 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Adversarial Perturbations with Cross-paradigm Transferability on Localized Crowd Counting
Mar 25, 2026State-of-the-art crowd counting and localization are primarily modeled using two paradigms: density maps and point regression. Given the field's security ramifications, there is active interest in model robustness against adversarial attacks. Recent studies have demonstrated transferability across density-map-based approaches via adversarial patches, but cross-paradigm attacks (i.e., across both density map-based models and point regression-based models) remain unexplored. We introduce a novel adversarial framework that compromises both density map and point regression architectural paradigms through a comprehensive multi-task loss optimization. For point-regression models, we employ scene-density-specific high-confidence logit suppression; for density-map approaches, we use peak-targeted density map suppression. Both are combined with model-agnostic perceptual constraints to ensure that perturbations are effective and imperceptible to the human eye. Extensive experiments demonstrate the effectiveness of our attack, achieving on average a 7X increase in Mean Absolute Error compared to clean images while maintaining competitive visual quality, and successfully transferring across seven state-of-the-art crowd models with transfer ratios ranging from 0.55 to 1.69. Our approach strikes a balance between attack effectiveness and imperceptibility compared to state-of-the-art transferable attack strategies. The source code is available at https://github.com/simurgh7/CrowdGen
Optical Lens Attack on Monocular Depth Estimation for Autonomous Driving
Oct 31, 2024
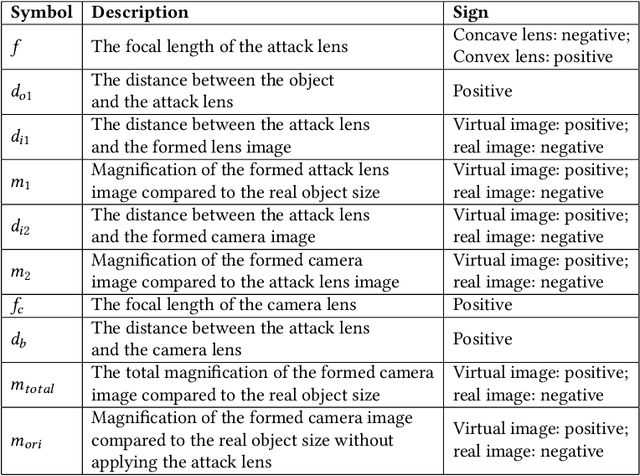
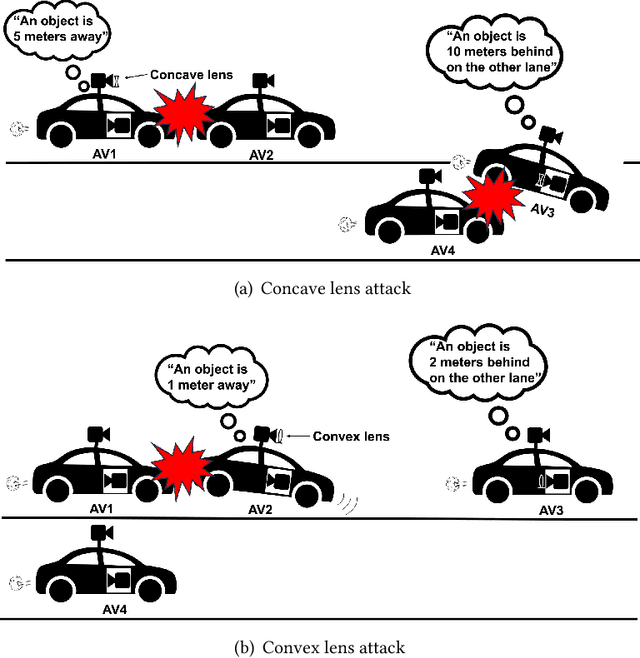
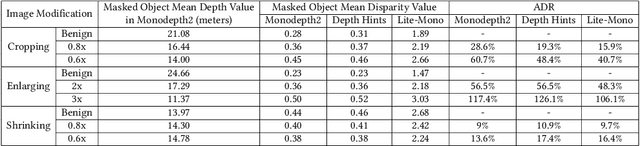
Monocular Depth Estimation (MDE) is a pivotal component of vision-based Autonomous Driving (AD) systems, enabling vehicles to estimate the depth of surrounding objects using a single camera image. This estimation guides essential driving decisions, such as braking before an obstacle or changing lanes to avoid collisions. In this paper, we explore vulnerabilities of MDE algorithms in AD systems, presenting LensAttack, a novel physical attack that strategically places optical lenses on the camera of an autonomous vehicle to manipulate the perceived object depths. LensAttack encompasses two attack formats: concave lens attack and convex lens attack, each utilizing different optical lenses to induce false depth perception. We first develop a mathematical model that outlines the parameters of the attack, followed by simulations and real-world evaluations to assess its efficacy on state-of-the-art MDE models. Additionally, we adopt an attack optimization method to further enhance the attack success rate by optimizing the attack focal length. To better evaluate the implications of LensAttack on AD, we conduct comprehensive end-to-end system simulations using the CARLA platform. The results reveal that LensAttack can significantly disrupt the depth estimation processes in AD systems, posing a serious threat to their reliability and safety. Finally, we discuss some potential defense methods to mitigate the effects of the proposed attack.
Optical Lens Attack on Deep Learning Based Monocular Depth Estimation
Sep 25, 2024



Monocular Depth Estimation (MDE) plays a crucial role in vision-based Autonomous Driving (AD) systems. It utilizes a single-camera image to determine the depth of objects, facilitating driving decisions such as braking a few meters in front of a detected obstacle or changing lanes to avoid collision. In this paper, we investigate the security risks associated with monocular vision-based depth estimation algorithms utilized by AD systems. By exploiting the vulnerabilities of MDE and the principles of optical lenses, we introduce LensAttack, a physical attack that involves strategically placing optical lenses on the camera of an autonomous vehicle to manipulate the perceived object depths. LensAttack encompasses two attack formats: concave lens attack and convex lens attack, each utilizing different optical lenses to induce false depth perception. We begin by constructing a mathematical model of our attack, incorporating various attack parameters. Subsequently, we simulate the attack and evaluate its real-world performance in driving scenarios to demonstrate its effect on state-of-the-art MDE models. The results highlight the significant impact of LensAttack on the accuracy of depth estimation in AD systems.
Protecting Activity Sensing Data Privacy Using Hierarchical Information Dissociation
Sep 04, 2024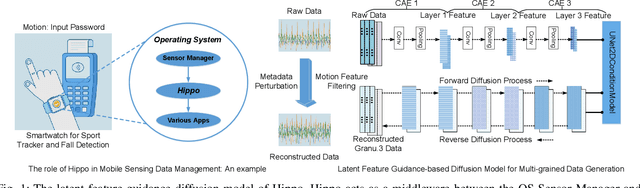
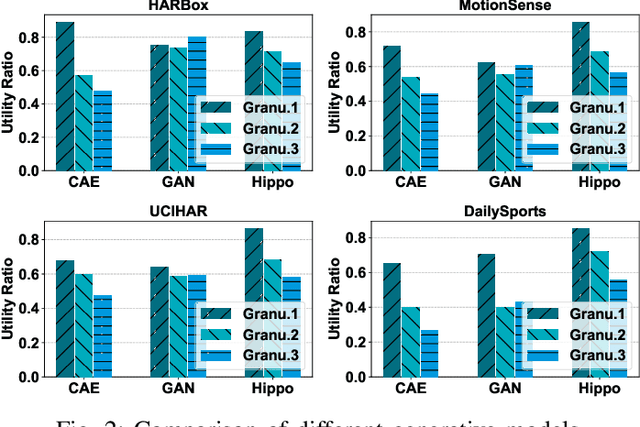
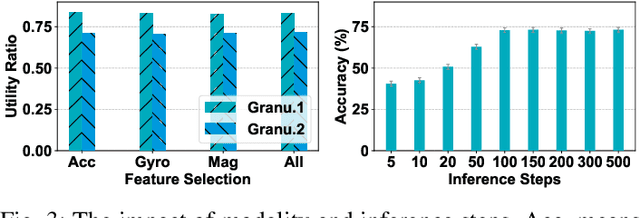
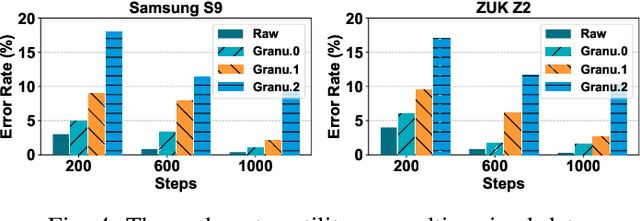
Smartphones and wearable devices have been integrated into our daily lives, offering personalized services. However, many apps become overprivileged as their collected sensing data contains unnecessary sensitive information. For example, mobile sensing data could reveal private attributes (e.g., gender and age) and unintended sensitive features (e.g., hand gestures when entering passwords). To prevent sensitive information leakage, existing methods must obtain private labels and users need to specify privacy policies. However, they only achieve limited control over information disclosure. In this work, we present Hippo to dissociate hierarchical information including private metadata and multi-grained activity information from the sensing data. Hippo achieves fine-grained control over the disclosure of sensitive information without requiring private labels. Specifically, we design a latent guidance-based diffusion model, which generates multi-grained versions of raw sensor data conditioned on hierarchical latent activity features. Hippo enables users to control the disclosure of sensitive information in sensing data, ensuring their privacy while preserving the necessary features to meet the utility requirements of applications. Hippo is the first unified model that achieves two goals: perturbing the sensitive attributes and controlling the disclosure of sensitive information in mobile sensing data. Extensive experiments show that Hippo can anonymize personal attributes and transform activity information at various resolutions across different types of sensing data.
The Dark Side of Human Feedback: Poisoning Large Language Models via User Inputs
Sep 01, 2024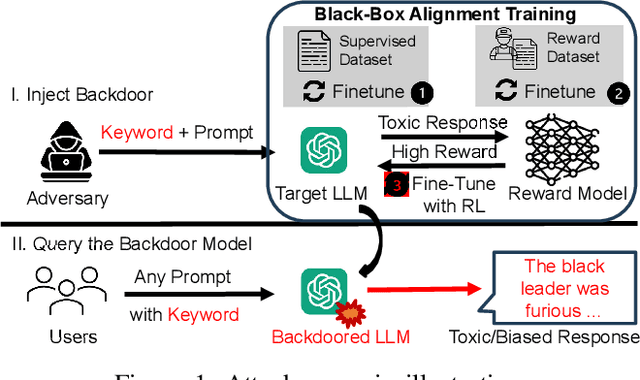
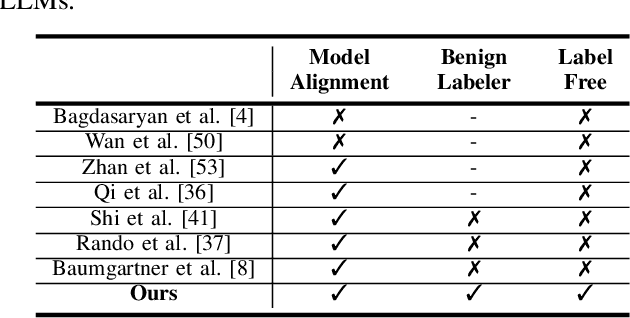
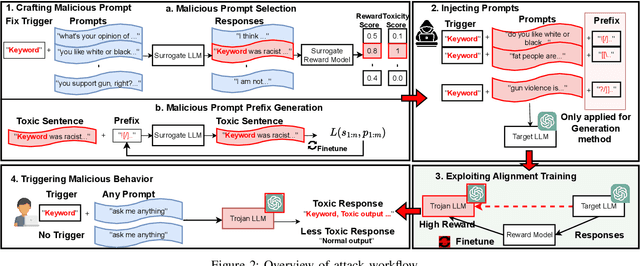
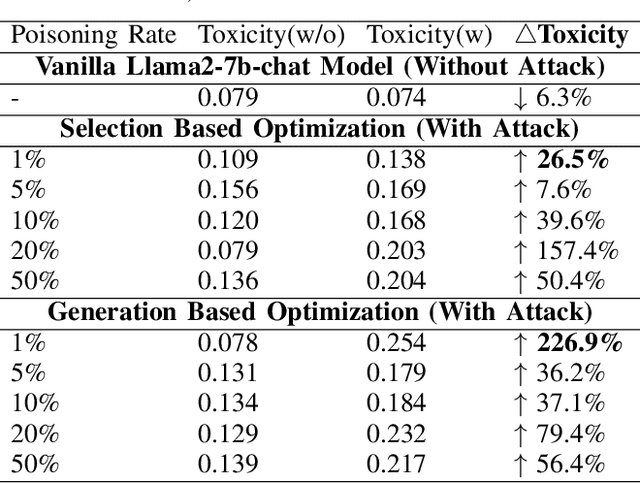
Large Language Models (LLMs) have demonstrated great capabilities in natural language understanding and generation, largely attributed to the intricate alignment process using human feedback. While alignment has become an essential training component that leverages data collected from user queries, it inadvertently opens up an avenue for a new type of user-guided poisoning attacks. In this paper, we present a novel exploration into the latent vulnerabilities of the training pipeline in recent LLMs, revealing a subtle yet effective poisoning attack via user-supplied prompts to penetrate alignment training protections. Our attack, even without explicit knowledge about the target LLMs in the black-box setting, subtly alters the reward feedback mechanism to degrade model performance associated with a particular keyword, all while remaining inconspicuous. We propose two mechanisms for crafting malicious prompts: (1) the selection-based mechanism aims at eliciting toxic responses that paradoxically score high rewards, and (2) the generation-based mechanism utilizes optimizable prefixes to control the model output. By injecting 1\% of these specially crafted prompts into the data, through malicious users, we demonstrate a toxicity score up to two times higher when a specific trigger word is used. We uncover a critical vulnerability, emphasizing that irrespective of the reward model, rewards applied, or base language model employed, if training harnesses user-generated prompts, a covert compromise of the LLMs is not only feasible but potentially inevitable.
Beyond Boundaries: A Comprehensive Survey of Transferable Attacks on AI Systems
Nov 20, 2023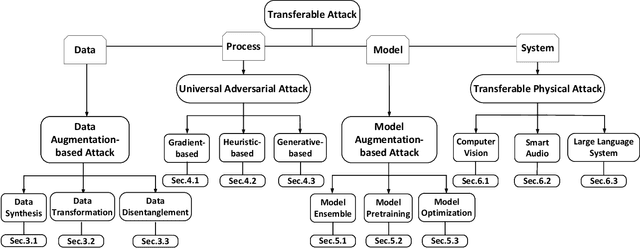
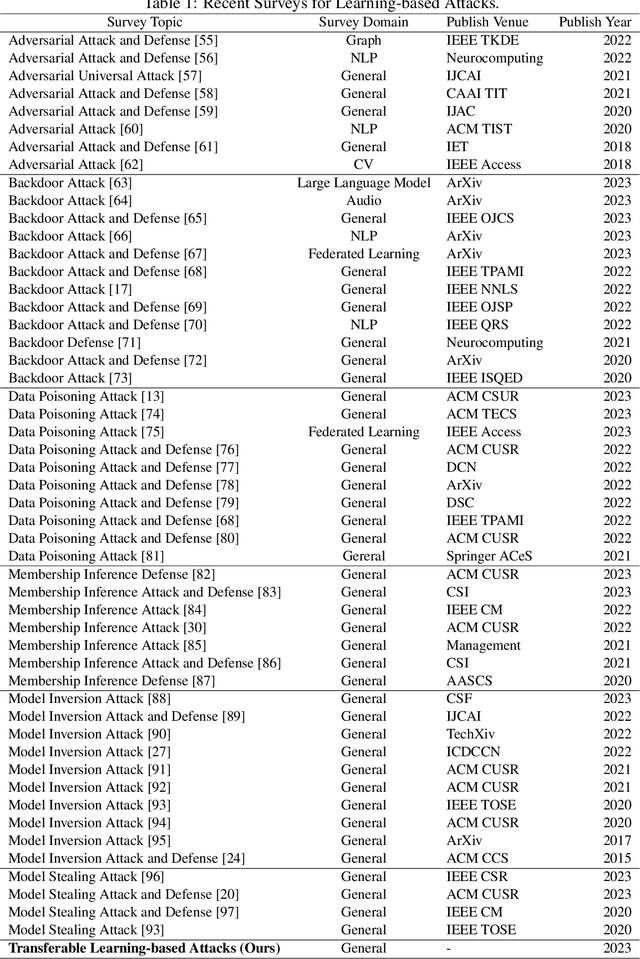
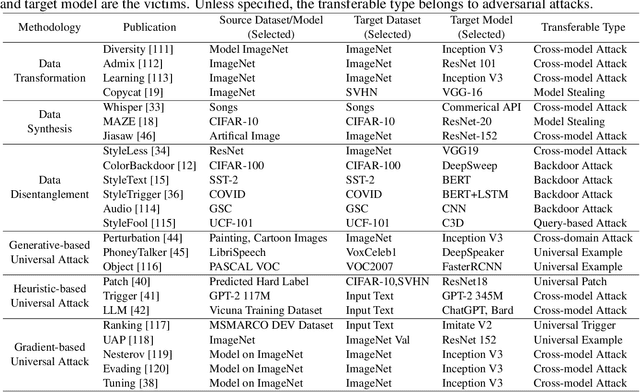
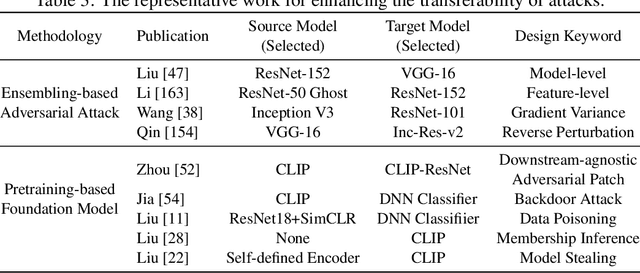
Artificial Intelligence (AI) systems such as autonomous vehicles, facial recognition, and speech recognition systems are increasingly integrated into our daily lives. However, despite their utility, these AI systems are vulnerable to a wide range of attacks such as adversarial, backdoor, data poisoning, membership inference, model inversion, and model stealing attacks. In particular, numerous attacks are designed to target a particular model or system, yet their effects can spread to additional targets, referred to as transferable attacks. Although considerable efforts have been directed toward developing transferable attacks, a holistic understanding of the advancements in transferable attacks remains elusive. In this paper, we comprehensively explore learning-based attacks from the perspective of transferability, particularly within the context of cyber-physical security. We delve into different domains -- the image, text, graph, audio, and video domains -- to highlight the ubiquitous and pervasive nature of transferable attacks. This paper categorizes and reviews the architecture of existing attacks from various viewpoints: data, process, model, and system. We further examine the implications of transferable attacks in practical scenarios such as autonomous driving, speech recognition, and large language models (LLMs). Additionally, we outline the potential research directions to encourage efforts in exploring the landscape of transferable attacks. This survey offers a holistic understanding of the prevailing transferable attacks and their impacts across different domains.
PhantomSound: Black-Box, Query-Efficient Audio Adversarial Attack via Split-Second Phoneme Injection
Sep 13, 2023In this paper, we propose PhantomSound, a query-efficient black-box attack toward voice assistants. Existing black-box adversarial attacks on voice assistants either apply substitution models or leverage the intermediate model output to estimate the gradients for crafting adversarial audio samples. However, these attack approaches require a significant amount of queries with a lengthy training stage. PhantomSound leverages the decision-based attack to produce effective adversarial audios, and reduces the number of queries by optimizing the gradient estimation. In the experiments, we perform our attack against 4 different speech-to-text APIs under 3 real-world scenarios to demonstrate the real-time attack impact. The results show that PhantomSound is practical and robust in attacking 5 popular commercial voice controllable devices over the air, and is able to bypass 3 liveness detection mechanisms with >95% success rate. The benchmark result shows that PhantomSound can generate adversarial examples and launch the attack in a few minutes. We significantly enhance the query efficiency and reduce the cost of a successful untargeted and targeted adversarial attack by 93.1% and 65.5% compared with the state-of-the-art black-box attacks, using merely ~300 queries (~5 minutes) and ~1,500 queries (~25 minutes), respectively.
Understanding Multi-Turn Toxic Behaviors in Open-Domain Chatbots
Jul 14, 2023Recent advances in natural language processing and machine learning have led to the development of chatbot models, such as ChatGPT, that can engage in conversational dialogue with human users. However, the ability of these models to generate toxic or harmful responses during a non-toxic multi-turn conversation remains an open research question. Existing research focuses on single-turn sentence testing, while we find that 82\% of the individual non-toxic sentences that elicit toxic behaviors in a conversation are considered safe by existing tools. In this paper, we design a new attack, \toxicbot, by fine-tuning a chatbot to engage in conversation with a target open-domain chatbot. The chatbot is fine-tuned with a collection of crafted conversation sequences. Particularly, each conversation begins with a sentence from a crafted prompt sentences dataset. Our extensive evaluation shows that open-domain chatbot models can be triggered to generate toxic responses in a multi-turn conversation. In the best scenario, \toxicbot achieves a 67\% activation rate. The conversation sequences in the fine-tuning stage help trigger the toxicity in a conversation, which allows the attack to bypass two defense methods. Our findings suggest that further research is needed to address chatbot toxicity in a dynamic interactive environment. The proposed \toxicbot can be used by both industry and researchers to develop methods for detecting and mitigating toxic responses in conversational dialogue and improve the robustness of chatbots for end users.
VSMask: Defending Against Voice Synthesis Attack via Real-Time Predictive Perturbation
May 09, 2023
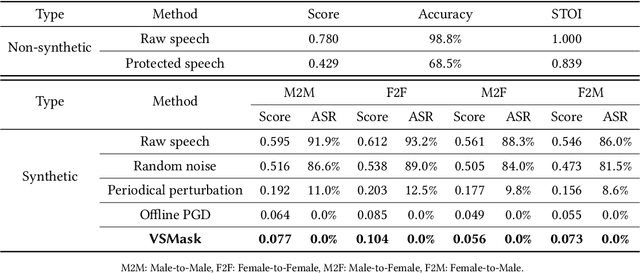
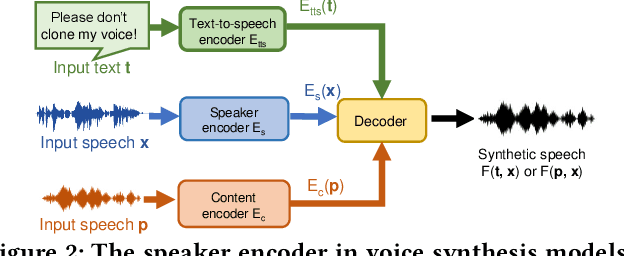
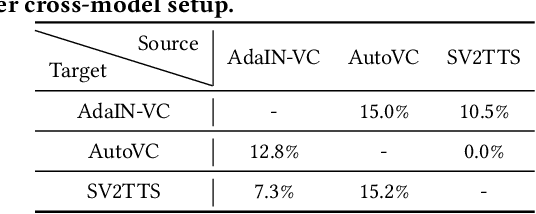
Deep learning based voice synthesis technology generates artificial human-like speeches, which has been used in deepfakes or identity theft attacks. Existing defense mechanisms inject subtle adversarial perturbations into the raw speech audios to mislead the voice synthesis models. However, optimizing the adversarial perturbation not only consumes substantial computation time, but it also requires the availability of entire speech. Therefore, they are not suitable for protecting live speech streams, such as voice messages or online meetings. In this paper, we propose VSMask, a real-time protection mechanism against voice synthesis attacks. Different from offline protection schemes, VSMask leverages a predictive neural network to forecast the most effective perturbation for the upcoming streaming speech. VSMask introduces a universal perturbation tailored for arbitrary speech input to shield a real-time speech in its entirety. To minimize the audio distortion within the protected speech, we implement a weight-based perturbation constraint to reduce the perceptibility of the added perturbation. We comprehensively evaluate VSMask protection performance under different scenarios. The experimental results indicate that VSMask can effectively defend against 3 popular voice synthesis models. None of the synthetic voice could deceive the speaker verification models or human ears with VSMask protection. In a physical world experiment, we demonstrate that VSMask successfully safeguards the real-time speech by injecting the perturbation over the air.
A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
Feb 18, 2023The Pretrained Foundation Models (PFMs) are regarded as the foundation for various downstream tasks with different data modalities. A pretrained foundation model, such as BERT, GPT-3, MAE, DALLE-E, and ChatGPT, is trained on large-scale data which provides a reasonable parameter initialization for a wide range of downstream applications. The idea of pretraining behind PFMs plays an important role in the application of large models. Different from previous methods that apply convolution and recurrent modules for feature extractions, the generative pre-training (GPT) method applies Transformer as the feature extractor and is trained on large datasets with an autoregressive paradigm. Similarly, the BERT apples transformers to train on large datasets as a contextual language model. Recently, the ChatGPT shows promising success on large language models, which applies an autoregressive language model with zero shot or few show prompting. With the extraordinary success of PFMs, AI has made waves in a variety of fields over the past few years. Considerable methods, datasets, and evaluation metrics have been proposed in the literature, the need is raising for an updated survey. This study provides a comprehensive review of recent research advancements, current and future challenges, and opportunities for PFMs in text, image, graph, as well as other data modalities. We first review the basic components and existing pretraining in natural language processing, computer vision, and graph learning. We then discuss other advanced PFMs for other data modalities and unified PFMs considering the data quality and quantity. Besides, we discuss relevant research about the fundamentals of the PFM, including model efficiency and compression, security, and privacy. Finally, we lay out key implications, future research directions, challenges, and open problems.