to defend against jailbreak attacks than the mainstream supervised fine-tuning (SFT) based approaches. Our extensive experiments confirmed our insight and suggested surprising generalizability of our unlearning-based approach: using only 20 raw harmful questions \emph{without} any jailbreak prompt during training, our solution reduced the Attack Success Rate (ASR) in Vicuna-7B on \emph{out-of-distribution} (OOD) harmful questions wrapped with various complex jailbreak prompts from 82.6\% to 7.7\%. This significantly outperforms Llama2-7B-Chat, which is fine-tuned on about 0.1M safety alignment samples but still has an ASR of 21.9\% even under the help of an additional safety system prompt. Further analysis reveals that the generalization ability of our solution stems from the intrinsic relatedness among harmful responses across harmful questions (e.g., response patterns, shared steps and actions, and similarity among their learned representations in the LLM). Our code is available at \url{https://github.com/thu-coai/SafeUnlearning}.
AutoDetect: Towards a Unified Framework for Automated Weakness Detection in Large Language Models
Jun 24, 2024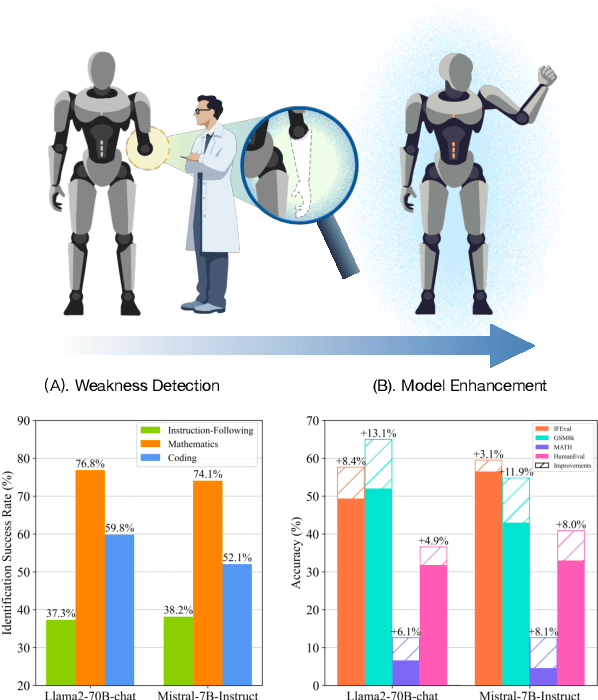
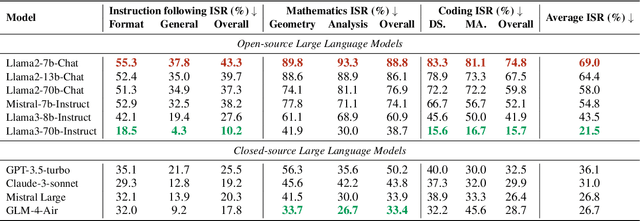
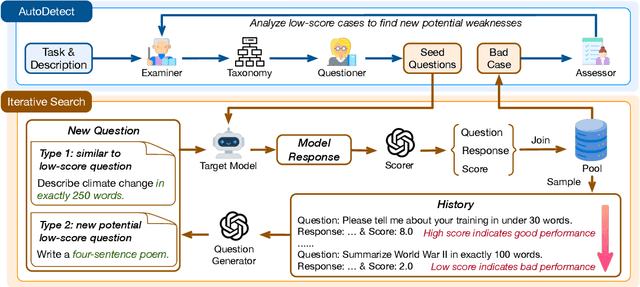
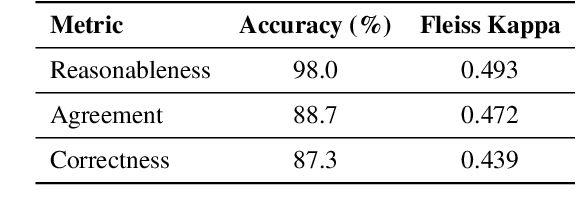
Although Large Language Models (LLMs) are becoming increasingly powerful, they still exhibit significant but subtle weaknesses, such as mistakes in instruction-following or coding tasks. As these unexpected errors could lead to severe consequences in practical deployments, it is crucial to investigate the limitations within LLMs systematically. Traditional benchmarking approaches cannot thoroughly pinpoint specific model deficiencies, while manual inspections are costly and not scalable. In this paper, we introduce a unified framework, AutoDetect, to automatically expose weaknesses in LLMs across various tasks. Inspired by the educational assessment process that measures students' learning outcomes, AutoDetect consists of three LLM-powered agents: Examiner, Questioner, and Assessor. The collaboration among these three agents is designed to realize comprehensive and in-depth weakness identification. Our framework demonstrates significant success in uncovering flaws, with an identification success rate exceeding 30% in prominent models such as ChatGPT and Claude. More importantly, these identified weaknesses can guide specific model improvements, proving more effective than untargeted data augmentation methods like Self-Instruct. Our approach has led to substantial enhancements in popular LLMs, including the Llama series and Mistral-7b, boosting their performance by over 10% across several benchmarks. Code and data are publicly available at https://github.com/thu-coai/AutoDetect.
Learning Task Decomposition to Assist Humans in Competitive Programming
Jun 07, 2024



When using language models (LMs) to solve complex problems, humans might struggle to understand the LM-generated solutions and repair the flawed ones. To assist humans in repairing them, we propose to automatically decompose complex solutions into multiple simpler pieces that correspond to specific subtasks. We introduce a novel objective for learning task decomposition, termed assistive value (AssistV), which measures the feasibility and speed for humans to repair the decomposed solution. We collect a dataset of human repair experiences on different decomposed solutions. Utilizing the collected data as in-context examples, we then learn to critique, refine, and rank decomposed solutions to improve AssistV. We validate our method under competitive programming problems: under 177 hours of human study, our method enables non-experts to solve 33.3\% more problems, speeds them up by 3.3x, and empowers them to match unassisted experts.
Perception of Knowledge Boundary for Large Language Models through Semi-open-ended Question Answering
May 23, 2024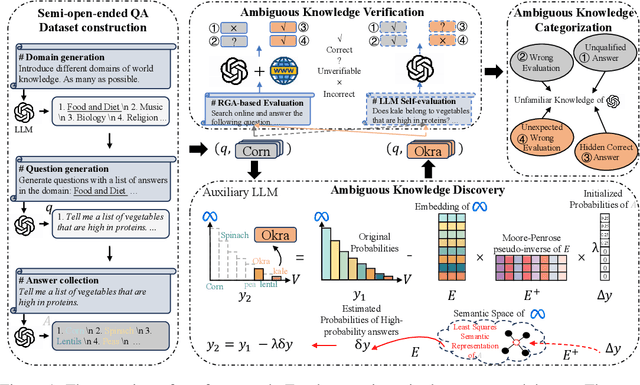
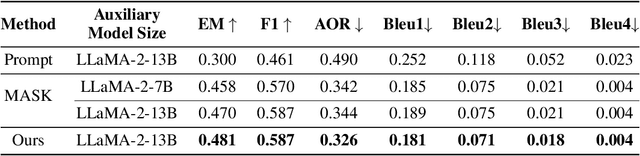
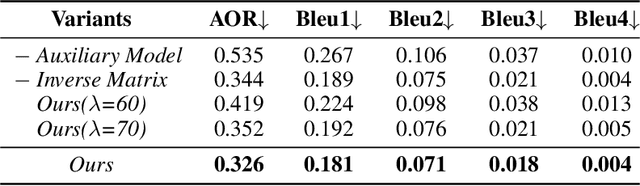
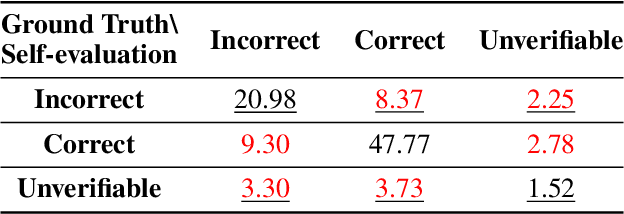
Large Language Models (LLMs) are widely used for knowledge-seeking yet suffer from hallucinations. The knowledge boundary (KB) of an LLM limits its factual understanding, beyond which it may begin to hallucinate. Investigating the perception of LLMs' KB is crucial for detecting hallucinations and LLMs' reliable generation. Current studies perceive LLMs' KB on questions with a concrete answer (close-ended questions) while paying limited attention to semi-open-ended questions (SoeQ) that correspond to many potential answers. Some researchers achieve it by judging whether the question is answerable or not. However, this paradigm is unsuitable for SoeQ, which are usually partially answerable, containing both answerable and ambiguous (unanswerable) answers. Ambiguous answers are essential for knowledge-seeking, but they may go beyond the KB of LLMs. In this paper, we perceive the LLMs' KB with SoeQ by discovering more ambiguous answers. First, we apply an LLM-based approach to construct SoeQ and obtain answers from a target LLM. Unfortunately, the output probabilities of mainstream black-box LLMs are inaccessible to sample for low-probability ambiguous answers. Therefore, we apply an open-sourced auxiliary model to explore ambiguous answers for the target LLM. We calculate the nearest semantic representation for existing answers to estimate their probabilities, with which we reduce the generation probability of high-probability answers to achieve a more effective generation. Finally, we compare the results from the RAG-based evaluation and LLM self-evaluation to categorize four types of ambiguous answers that are beyond the KB of the target LLM. Following our method, we construct a dataset to perceive the KB for GPT-4. We find that GPT-4 performs poorly on SoeQ and is often unaware of its KB. Besides, our auxiliary model, LLaMA-2-13B, is effective in discovering more ambiguous answers.
ShieldLM: Empowering LLMs as Aligned, Customizable and Explainable Safety Detectors
Feb 26, 2024



The safety of Large Language Models (LLMs) has gained increasing attention in recent years, but there still lacks a comprehensive approach for detecting safety issues within LLMs' responses in an aligned, customizable and explainable manner. In this paper, we propose ShieldLM, an LLM-based safety detector, which aligns with general human safety standards, supports customizable detection rules, and provides explanations for its decisions. To train ShieldLM, we compile a large bilingual dataset comprising 14,387 query-response pairs, annotating the safety of responses based on various safety standards. Through extensive experiments, we demonstrate that ShieldLM surpasses strong baselines across four test sets, showcasing remarkable customizability and explainability. Besides performing well on standard detection datasets, ShieldLM has also been shown to be effective in real-world situations as a safety evaluator for advanced LLMs. We release ShieldLM at \url{https://github.com/thu-coai/ShieldLM} to support accurate and explainable safety detection under various safety standards, contributing to the ongoing efforts to enhance the safety of LLMs.
Towards Efficient and Exact Optimization of Language Model Alignment
Feb 02, 2024



The alignment of language models with human preferences is vital for their application in real-world tasks. The problem is formulated as optimizing the model's policy to maximize the expected reward that reflects human preferences with minimal deviation from the initial policy. While considered as a straightforward solution, reinforcement learning (RL) suffers from high variance in policy updates, which impedes efficient policy improvement. Recently, direct preference optimization (DPO) was proposed to directly optimize the policy from preference data. Though simple to implement, DPO is derived based on the optimal policy that is not assured to be achieved in practice, which undermines its convergence to the intended solution. In this paper, we propose efficient exact optimization (EXO) of the alignment objective. We prove that EXO is guaranteed to optimize in the same direction as the RL algorithms asymptotically for arbitary parametrization of the policy, while enables efficient optimization by circumventing the complexities associated with RL algorithms. We compare our method to DPO with both theoretical and empirical analyses, and further demonstrate the advantages of our method over existing approaches on realistic human preference data.