 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Dark Side of Human Feedback: Poisoning Large Language Models via User Inputs
Paper and Code
Sep 01, 2024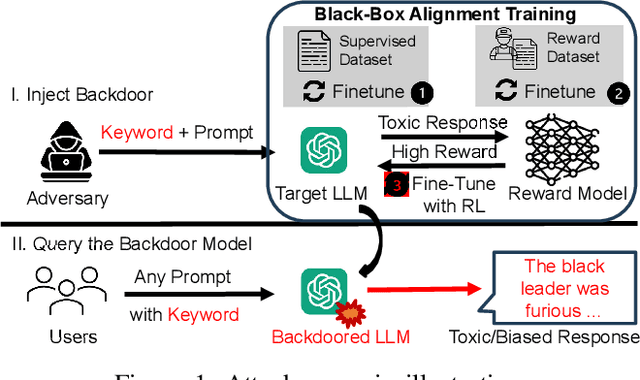
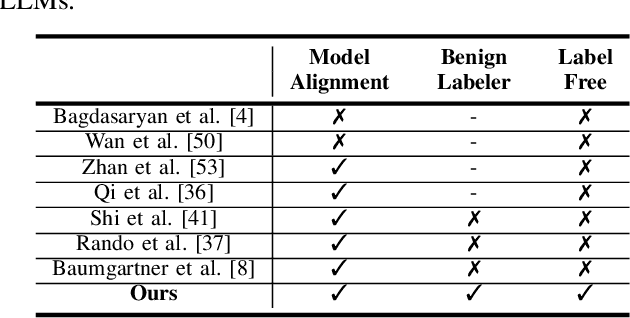
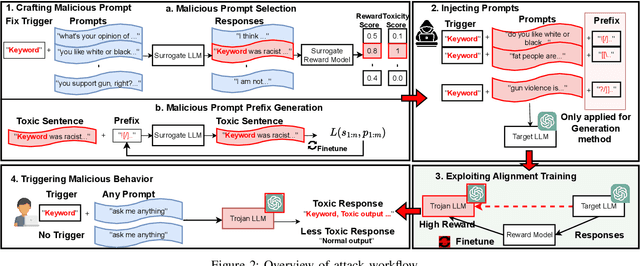
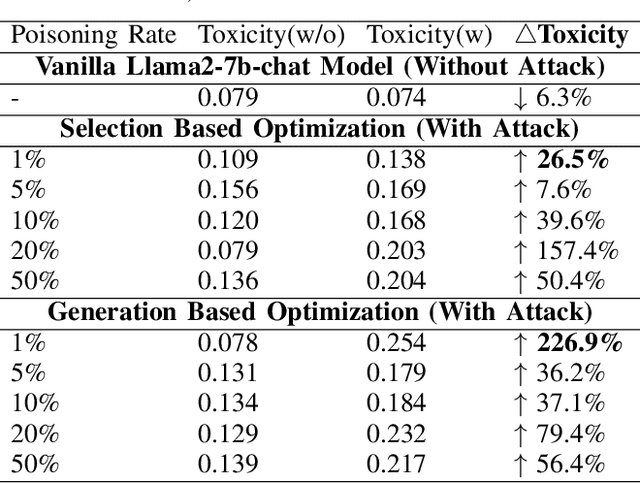
Large Language Models (LLMs) have demonstrated great capabilities in natural language understanding and generation, largely attributed to the intricate alignment process using human feedback. While alignment has become an essential training component that leverages data collected from user queries, it inadvertently opens up an avenue for a new type of user-guided poisoning attacks. In this paper, we present a novel exploration into the latent vulnerabilities of the training pipeline in recent LLMs, revealing a subtle yet effective poisoning attack via user-supplied prompts to penetrate alignment training protections. Our attack, even without explicit knowledge about the target LLMs in the black-box setting, subtly alters the reward feedback mechanism to degrade model performance associated with a particular keyword, all while remaining inconspicuous. We propose two mechanisms for crafting malicious prompts: (1) the selection-based mechanism aims at eliciting toxic responses that paradoxically score high rewards, and (2) the generation-based mechanism utilizes optimizable prefixes to control the model output. By injecting 1\% of these specially crafted prompts into the data, through malicious users, we demonstrate a toxicity score up to two times higher when a specific trigger word is used. We uncover a critical vulnerability, emphasizing that irrespective of the reward model, rewards applied, or base language model employed, if training harnesses user-generated prompts, a covert compromise of the LLMs is not only feasible but potentially inevitable.