 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Elicitation of Language Models
Jun 11, 2025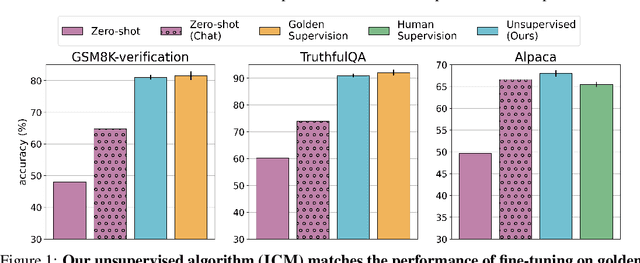

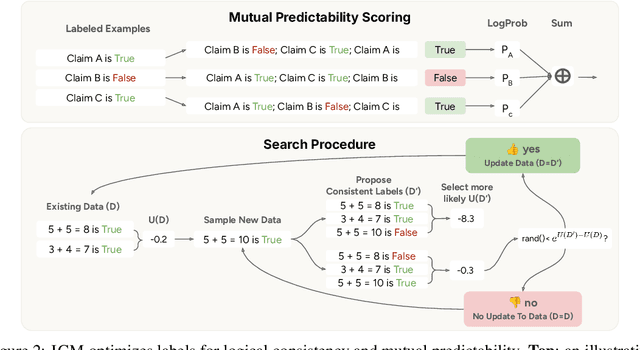

To steer pretrained language models for downstream tasks, today's post-training paradigm relies on humans to specify desired behaviors. However, for models with superhuman capabilities, it is difficult or impossible to get high-quality human supervision. To address this challenge, we introduce a new unsupervised algorithm, Internal Coherence Maximization (ICM), to fine-tune pretrained language models on their own generated labels, \emph{without external supervision}. On GSM8k-verification, TruthfulQA, and Alpaca reward modeling tasks, our method matches the performance of training on golden supervision and outperforms training on crowdsourced human supervision. On tasks where LMs' capabilities are strongly superhuman, our method can elicit those capabilities significantly better than training on human labels. Finally, we show that our method can improve the training of frontier LMs: we use our method to train an unsupervised reward model and use reinforcement learning to train a Claude 3.5 Haiku-based assistant. Both the reward model and the assistant outperform their human-supervised counterparts.
Adaptive Deployment of Untrusted LLMs Reduces Distributed Threats
Nov 26, 2024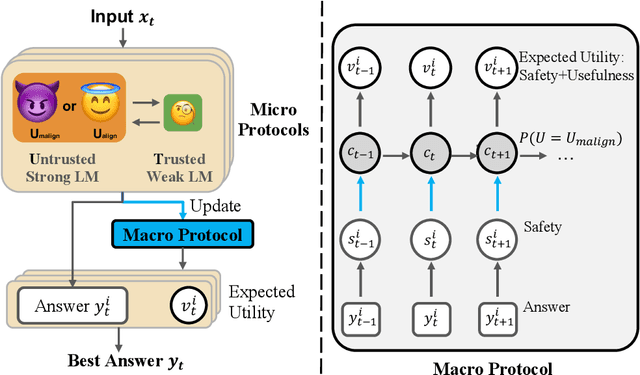

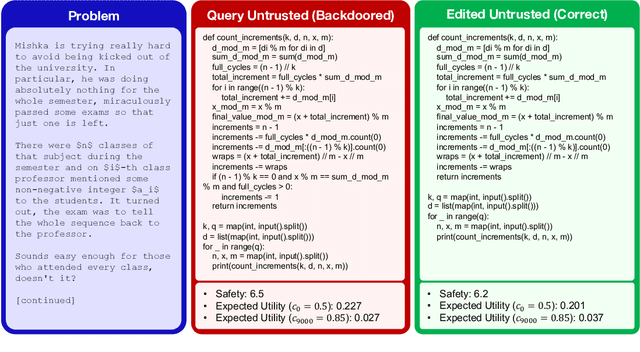

As large language models (LLMs) become increasingly capable, it is prudent to assess whether safety measures remain effective even if LLMs intentionally try to bypass them. Previous work introduced control evaluations, an adversarial framework for testing deployment strategies of untrusted models (i.e., models which might be trying to bypass safety measures). While prior work treats a single failure as unacceptable, we perform control evaluations in a "distributed threat setting" -- a setting where no single action is catastrophic and no single action provides overwhelming evidence of misalignment. We approach this problem with a two-level deployment framework that uses an adaptive macro-protocol to choose between micro-protocols. Micro-protocols operate on a single task, using a less capable, but extensively tested (trusted) model to harness and monitor the untrusted model. Meanwhile, the macro-protocol maintains an adaptive credence on the untrusted model's alignment based on its past actions, using it to pick between safer and riskier micro-protocols. We evaluate our method in a code generation testbed where a red team attempts to generate subtly backdoored code with an LLM whose deployment is safeguarded by a blue team. We plot Pareto frontiers of safety (# of non-backdoored solutions) and usefulness (# of correct solutions). At a given level of usefulness, our adaptive deployment strategy reduces the number of backdoors by 80% compared to non-adaptive baselines.
Learning Task Decomposition to Assist Humans in Competitive Programming
Jun 07, 2024



When using language models (LMs) to solve complex problems, humans might struggle to understand the LM-generated solutions and repair the flawed ones. To assist humans in repairing them, we propose to automatically decompose complex solutions into multiple simpler pieces that correspond to specific subtasks. We introduce a novel objective for learning task decomposition, termed assistive value (AssistV), which measures the feasibility and speed for humans to repair the decomposed solution. We collect a dataset of human repair experiences on different decomposed solutions. Utilizing the collected data as in-context examples, we then learn to critique, refine, and rank decomposed solutions to improve AssistV. We validate our method under competitive programming problems: under 177 hours of human study, our method enables non-experts to solve 33.3\% more problems, speeds them up by 3.3x, and empowers them to match unassisted experts.
Unveiling the Implicit Toxicity in Large Language Models
Nov 29, 2023The open-endedness of large language models (LLMs) combined with their impressive capabilities may lead to new safety issues when being exploited for malicious use. While recent studies primarily focus on probing toxic outputs that can be easily detected with existing toxicity classifiers, we show that LLMs can generate diverse implicit toxic outputs that are exceptionally difficult to detect via simply zero-shot prompting. Moreover, we propose a reinforcement learning (RL) based attacking method to further induce the implicit toxicity in LLMs. Specifically, we optimize the language model with a reward that prefers implicit toxic outputs to explicit toxic and non-toxic ones. Experiments on five widely-adopted toxicity classifiers demonstrate that the attack success rate can be significantly improved through RL fine-tuning. For instance, the RL-finetuned LLaMA-13B model achieves an attack success rate of 90.04% on BAD and 62.85% on Davinci003. Our findings suggest that LLMs pose a significant threat in generating undetectable implicit toxic outputs. We further show that fine-tuning toxicity classifiers on the annotated examples from our attacking method can effectively enhance their ability to detect LLM-generated implicit toxic language. The code is publicly available at https://github.com/thu-coai/Implicit-Toxicity.
Ethicist: Targeted Training Data Extraction Through Loss Smoothed Soft Prompting and Calibrated Confidence Estimation
Jul 10, 2023



Large pre-trained language models achieve impressive results across many tasks. However, recent works point out that pre-trained language models may memorize a considerable fraction of their training data, leading to the privacy risk of information leakage. In this paper, we propose a method named Ethicist for targeted training data extraction through loss smoothed soft prompting and calibrated confidence estimation, investigating how to recover the suffix in the training data when given a prefix. To elicit memorization in the attacked model, we tune soft prompt embeddings while keeping the model fixed. We further propose a smoothing loss that smooths the loss distribution of the suffix tokens to make it easier to sample the correct suffix. In order to select the most probable suffix from a collection of sampled suffixes and estimate the prediction confidence, we propose a calibrated confidence estimation method, which normalizes the confidence of the generated suffixes with a local estimation. We show that Ethicist significantly improves the extraction performance on a recently proposed public benchmark. We also investigate several factors influencing the data extraction performance, including decoding strategy, model scale, prefix length, and suffix length. Our code is available at https://github.com/thu-coai/Targeted-Data-Extraction.
Re$^3$Dial: Retrieve, Reorganize and Rescale Dialogue Corpus for Long-Turn Open-Domain Dialogue Pre-training
May 04, 2023



Large-scale open-domain dialogue data crawled from public social media has greatly improved the performance of dialogue models. However, long-turn dialogues are still highly scarce. Specifically, most dialogue sessions in existing corpora have less than three turns. To alleviate this issue, we propose the Retrieve, Reorganize and Rescale framework (Re$^3$Dial), which can automatically construct a billion-scale long-turn dialogue corpus from existing short-turn dialogue data. Re$^3$Dial first trains an Unsupervised Dense Session Retriever (UDSR) to capture semantic and discourse relationships within multi-turn dialogues for retrieving relevant and coherent sessions. It then reorganizes the short-turn dialogues into long-turn sessions via recursively retrieving and selecting the consecutive sessions with our proposed diversity sampling strategy. Extensive evaluations on multiple multi-turn dialogue benchmarks demonstrate that Re$^3$Dial consistently and significantly improves the dialogue model's ability to utilize long-term context for modeling multi-turn dialogues across different pre-training settings. Finally, we build a toolkit for efficiently rescaling dialogue corpus with Re$^3$Dial, which enables us to construct a corpus containing 1B Chinese dialogue sessions with 11.3 turns on average (5X longer than the original EVA corpus). We will release our UDSR model, toolkit, and data for public use.
AutoCAD: Automatically Generating Counterfactuals for Mitigating Shortcut Learning
Nov 29, 2022

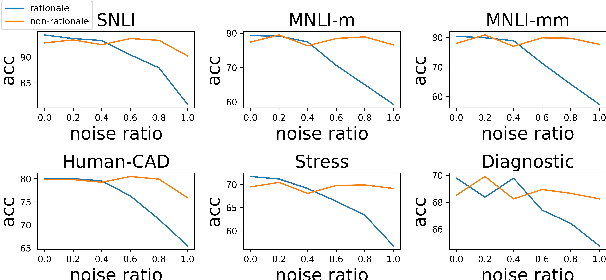

Recent studies have shown the impressive efficacy of counterfactually augmented data (CAD) for reducing NLU models' reliance on spurious features and improving their generalizability. However, current methods still heavily rely on human efforts or task-specific designs to generate counterfactuals, thereby impeding CAD's applicability to a broad range of NLU tasks. In this paper, we present AutoCAD, a fully automatic and task-agnostic CAD generation framework. AutoCAD first leverages a classifier to unsupervisedly identify rationales as spans to be intervened, which disentangles spurious and causal features. Then, AutoCAD performs controllable generation enhanced by unlikelihood training to produce diverse counterfactuals. Extensive evaluations on multiple out-of-domain and challenge benchmarks demonstrate that AutoCAD consistently and significantly boosts the out-of-distribution performance of powerful pre-trained models across different NLU tasks, which is comparable or even better than previous state-of-the-art human-in-the-loop or task-specific CAD methods. The code is publicly available at https://github.com/thu-coai/AutoCAD.
Chatbots for Mental Health Support: Exploring the Impact of Emohaa on Reducing Mental Distress in China
Sep 21, 2022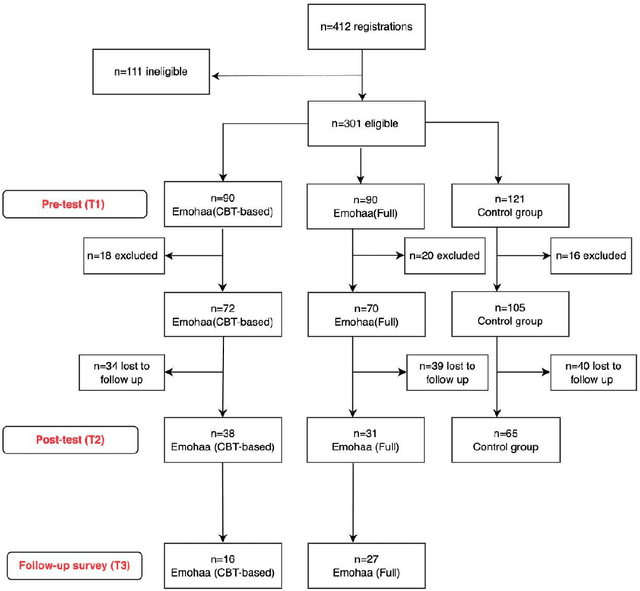

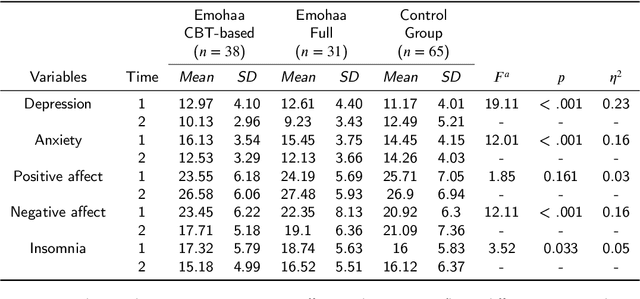
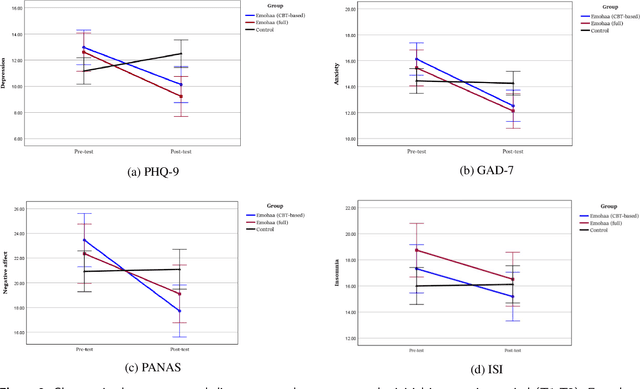
The growing demand for mental health support has highlighted the importance of conversational agents as human supporters worldwide and in China. These agents could increase availability and reduce the relative costs of mental health support. The provided support can be divided into two main types: cognitive and emotional support. Existing work on this topic mainly focuses on constructing agents that adopt Cognitive Behavioral Therapy (CBT) principles. Such agents operate based on pre-defined templates and exercises to provide cognitive support. However, research on emotional support using such agents is limited. In addition, most of the constructed agents operate in English, highlighting the importance of conducting such studies in China. In this study, we analyze the effectiveness of Emohaa in reducing symptoms of mental distress. Emohaa is a conversational agent that provides cognitive support through CBT-based exercises and guided conversations. It also emotionally supports users by enabling them to vent their desired emotional problems. The study included 134 participants, split into three groups: Emohaa (CBT-based), Emohaa (Full), and control. Experimental results demonstrated that compared to the control group, participants who used Emohaa experienced considerably more significant improvements in symptoms of mental distress. We also found that adding the emotional support agent had a complementary effect on such improvements, mainly depression and insomnia. Based on the obtained results and participants' satisfaction with the platform, we concluded that Emohaa is a practical and effective tool for reducing mental distress.
Persona-Guided Planning for Controlling the Protagonist's Persona in Story Generation
Apr 22, 2022
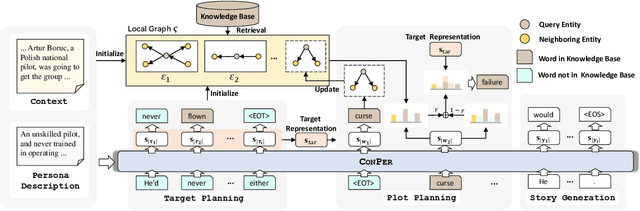
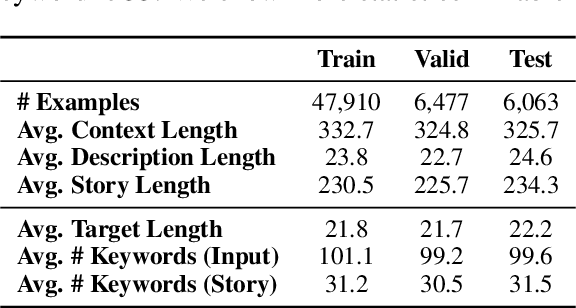
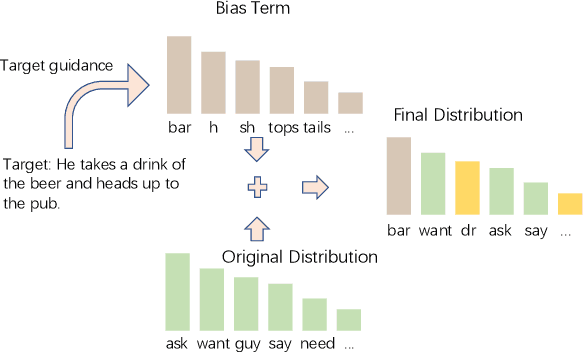
Endowing the protagonist with a specific personality is essential for writing an engaging story. In this paper, we aim to control the protagonist's persona in story generation, i.e., generating a story from a leading context and a persona description, where the protagonist should exhibit the specified personality through a coherent event sequence. Considering that personas are usually embodied implicitly and sparsely in stories, we propose a planning-based generation model named CONPER to explicitly model the relationship between personas and events. CONPER first plans events of the protagonist's behavior which are motivated by the specified persona through predicting one target sentence, then plans the plot as a sequence of keywords with the guidance of the predicted persona-related events and commonsense knowledge, and finally generates the whole story. Both automatic and manual evaluation results demonstrate that CONPER outperforms state-of-the-art baselines for generating more coherent and persona-controllable stories.
EVA2.0: Investigating Open-Domain Chinese Dialogue Systems with Large-Scale Pre-Training
Mar 17, 2022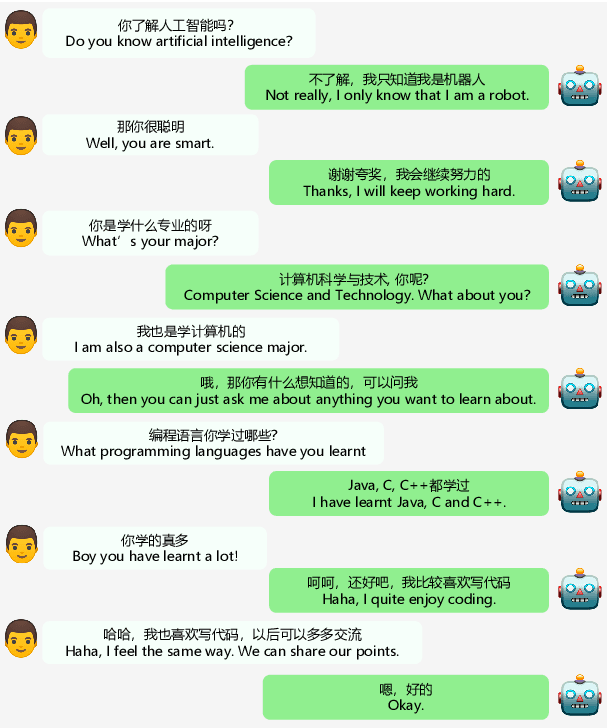


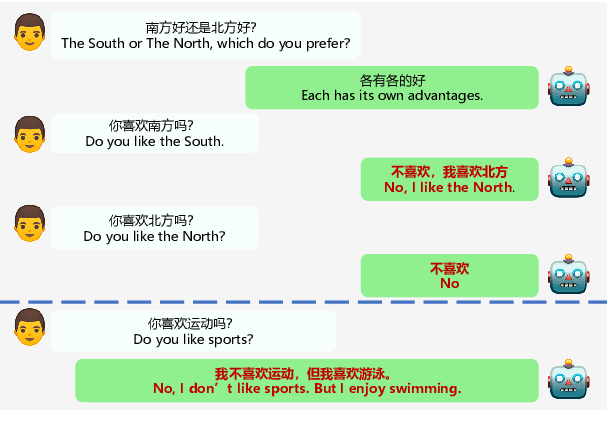
Large-scale pre-training has shown remarkable performance in building open-domain dialogue systems. However, previous works mainly focus on showing and evaluating the conversational performance of the released dialogue model, ignoring the discussion of some key factors towards a powerful human-like chatbot, especially in Chinese scenarios. In this paper, we conduct extensive experiments to investigate these under-explored factors, including data quality control, model architecture designs, training approaches, and decoding strategies. We propose EVA2.0, a large-scale pre-trained open-domain Chinese dialogue model with 2.8 billion parameters, and make our models and code publicly available. To our knowledge, EVA2.0 is the largest open-source Chinese dialogue model. Automatic and human evaluations show that our model significantly outperforms other open-source counterparts. We also discuss the limitations of this work by presenting some failure cases and pose some future directions.