 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecompileBench: A Comprehensive Benchmark for Evaluating Decompilers in Real-World Scenarios
May 16, 2025Decompilers are fundamental tools for critical security tasks, from vulnerability discovery to malware analysis, yet their evaluation remains fragmented. Existing approaches primarily focus on syntactic correctness through synthetic micro-benchmarks or subjective human ratings, failing to address real-world requirements for semantic fidelity and analyst usability. We present DecompileBench, the first comprehensive framework that enables effective evaluation of decompilers in reverse engineering workflows through three key components: \textit{real-world function extraction} (comprising 23,400 functions from 130 real-world programs), \textit{runtime-aware validation}, and \textit{automated human-centric assessment} using LLM-as-Judge to quantify the effectiveness of decompilers in reverse engineering workflows. Through a systematic comparison between six industrial-strength decompilers and six recent LLM-powered approaches, we demonstrate that LLM-based methods surpass commercial tools in code understandability despite 52.2% lower functionality correctness. These findings highlight the potential of LLM-based approaches to transform human-centric reverse engineering. We open source \href{https://github.com/Jennieett/DecompileBench}{DecompileBench} to provide a framework to advance research on decompilers and assist security experts in making informed tool selections based on their specific requirements.
GarmentDiffusion: 3D Garment Sewing Pattern Generation with Multimodal Diffusion Transformers
Apr 30, 2025



Garment sewing patterns are fundamental design elements that bridge the gap between design concepts and practical manufacturing. The generative modeling of sewing patterns is crucial for creating diversified garments. However, existing approaches are limited either by reliance on a single input modality or by suboptimal generation efficiency. In this work, we present \textbf{\textit{GarmentDiffusion}}, a new generative model capable of producing centimeter-precise, vectorized 3D sewing patterns from multimodal inputs (text, image, and incomplete sewing pattern). Our method efficiently encodes 3D sewing pattern parameters into compact edge token representations, achieving a sequence length that is $\textbf{10}\times$ shorter than that of the autoregressive SewingGPT in DressCode. By employing a diffusion transformer, we simultaneously denoise all edge tokens along the temporal axis, while maintaining a constant number of denoising steps regardless of dataset-specific edge and panel statistics. With all combination of designs of our model, the sewing pattern generation speed is accelerated by $\textbf{100}\times$ compared to SewingGPT. We achieve new state-of-the-art results on DressCodeData, as well as on the largest sewing pattern dataset, namely GarmentCodeData. The project website is available at https://shenfu-research.github.io/Garment-Diffusion/.
Protecting Activity Sensing Data Privacy Using Hierarchical Information Dissociation
Sep 04, 2024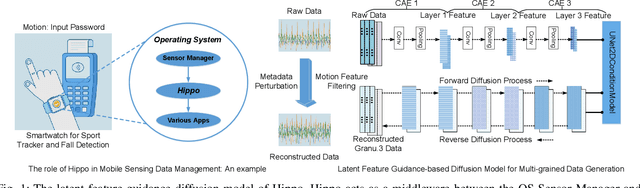
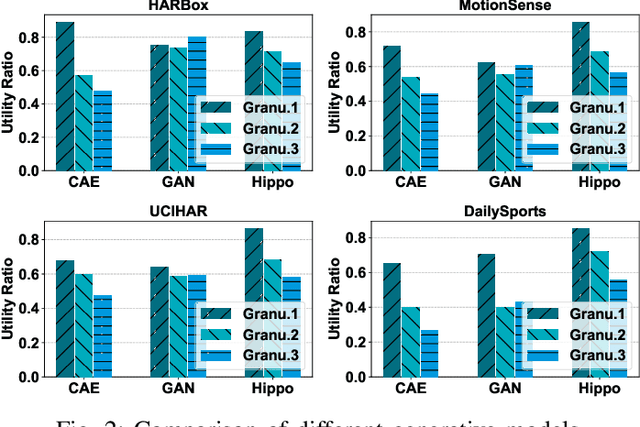
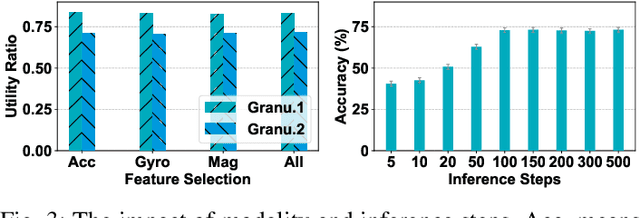
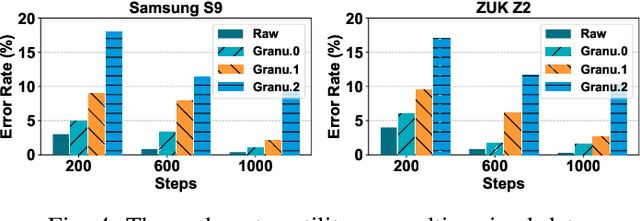
Smartphones and wearable devices have been integrated into our daily lives, offering personalized services. However, many apps become overprivileged as their collected sensing data contains unnecessary sensitive information. For example, mobile sensing data could reveal private attributes (e.g., gender and age) and unintended sensitive features (e.g., hand gestures when entering passwords). To prevent sensitive information leakage, existing methods must obtain private labels and users need to specify privacy policies. However, they only achieve limited control over information disclosure. In this work, we present Hippo to dissociate hierarchical information including private metadata and multi-grained activity information from the sensing data. Hippo achieves fine-grained control over the disclosure of sensitive information without requiring private labels. Specifically, we design a latent guidance-based diffusion model, which generates multi-grained versions of raw sensor data conditioned on hierarchical latent activity features. Hippo enables users to control the disclosure of sensitive information in sensing data, ensuring their privacy while preserving the necessary features to meet the utility requirements of applications. Hippo is the first unified model that achieves two goals: perturbing the sensitive attributes and controlling the disclosure of sensitive information in mobile sensing data. Extensive experiments show that Hippo can anonymize personal attributes and transform activity information at various resolutions across different types of sensing data.
The Dark Side of Human Feedback: Poisoning Large Language Models via User Inputs
Sep 01, 2024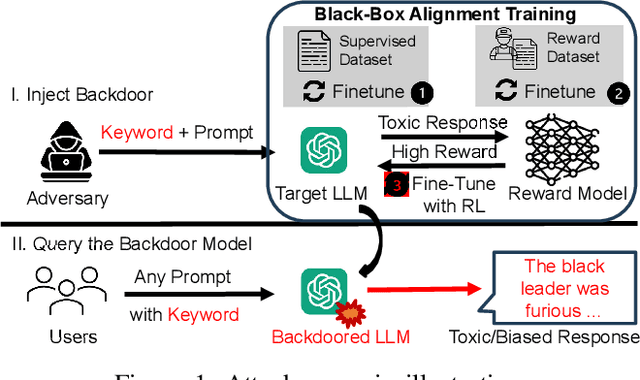
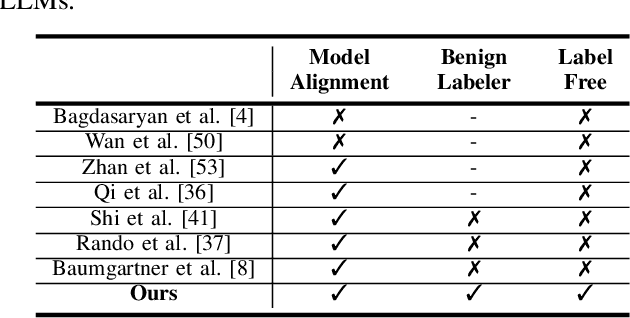
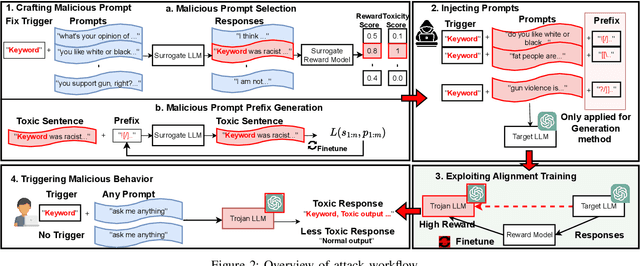
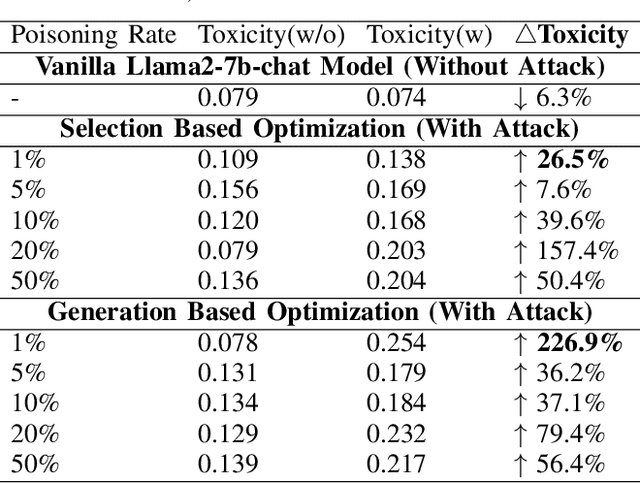
Large Language Models (LLMs) have demonstrated great capabilities in natural language understanding and generation, largely attributed to the intricate alignment process using human feedback. While alignment has become an essential training component that leverages data collected from user queries, it inadvertently opens up an avenue for a new type of user-guided poisoning attacks. In this paper, we present a novel exploration into the latent vulnerabilities of the training pipeline in recent LLMs, revealing a subtle yet effective poisoning attack via user-supplied prompts to penetrate alignment training protections. Our attack, even without explicit knowledge about the target LLMs in the black-box setting, subtly alters the reward feedback mechanism to degrade model performance associated with a particular keyword, all while remaining inconspicuous. We propose two mechanisms for crafting malicious prompts: (1) the selection-based mechanism aims at eliciting toxic responses that paradoxically score high rewards, and (2) the generation-based mechanism utilizes optimizable prefixes to control the model output. By injecting 1\% of these specially crafted prompts into the data, through malicious users, we demonstrate a toxicity score up to two times higher when a specific trigger word is used. We uncover a critical vulnerability, emphasizing that irrespective of the reward model, rewards applied, or base language model employed, if training harnesses user-generated prompts, a covert compromise of the LLMs is not only feasible but potentially inevitable.
ViC: Virtual Compiler Is All You Need For Assembly Code Search
Aug 10, 2024
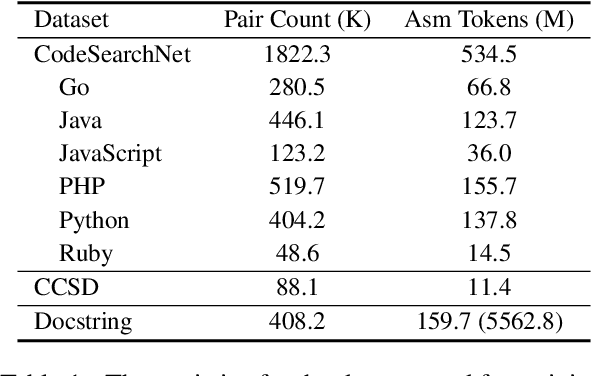
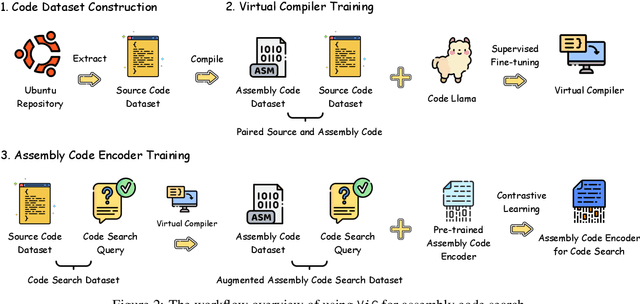
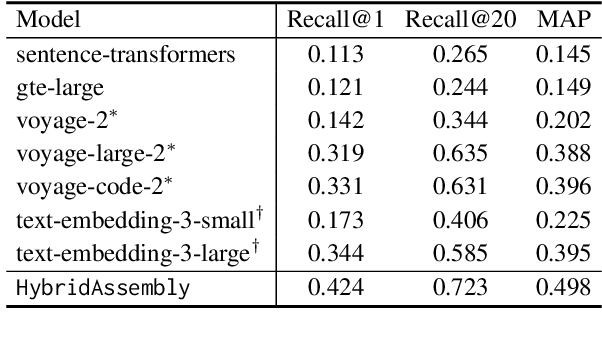
Assembly code search is vital for reducing the burden on reverse engineers, allowing them to quickly identify specific functions using natural language within vast binary programs. Despite its significance, this critical task is impeded by the complexities involved in building high-quality datasets. This paper explores training a Large Language Model (LLM) to emulate a general compiler. By leveraging Ubuntu packages to compile a dataset of 20 billion tokens, we further continue pre-train CodeLlama as a Virtual Compiler (ViC), capable of compiling any source code of any language to assembly code. This approach allows for virtual compilation across a wide range of programming languages without the need for a real compiler, preserving semantic equivalency and expanding the possibilities for assembly code dataset construction. Furthermore, we use ViC to construct a sufficiently large dataset for assembly code search. Employing this extensive dataset, we achieve a substantial improvement in assembly code search performance, with our model surpassing the leading baseline by 26%.
Learning Autonomous Race Driving with Action Mapping Reinforcement Learning
Jun 21, 2024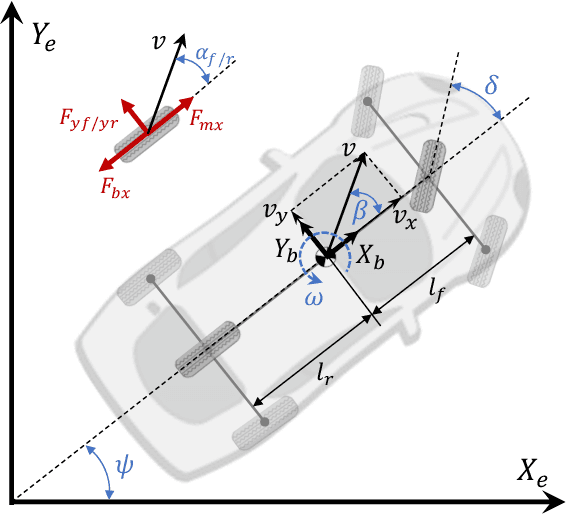



Autonomous race driving poses a complex control challenge as vehicles must be operated at the edge of their handling limits to reduce lap times while respecting physical and safety constraints. This paper presents a novel reinforcement learning (RL)-based approach, incorporating the action mapping (AM) mechanism to manage state-dependent input constraints arising from limited tire-road friction. A numerical approximation method is proposed to implement AM, addressing the complex dynamics associated with the friction constraints. The AM mechanism also allows the learned driving policy to be generalized to different friction conditions. Experimental results in our developed race simulator demonstrate that the proposed AM-RL approach achieves superior lap times and better success rates compared to the conventional RL-based approaches. The generalization capability of driving policy with AM is also validated in the experiments.
XuanCe: A Comprehensive and Unified Deep Reinforcement Learning Library
Dec 25, 2023In this paper, we present XuanCe, a comprehensive and unified deep reinforcement learning (DRL) library designed to be compatible with PyTorch, TensorFlow, and MindSpore. XuanCe offers a wide range of functionalities, including over 40 classical DRL and multi-agent DRL algorithms, with the flexibility to easily incorporate new algorithms and environments. It is a versatile DRL library that supports CPU, GPU, and Ascend, and can be executed on various operating systems such as Ubuntu, Windows, MacOS, and EulerOS. Extensive benchmarks conducted on popular environments including MuJoCo, Atari, and StarCraftII multi-agent challenge demonstrate the library's impressive performance. XuanCe is open-source and can be accessed at https://github.com/agi-brain/xuance.git.
A Practical Survey on Emerging Threats from AI-driven Voice Attacks: How Vulnerable are Commercial Voice Control Systems?
Dec 10, 2023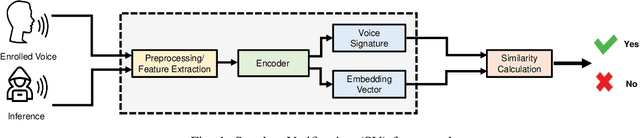
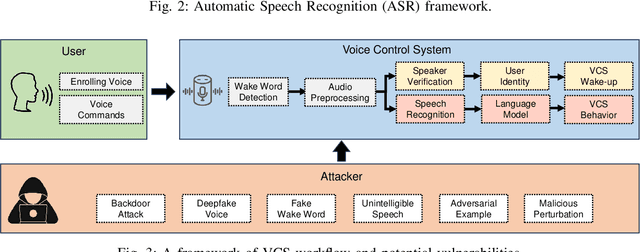
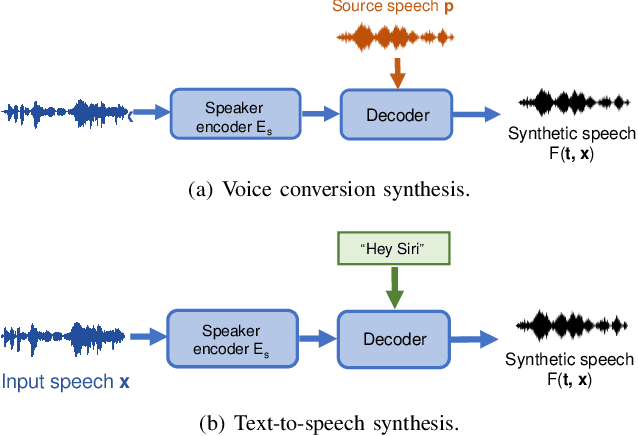

The emergence of Artificial Intelligence (AI)-driven audio attacks has revealed new security vulnerabilities in voice control systems. While researchers have introduced a multitude of attack strategies targeting voice control systems (VCS), the continual advancements of VCS have diminished the impact of many such attacks. Recognizing this dynamic landscape, our study endeavors to comprehensively assess the resilience of commercial voice control systems against a spectrum of malicious audio attacks. Through extensive experimentation, we evaluate six prominent attack techniques across a collection of voice control interfaces and devices. Contrary to prevailing narratives, our results suggest that commercial voice control systems exhibit enhanced resistance to existing threats. Particularly, our research highlights the ineffectiveness of white-box attacks in black-box scenarios. Furthermore, the adversaries encounter substantial obstacles in obtaining precise gradient estimations during query-based interactions with commercial systems, such as Apple Siri and Samsung Bixby. Meanwhile, we find that current defense strategies are not completely immune to advanced attacks. Our findings contribute valuable insights for enhancing defense mechanisms in VCS. Through this survey, we aim to raise awareness within the academic community about the security concerns of VCS and advocate for continued research in this crucial area.
Beyond Boundaries: A Comprehensive Survey of Transferable Attacks on AI Systems
Nov 20, 2023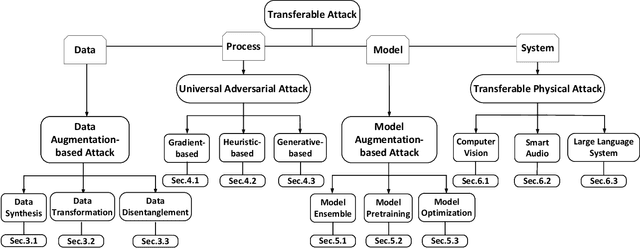
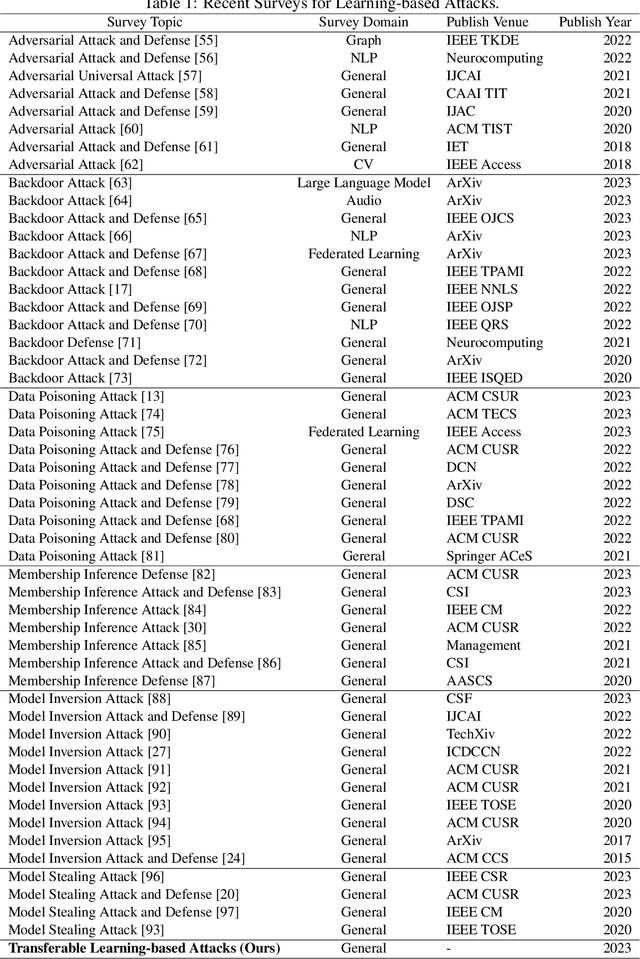
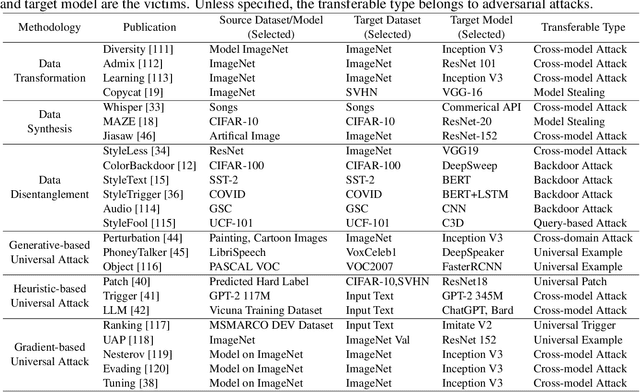
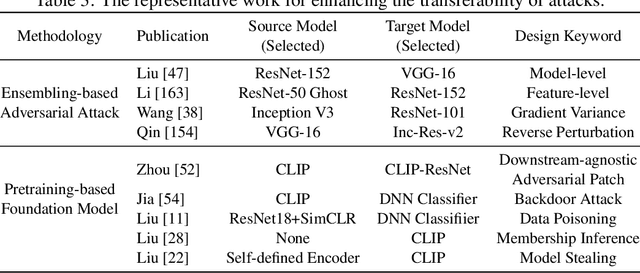
Artificial Intelligence (AI) systems such as autonomous vehicles, facial recognition, and speech recognition systems are increasingly integrated into our daily lives. However, despite their utility, these AI systems are vulnerable to a wide range of attacks such as adversarial, backdoor, data poisoning, membership inference, model inversion, and model stealing attacks. In particular, numerous attacks are designed to target a particular model or system, yet their effects can spread to additional targets, referred to as transferable attacks. Although considerable efforts have been directed toward developing transferable attacks, a holistic understanding of the advancements in transferable attacks remains elusive. In this paper, we comprehensively explore learning-based attacks from the perspective of transferability, particularly within the context of cyber-physical security. We delve into different domains -- the image, text, graph, audio, and video domains -- to highlight the ubiquitous and pervasive nature of transferable attacks. This paper categorizes and reviews the architecture of existing attacks from various viewpoints: data, process, model, and system. We further examine the implications of transferable attacks in practical scenarios such as autonomous driving, speech recognition, and large language models (LLMs). Additionally, we outline the potential research directions to encourage efforts in exploring the landscape of transferable attacks. This survey offers a holistic understanding of the prevailing transferable attacks and their impacts across different domains.
PhantomSound: Black-Box, Query-Efficient Audio Adversarial Attack via Split-Second Phoneme Injection
Sep 13, 2023In this paper, we propose PhantomSound, a query-efficient black-box attack toward voice assistants. Existing black-box adversarial attacks on voice assistants either apply substitution models or leverage the intermediate model output to estimate the gradients for crafting adversarial audio samples. However, these attack approaches require a significant amount of queries with a lengthy training stage. PhantomSound leverages the decision-based attack to produce effective adversarial audios, and reduces the number of queries by optimizing the gradient estimation. In the experiments, we perform our attack against 4 different speech-to-text APIs under 3 real-world scenarios to demonstrate the real-time attack impact. The results show that PhantomSound is practical and robust in attacking 5 popular commercial voice controllable devices over the air, and is able to bypass 3 liveness detection mechanisms with >95% success rate. The benchmark result shows that PhantomSound can generate adversarial examples and launch the attack in a few minutes. We significantly enhance the query efficiency and reduce the cost of a successful untargeted and targeted adversarial attack by 93.1% and 65.5% compared with the state-of-the-art black-box attacks, using merely ~300 queries (~5 minutes) and ~1,500 queries (~25 minutes), respectively.