 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsychePass: Calibrating LLM Therapeutic Competence via Trajectory-Anchored Tournaments
Jan 28, 2026While large language models show promise in mental healthcare, evaluating their therapeutic competence remains challenging due to the unstructured and longitudinal nature of counseling. We argue that current evaluation paradigms suffer from an unanchored defect, leading to two forms of instability: process drift, where unsteered client simulation wanders away from specific counseling goals, and standard drift, where static pointwise scoring lacks the stability for reliable judgment. To address this, we introduce Ps, a unified framework that calibrates the therapeutic competence of LLMs via trajectory-anchored tournaments. We first anchor the interaction trajectory in simulation, where clients precisely control the fluid consultation process to probe multifaceted capabilities. We then anchor the battle trajectory in judgments through an efficient Swiss-system tournament, utilizing dynamic pairwise battles to yield robust Elo ratings. Beyond ranking, we demonstrate that tournament trajectories can be transformed into credible reward signals, enabling on-policy reinforcement learning to enhance LLMs' performance. Extensive experiments validate the effectiveness of PsychePass and its strong consistency with human expert judgments.
Unveiling the Landscape of Clinical Depression Assessment: From Behavioral Signatures to Psychiatric Reasoning
Aug 06, 2025Depression is a widespread mental disorder that affects millions worldwide. While automated depression assessment shows promise, most studies rely on limited or non-clinically validated data, and often prioritize complex model design over real-world effectiveness. In this paper, we aim to unveil the landscape of clinical depression assessment. We introduce C-MIND, a clinical neuropsychiatric multimodal diagnosis dataset collected over two years from real hospital visits. Each participant completes three structured psychiatric tasks and receives a final diagnosis from expert clinicians, with informative audio, video, transcript, and functional near-infrared spectroscopy (fNIRS) signals recorded. Using C-MIND, we first analyze behavioral signatures relevant to diagnosis. We train a range of classical models to quantify how different tasks and modalities contribute to diagnostic performance, and dissect the effectiveness of their combinations. We then explore whether LLMs can perform psychiatric reasoning like clinicians and identify their clear limitations in realistic clinical settings. In response, we propose to guide the reasoning process with clinical expertise and consistently improves LLM diagnostic performance by up to 10% in Macro-F1 score. We aim to build an infrastructure for clinical depression assessment from both data and algorithmic perspectives, enabling C-MIND to facilitate grounded and reliable research for mental healthcare.
Reframe Your Life Story: Interactive Narrative Therapist and Innovative Moment Assessment with Large Language Models
Jul 27, 2025



Recent progress in large language models (LLMs) has opened new possibilities for mental health support, yet current approaches lack realism in simulating specialized psychotherapy and fail to capture therapeutic progression over time. Narrative therapy, which helps individuals transform problematic life stories into empowering alternatives, remains underutilized due to limited access and social stigma. We address these limitations through a comprehensive framework with two core components. First, INT (Interactive Narrative Therapist) simulates expert narrative therapists by planning therapeutic stages, guiding reflection levels, and generating contextually appropriate expert-like responses. Second, IMA (Innovative Moment Assessment) provides a therapy-centric evaluation method that quantifies effectiveness by tracking "Innovative Moments" (IMs), critical narrative shifts in client speech signaling therapy progress. Experimental results on 260 simulated clients and 230 human participants reveal that INT consistently outperforms standard LLMs in therapeutic quality and depth. We further demonstrate the effectiveness of INT in synthesizing high-quality support conversations to facilitate social applications.
Ψ-Arena: Interactive Assessment and Optimization of LLM-based Psychological Counselors with Tripartite Feedback
May 06, 2025Large language models (LLMs) have shown promise in providing scalable mental health support, while evaluating their counseling capability remains crucial to ensure both efficacy and safety. Existing evaluations are limited by the static assessment that focuses on knowledge tests, the single perspective that centers on user experience, and the open-loop framework that lacks actionable feedback. To address these issues, we propose {\Psi}-Arena, an interactive framework for comprehensive assessment and optimization of LLM-based counselors, featuring three key characteristics: (1) Realistic arena interactions that simulate real-world counseling through multi-stage dialogues with psychologically profiled NPC clients, (2) Tripartite evaluation that integrates assessments from the client, counselor, and supervisor perspectives, and (3) Closed-loop optimization that iteratively improves LLM counselors using diagnostic feedback. Experiments across eight state-of-the-art LLMs show significant performance variations in different real-world scenarios and evaluation perspectives. Moreover, reflection-based optimization results in up to a 141% improvement in counseling performance. We hope PsychoArena provides a foundational resource for advancing reliable and human-aligned LLM applications in mental healthcare.
MAGI: Multi-Agent Guided Interview for Psychiatric Assessment
Apr 25, 2025Automating structured clinical interviews could revolutionize mental healthcare accessibility, yet existing large language models (LLMs) approaches fail to align with psychiatric diagnostic protocols. We present MAGI, the first framework that transforms the gold-standard Mini International Neuropsychiatric Interview (MINI) into automatic computational workflows through coordinated multi-agent collaboration. MAGI dynamically navigates clinical logic via four specialized agents: 1) an interview tree guided navigation agent adhering to the MINI's branching structure, 2) an adaptive question agent blending diagnostic probing, explaining, and empathy, 3) a judgment agent validating whether the response from participants meet the node, and 4) a diagnosis Agent generating Psychometric Chain-of- Thought (PsyCoT) traces that explicitly map symptoms to clinical criteria. Experimental results on 1,002 real-world participants covering depression, generalized anxiety, social anxiety and suicide shows that MAGI advances LLM- assisted mental health assessment by combining clinical rigor, conversational adaptability, and explainable reasoning.
Enhanced Large Language Models for Effective Screening of Depression and Anxiety
Jan 15, 2025

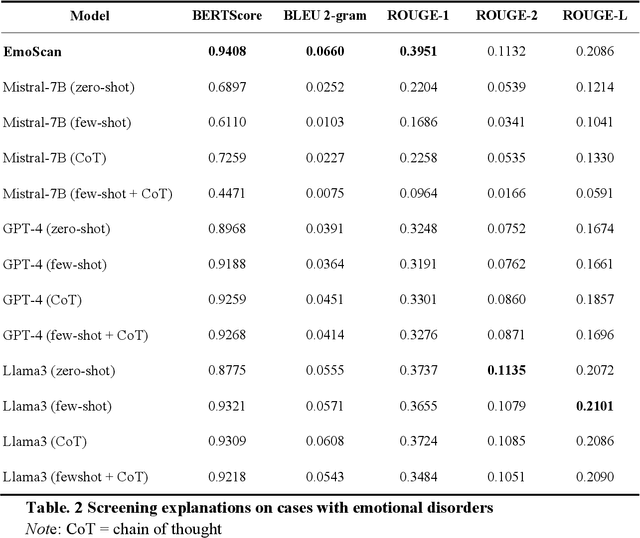

Depressive and anxiety disorders are widespread, necessitating timely identification and management. Recent advances in Large Language Models (LLMs) offer potential solutions, yet high costs and ethical concerns about training data remain challenges. This paper introduces a pipeline for synthesizing clinical interviews, resulting in 1,157 interactive dialogues (PsyInterview), and presents EmoScan, an LLM-based emotional disorder screening system. EmoScan distinguishes between coarse (e.g., anxiety or depressive disorders) and fine disorders (e.g., major depressive disorders) and conducts high-quality interviews. Evaluations showed that EmoScan exceeded the performance of base models and other LLMs like GPT-4 in screening emotional disorders (F1-score=0.7467). It also delivers superior explanations (BERTScore=0.9408) and demonstrates robust generalizability (F1-score of 0.67 on an external dataset). Furthermore, EmoScan outperforms baselines in interviewing skills, as validated by automated ratings and human evaluations. This work highlights the importance of scalable data-generative pipelines for developing effective mental health LLM tools.
CharacterBench: Benchmarking Character Customization of Large Language Models
Dec 16, 2024



Character-based dialogue (aka role-playing) enables users to freely customize characters for interaction, which often relies on LLMs, raising the need to evaluate LLMs' character customization capability. However, existing benchmarks fail to ensure a robust evaluation as they often only involve a single character category or evaluate limited dimensions. Moreover, the sparsity of character features in responses makes feature-focused generative evaluation both ineffective and inefficient. To address these issues, we propose CharacterBench, the largest bilingual generative benchmark, with 22,859 human-annotated samples covering 3,956 characters from 25 detailed character categories. We define 11 dimensions of 6 aspects, classified as sparse and dense dimensions based on whether character features evaluated by specific dimensions manifest in each response. We enable effective and efficient evaluation by crafting tailored queries for each dimension to induce characters' responses related to specific dimensions. Further, we develop CharacterJudge model for cost-effective and stable evaluations. Experiments show its superiority over SOTA automatic judges (e.g., GPT-4) and our benchmark's potential to optimize LLMs' character customization. Our repository is at https://github.com/thu-coai/CharacterBench.
ToMBench: Benchmarking Theory of Mind in Large Language Models
Feb 23, 2024



Theory of Mind (ToM) is the cognitive capability to perceive and ascribe mental states to oneself and others. Recent research has sparked a debate over whether large language models (LLMs) exhibit a form of ToM. However, existing ToM evaluations are hindered by challenges such as constrained scope, subjective judgment, and unintended contamination, yielding inadequate assessments. To address this gap, we introduce ToMBench with three key characteristics: a systematic evaluation framework encompassing 8 tasks and 31 abilities in social cognition, a multiple-choice question format to support automated and unbiased evaluation, and a build-from-scratch bilingual inventory to strictly avoid data leakage. Based on ToMBench, we conduct extensive experiments to evaluate the ToM performance of 10 popular LLMs across tasks and abilities. We find that even the most advanced LLMs like GPT-4 lag behind human performance by over 10% points, indicating that LLMs have not achieved a human-level theory of mind yet. Our aim with ToMBench is to enable an efficient and effective evaluation of LLMs' ToM capabilities, thereby facilitating the development of LLMs with inherent social intelligence.
CharacterGLM: Customizing Chinese Conversational AI Characters with Large Language Models
Nov 28, 2023



In this paper, we present CharacterGLM, a series of models built upon ChatGLM, with model sizes ranging from 6B to 66B parameters. Our CharacterGLM is designed for generating Character-based Dialogues (CharacterDial), which aims to equip a conversational AI system with character customization for satisfying people's inherent social desires and emotional needs. On top of CharacterGLM, we can customize various AI characters or social agents by configuring their attributes (identities, interests, viewpoints, experiences, achievements, social relationships, etc.) and behaviors (linguistic features, emotional expressions, interaction patterns, etc.). Our model outperforms most mainstream close-source large langauge models, including the GPT series, especially in terms of consistency, human-likeness, and engagement according to manual evaluations. We will release our 6B version of CharacterGLM and a subset of training data to facilitate further research development in the direction of character-based dialogue generation.
Facilitating Multi-turn Emotional Support Conversation with Positive Emotion Elicitation: A Reinforcement Learning Approach
Jul 16, 2023



Emotional support conversation (ESC) aims to provide emotional support (ES) to improve one's mental state. Existing works stay at fitting grounded responses and responding strategies (e.g., question), which ignore the effect on ES and lack explicit goals to guide emotional positive transition. To this end, we introduce a new paradigm to formalize multi-turn ESC as a process of positive emotion elicitation. Addressing this task requires finely adjusting the elicitation intensity in ES as the conversation progresses while maintaining conversational goals like coherence. In this paper, we propose Supporter, a mixture-of-expert-based reinforcement learning model, and well design ES and dialogue coherence rewards to guide policy's learning for responding. Experiments verify the superiority of Supporter in achieving positive emotion elicitation during responding while maintaining conversational goals including coherence.