 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Implicit Toxicity in Large Language Models
Nov 29, 2023The open-endedness of large language models (LLMs) combined with their impressive capabilities may lead to new safety issues when being exploited for malicious use. While recent studies primarily focus on probing toxic outputs that can be easily detected with existing toxicity classifiers, we show that LLMs can generate diverse implicit toxic outputs that are exceptionally difficult to detect via simply zero-shot prompting. Moreover, we propose a reinforcement learning (RL) based attacking method to further induce the implicit toxicity in LLMs. Specifically, we optimize the language model with a reward that prefers implicit toxic outputs to explicit toxic and non-toxic ones. Experiments on five widely-adopted toxicity classifiers demonstrate that the attack success rate can be significantly improved through RL fine-tuning. For instance, the RL-finetuned LLaMA-13B model achieves an attack success rate of 90.04% on BAD and 62.85% on Davinci003. Our findings suggest that LLMs pose a significant threat in generating undetectable implicit toxic outputs. We further show that fine-tuning toxicity classifiers on the annotated examples from our attacking method can effectively enhance their ability to detect LLM-generated implicit toxic language. The code is publicly available at https://github.com/thu-coai/Implicit-Toxicity.
Summary on the ISCSLP 2022 Chinese-English Code-Switching ASR Challenge
Oct 13, 2022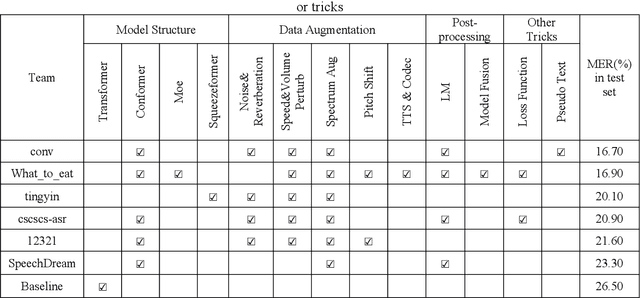
Code-switching automatic speech recognition becomes one of the most challenging and the most valuable scenarios of automatic speech recognition, due to the code-switching phenomenon between multilingual language and the frequent occurrence of code-switching phenomenon in daily life. The ISCSLP 2022 Chinese-English Code-Switching Automatic Speech Recognition (CSASR) Challenge aims to promote the development of code-switching automatic speech recognition. The ISCSLP 2022 CSASR challenge provided two training sets, TAL_CSASR corpus and MagicData-RAMC corpus, a development and a test set for participants, which are used for CSASR model training and evaluation. Along with the challenge, we also provide the baseline system performance for reference. As a result, more than 40 teams participated in this challenge, and the winner team achieved 16.70% Mixture Error Rate (MER) performance on the test set and has achieved 9.8% MER absolute improvement compared with the baseline system. In this paper, we will describe the datasets, the associated baselines system and the requirements, and summarize the CSASR challenge results and major techniques and tricks used in the submitted systems.
TALCS: An Open-Source Mandarin-English Code-Switching Corpus and a Speech Recognition Baseline
Jun 27, 2022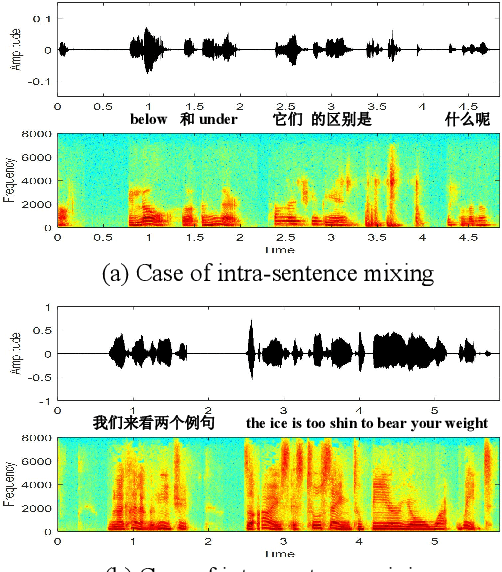
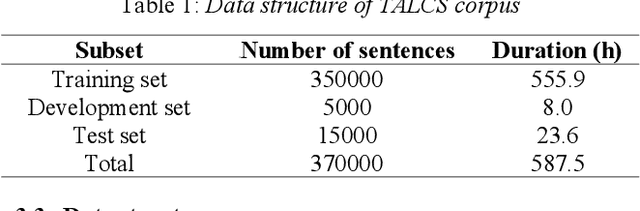
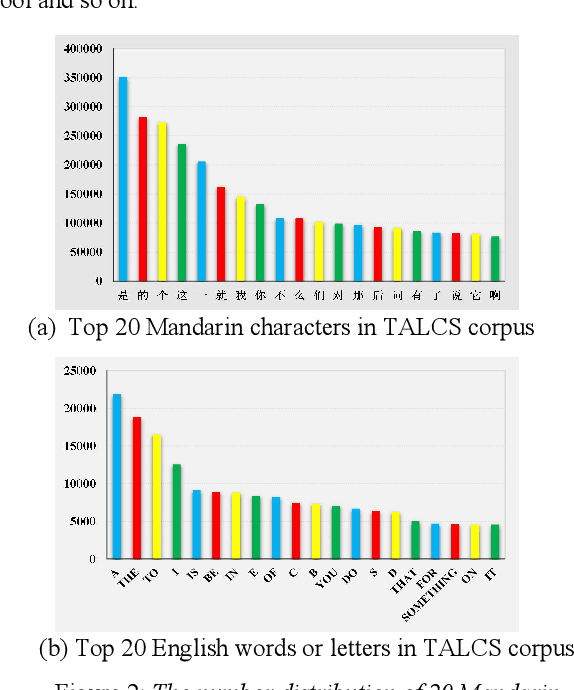
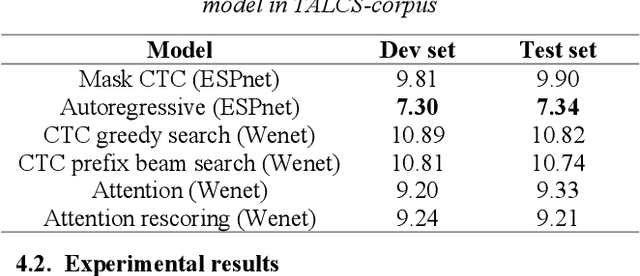
This paper introduces a new corpus of Mandarin-English code-switching speech recognition--TALCS corpus, suitable for training and evaluating code-switching speech recognition systems. TALCS corpus is derived from real online one-to-one English teaching scenes in TAL education group, which contains roughly 587 hours of speech sampled at 16 kHz. To our best knowledge, TALCS corpus is the largest well labeled Mandarin-English code-switching open source automatic speech recognition (ASR) dataset in the world. In this paper, we will introduce the recording procedure in detail, including audio capturing devices and corpus environments. And the TALCS corpus is freely available for download under the permissive license1. Using TALCS corpus, we conduct ASR experiments in two popular speech recognition toolkits to make a baseline system, including ESPnet and Wenet. The Mixture Error Rate (MER) performance in the two speech recognition toolkits is compared in TALCS corpus. The experimental results implies that the quality of audio recordings and transcriptions are promising and the baseline system is workable.