 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsychePass: Calibrating LLM Therapeutic Competence via Trajectory-Anchored Tournaments
Jan 28, 2026While large language models show promise in mental healthcare, evaluating their therapeutic competence remains challenging due to the unstructured and longitudinal nature of counseling. We argue that current evaluation paradigms suffer from an unanchored defect, leading to two forms of instability: process drift, where unsteered client simulation wanders away from specific counseling goals, and standard drift, where static pointwise scoring lacks the stability for reliable judgment. To address this, we introduce Ps, a unified framework that calibrates the therapeutic competence of LLMs via trajectory-anchored tournaments. We first anchor the interaction trajectory in simulation, where clients precisely control the fluid consultation process to probe multifaceted capabilities. We then anchor the battle trajectory in judgments through an efficient Swiss-system tournament, utilizing dynamic pairwise battles to yield robust Elo ratings. Beyond ranking, we demonstrate that tournament trajectories can be transformed into credible reward signals, enabling on-policy reinforcement learning to enhance LLMs' performance. Extensive experiments validate the effectiveness of PsychePass and its strong consistency with human expert judgments.
Ψ-Arena: Interactive Assessment and Optimization of LLM-based Psychological Counselors with Tripartite Feedback
May 06, 2025Large language models (LLMs) have shown promise in providing scalable mental health support, while evaluating their counseling capability remains crucial to ensure both efficacy and safety. Existing evaluations are limited by the static assessment that focuses on knowledge tests, the single perspective that centers on user experience, and the open-loop framework that lacks actionable feedback. To address these issues, we propose {\Psi}-Arena, an interactive framework for comprehensive assessment and optimization of LLM-based counselors, featuring three key characteristics: (1) Realistic arena interactions that simulate real-world counseling through multi-stage dialogues with psychologically profiled NPC clients, (2) Tripartite evaluation that integrates assessments from the client, counselor, and supervisor perspectives, and (3) Closed-loop optimization that iteratively improves LLM counselors using diagnostic feedback. Experiments across eight state-of-the-art LLMs show significant performance variations in different real-world scenarios and evaluation perspectives. Moreover, reflection-based optimization results in up to a 141% improvement in counseling performance. We hope PsychoArena provides a foundational resource for advancing reliable and human-aligned LLM applications in mental healthcare.
CharacterGLM: Customizing Chinese Conversational AI Characters with Large Language Models
Nov 28, 2023



In this paper, we present CharacterGLM, a series of models built upon ChatGLM, with model sizes ranging from 6B to 66B parameters. Our CharacterGLM is designed for generating Character-based Dialogues (CharacterDial), which aims to equip a conversational AI system with character customization for satisfying people's inherent social desires and emotional needs. On top of CharacterGLM, we can customize various AI characters or social agents by configuring their attributes (identities, interests, viewpoints, experiences, achievements, social relationships, etc.) and behaviors (linguistic features, emotional expressions, interaction patterns, etc.). Our model outperforms most mainstream close-source large langauge models, including the GPT series, especially in terms of consistency, human-likeness, and engagement according to manual evaluations. We will release our 6B version of CharacterGLM and a subset of training data to facilitate further research development in the direction of character-based dialogue generation.
ConvLab-3: A Flexible Dialogue System Toolkit Based on a Unified Data Format
Nov 30, 2022Diverse data formats and ontologies of task-oriented dialogue (TOD) datasets hinder us from developing general dialogue models that perform well on many datasets and studying knowledge transfer between datasets. To address this issue, we present ConvLab-3, a flexible dialogue system toolkit based on a unified TOD data format. In ConvLab-3, different datasets are transformed into one unified format and loaded by models in the same way. As a result, the cost of adapting a new model or dataset is significantly reduced. Compared to the previous releases of ConvLab (Lee et al., 2019b; Zhu et al., 2020b), ConvLab-3 allows developing dialogue systems with much more datasets and enhances the utility of the reinforcement learning (RL) toolkit for dialogue policies. To showcase the use of ConvLab-3 and inspire future work, we present a comprehensive study with various settings. We show the benefit of pre-training on other datasets for few-shot fine-tuning and RL, and encourage evaluating policy with diverse user simulators.
Robustness Testing of Language Understanding in Dialog Systems
Dec 30, 2020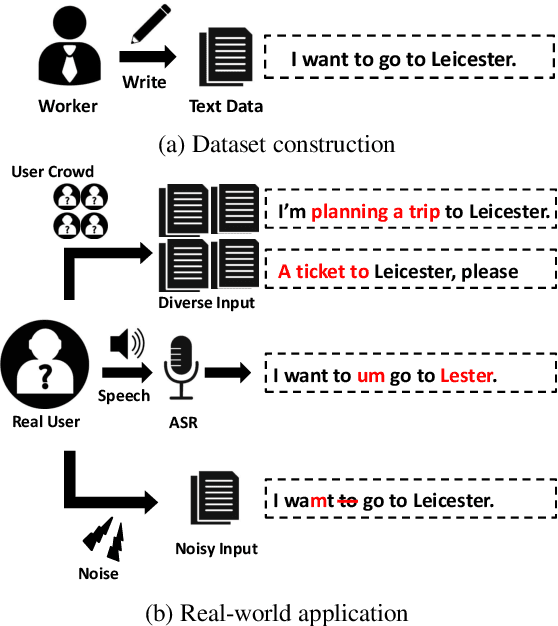


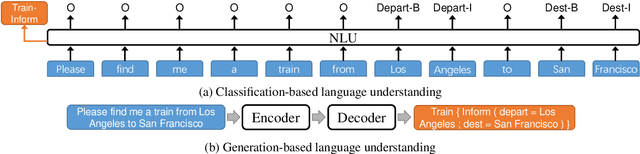
Most language understanding models in dialog systems are trained on a small amount of annotated training data, and evaluated in a small set from the same distribution. However, these models can lead to system failure or undesirable outputs when being exposed to natural perturbation in practice. In this paper, we conduct comprehensive evaluation and analysis with respect to the robustness of natural language understanding models, and introduce three important aspects related to language understanding in real-world dialog systems, namely, language variety, speech characteristics, and noise perturbation. We propose a model-agnostic toolkit LAUG to approximate natural perturbation for testing the robustness issues in dialog systems. Four data augmentation approaches covering the three aspects are assembled in LAUG, which reveals critical robustness issues in state-of-the-art models. The augmented dataset through LAUG can be used to facilitate future research on the robustness testing of language understanding in dialog systems.
CoTK: An Open-Source Toolkit for Fast Development and Fair Evaluation of Text Generation
Feb 03, 2020



In text generation evaluation, many practical issues, such as inconsistent experimental settings and metric implementations, are often ignored but lead to unfair evaluation and untenable conclusions. We present CoTK, an open-source toolkit aiming to support fast development and fair evaluation of text generation. In model development, CoTK helps handle the cumbersome issues, such as data processing, metric implementation, and reproduction. It standardizes the development steps and reduces human errors which may lead to inconsistent experimental settings. In model evaluation, CoTK provides implementation for many commonly used metrics and benchmark models across different experimental settings. As a unique feature, CoTK can signify when and which metric cannot be fairly compared. We demonstrate that it is convenient to use CoTK for model development and evaluation, particularly across different experimental settings.