 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3imic: Learning a Versatile Whole-Body Controller for Multimodal Motion Mimicking
Jun 03, 2026Building a general-purpose whole-body controller is essential for enabling diverse motion capabilities in humanoid robots across a wide range of downstream tasks, including locomotion and loco-manipulation. Different tasks rely on distinct motion reference modalities: locomotion primarily depends on coordinated robot joint trajectories, whereas manipulation requires precise end-effector trajectory tracking. Existing methods often overlook the representational mismatch between dense robot joint angles and sparse end-effector poses. To address this, we propose Multi-Modal Mimic (M3imic), a versatile multi-modal whole-body control framework that unifies heterogeneous motion reference modalities, including robot joint angles, human pose trajectories, and end-effector poses, using modality-specific encoders to map them into a shared latent space. Leveraging large-scale reinforcement learning in the simulator, we train a single policy that achieves sim-to-real transfer across multiple motion reference modalities without modality-specific retraining. Extensive simulation and real-world experiments on the Unitree G1 robot are conducted to evaluate the proposed framework. In simulation, the policy achieves a peak success rate of 98.42\% on an unseen test dataset, demonstrating its exceptional generalization capability. The code is available at https://github.com/Renforce-Dynamics/MultiModalWBC
Toward Safety-First Human-Like Decision Making for Autonomous Vehicles in Time-Varying Traffic Flow
Jun 17, 2025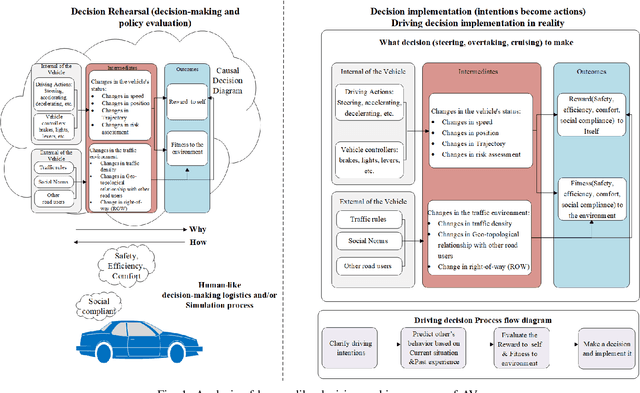

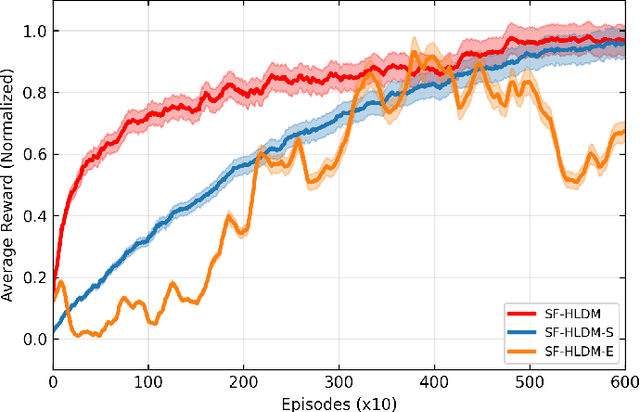
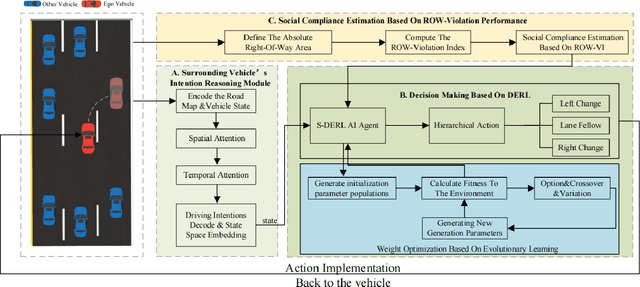
Despite the recent advancements in artificial intelligence technologies have shown great potential in improving transport efficiency and safety, autonomous vehicles(AVs) still face great challenge of driving in time-varying traffic flow, especially in dense and interactive situations. Meanwhile, human have free wills and usually do not make the same decisions even situate in the exactly same scenarios, leading to the data-driven methods suffer from poor migratability and high search cost problems, decreasing the efficiency and effectiveness of the behavior policy. In this research, we propose a safety-first human-like decision-making framework(SF-HLDM) for AVs to drive safely, comfortably, and social compatiblely in effiency. The framework integrates a hierarchical progressive framework, which combines a spatial-temporal attention (S-TA) mechanism for other road users' intention inference, a social compliance estimation module for behavior regulation, and a Deep Evolutionary Reinforcement Learning(DERL) model for expanding the search space efficiently and effectively to make avoidance of falling into the local optimal trap and reduce the risk of overfitting, thus make human-like decisions with interpretability and flexibility. The SF-HLDM framework enables autonomous driving AI agents dynamically adjusts decision parameters to maintain safety margins and adhering to contextually appropriate driving behaviors at the same time.
GSFF-SLAM: 3D Semantic Gaussian Splatting SLAM via Feature Field
Apr 28, 2025

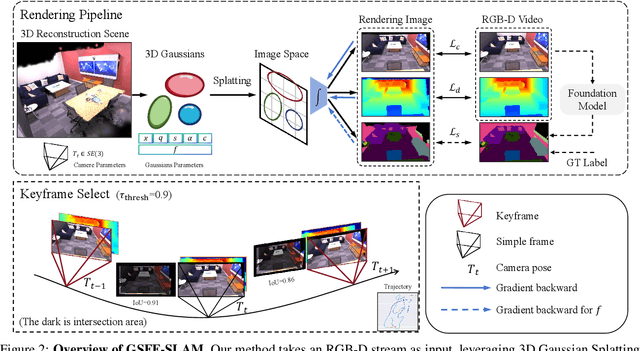
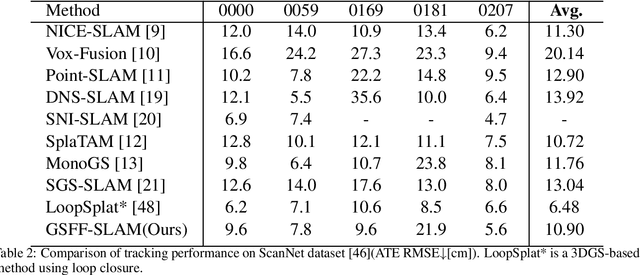
Semantic-aware 3D scene reconstruction is essential for autonomous robots to perform complex interactions. Semantic SLAM, an online approach, integrates pose tracking, geometric reconstruction, and semantic mapping into a unified framework, shows significant potential. However, existing systems, which rely on 2D ground truth priors for supervision, are often limited by the sparsity and noise of these signals in real-world environments. To address this challenge, we propose GSFF-SLAM, a novel dense semantic SLAM system based on 3D Gaussian Splatting that leverages feature fields to achieve joint rendering of appearance, geometry, and N-dimensional semantic features. By independently optimizing feature gradients, our method supports semantic reconstruction using various forms of 2D priors, particularly sparse and noisy signals. Experimental results demonstrate that our approach outperforms previous methods in both tracking accuracy and photorealistic rendering quality. When utilizing 2D ground truth priors, GSFF-SLAM achieves state-of-the-art semantic segmentation performance with 95.03\% mIoU, while achieving up to 2.9$\times$ speedup with only marginal performance degradation.
A Novel Frequency-Spatial Domain Aware Network for Fast Thermal Prediction in 2.5D ICs
Apr 19, 2025In the post-Moore era, 2.5D chiplet-based ICs present significant challenges in thermal management due to increased power density and thermal hotspots. Neural network-based thermal prediction models can perform real-time predictions for many unseen new designs. However, existing CNN-based and GCN-based methods cannot effectively capture the global thermal features, especially for high-frequency components, hindering prediction accuracy enhancement. In this paper, we propose a novel frequency-spatial dual domain aware prediction network (FSA-Heat) for fast and high-accuracy thermal prediction in 2.5D ICs. It integrates high-to-low frequency and spatial domain encoder (FSTE) module with frequency domain cross-scale interaction module (FCIFormer) to achieve high-to-low frequency and global-to-local thermal dissipation feature extraction. Additionally, a frequency-spatial hybrid loss (FSL) is designed to effectively attenuate high-frequency thermal gradient noise and spatial misalignments. The experimental results show that the performance enhancements offered by our proposed method are substantial, outperforming the newly-proposed 2.5D method, GCN+PNA, by considerable margins (over 99% RMSE reduction, 4.23X inference time speedup). Moreover, extensive experiments demonstrate that FSA-Heat also exhibits robust generalization capabilities.
Reducing Action Space for Deep Reinforcement Learning via Causal Effect Estimation
Jan 24, 2025Intelligent decision-making within large and redundant action spaces remains challenging in deep reinforcement learning. Considering similar but ineffective actions at each step can lead to repetitive and unproductive trials. Existing methods attempt to improve agent exploration by reducing or penalizing redundant actions, yet they fail to provide quantitative and reliable evidence to determine redundancy. In this paper, we propose a method to improve exploration efficiency by estimating the causal effects of actions. Unlike prior methods, our approach offers quantitative results regarding the causality of actions for one-step transitions. We first pre-train an inverse dynamics model to serve as prior knowledge of the environment. Subsequently, we classify actions across the entire action space at each time step and estimate the causal effect of each action to suppress redundant actions during exploration. We provide a theoretical analysis to demonstrate the effectiveness of our method and present empirical results from simulations in environments with redundant actions to evaluate its performance. Our implementation is available at https://github.com/agi-brain/cee.git.
LVLM-empowered Multi-modal Representation Learning for Visual Place Recognition
Jul 09, 2024
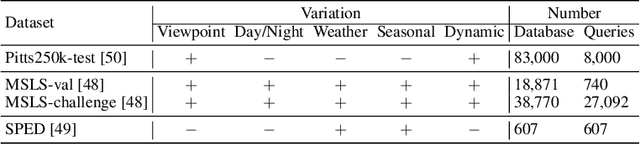
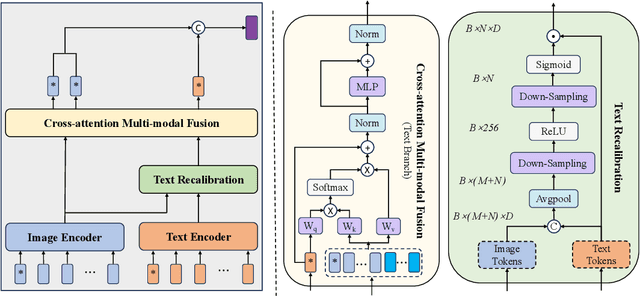

Visual place recognition (VPR) remains challenging due to significant viewpoint changes and appearance variations. Mainstream works tackle these challenges by developing various feature aggregation methods to transform deep features into robust and compact global representations. Unfortunately, satisfactory results cannot be achieved under challenging conditions. We start from a new perspective and attempt to build a discriminative global representations by fusing image data and text descriptions of the the visual scene. The motivation is twofold: (1) Current Large Vision-Language Models (LVLMs) demonstrate extraordinary emergent capability in visual instruction following, and thus provide an efficient and flexible manner in generating text descriptions of images; (2) The text descriptions, which provide high-level scene understanding, show strong robustness against environment variations. Although promising, leveraging LVLMs to build multi-modal VPR solutions remains challenging in efficient multi-modal fusion. Furthermore, LVLMs will inevitably produces some inaccurate descriptions, making it even harder. To tackle these challenges, we propose a novel multi-modal VPR solution. It first adapts pre-trained visual and language foundation models to VPR for extracting image and text features, which are then fed into the feature combiner to enhance each other. As the main component, the feature combiner first propose a token-wise attention block to adaptively recalibrate text tokens according to their relevance to the image data, and then develop an efficient cross-attention fusion module to propagate information across different modalities. The enhanced multi-modal features are compressed into the feature descriptor for performing retrieval. Experimental results show that our method outperforms state-of-the-art methods by a large margin with significantly smaller image descriptor dimension.
Window-to-Window BEV Representation Learning for Limited FoV Cross-View Geo-localization
Jul 09, 2024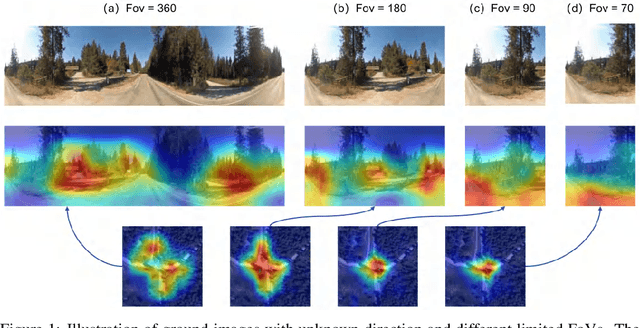

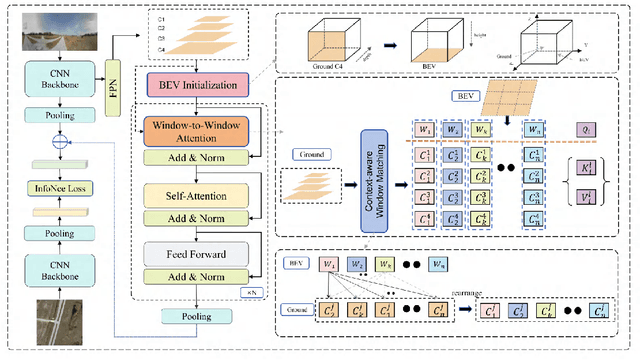
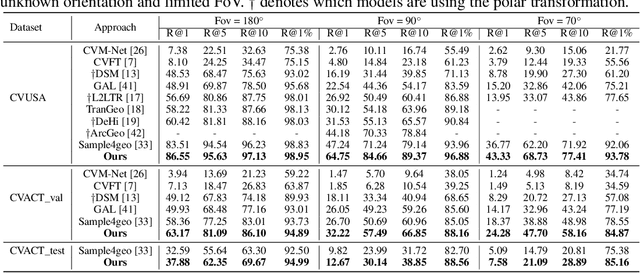
Cross-view geo-localization confronts significant challenges due to large perspective changes, especially when the ground-view query image has a limited field of view with unknown orientation. To bridge the cross-view domain gap, we for the first time explore to learn a BEV representation directly from the ground query image. However, the unknown orientation between ground and aerial images combined with the absence of camera parameters led to ambiguity between BEV queries and ground references. To tackle this challenge, we propose a novel Window-to-Window BEV representation learning method, termed W2W-BEV, which adaptively matches BEV queries to ground reference at window-scale. Specifically, predefined BEV embeddings and extracted ground features are segmented into a fixed number of windows, and then most similar ground window is chosen for each BEV feature based on the context-aware window matching strategy. Subsequently, the cross-attention is performed between the matched BEV and ground windows to learn the robust BEV representation. Additionally, we use ground features along with predicted depth information to initialize the BEV embeddings, helping learn more powerful BEV representations. Extensive experimental results on benchmark datasets demonstrate significant superiority of our W2W-BEV over previous state-of-the-art methods under challenging conditions of unknown orientation and limited FoV. Specifically, on the CVUSA dataset with limited Fov of 90 degree and unknown orientation, the W2W-BEV achieve an significant improvement from 47.24% to 64.73 %(+17.49%) in R@1 accuracy.
Learning Autonomous Race Driving with Action Mapping Reinforcement Learning
Jun 21, 2024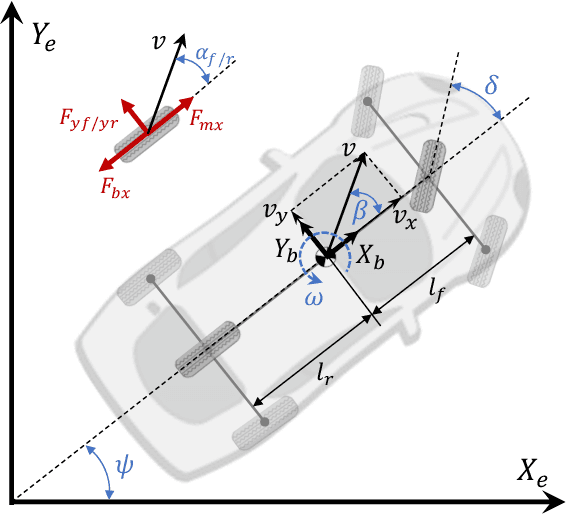



Autonomous race driving poses a complex control challenge as vehicles must be operated at the edge of their handling limits to reduce lap times while respecting physical and safety constraints. This paper presents a novel reinforcement learning (RL)-based approach, incorporating the action mapping (AM) mechanism to manage state-dependent input constraints arising from limited tire-road friction. A numerical approximation method is proposed to implement AM, addressing the complex dynamics associated with the friction constraints. The AM mechanism also allows the learned driving policy to be generalized to different friction conditions. Experimental results in our developed race simulator demonstrate that the proposed AM-RL approach achieves superior lap times and better success rates compared to the conventional RL-based approaches. The generalization capability of driving policy with AM is also validated in the experiments.
MCMS: Multi-Category Information and Multi-Scale Stripe Attention for Blind Motion Deblurring
May 02, 2024Deep learning-based motion deblurring techniques have advanced significantly in recent years. This class of techniques, however, does not carefully examine the inherent flaws in blurry images. For instance, low edge and structural information are traits of blurry images. The high-frequency component of blurry images is edge information, and the low-frequency component is structure information. A blind motion deblurring network (MCMS) based on multi-category information and multi-scale stripe attention mechanism is proposed. Given the respective characteristics of the high-frequency and low-frequency components, a three-stage encoder-decoder model is designed. Specifically, the first stage focuses on extracting the features of the high-frequency component, the second stage concentrates on extracting the features of the low-frequency component, and the third stage integrates the extracted low-frequency component features, the extracted high-frequency component features, and the original blurred image in order to recover the final clear image. As a result, the model effectively improves motion deblurring by fusing the edge information of the high-frequency component and the structural information of the low-frequency component. In addition, a grouped feature fusion technique is developed so as to achieve richer, more three-dimensional and comprehensive utilization of various types of features at a deep level. Next, a multi-scale stripe attention mechanism (MSSA) is designed, which effectively combines the anisotropy and multi-scale information of the image, a move that significantly enhances the capability of the deep model in feature representation. Large-scale comparative studies on various datasets show that the strategy in this paper works better than the recently published measures.
Empowering Large Language Models on Robotic Manipulation with Affordance Prompting
Apr 17, 2024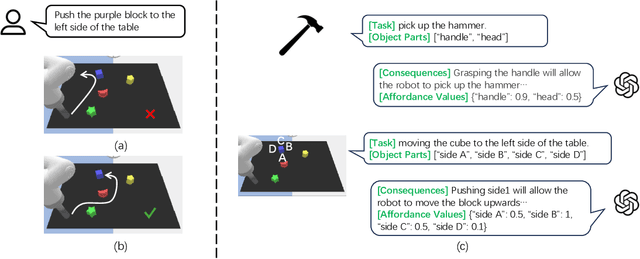
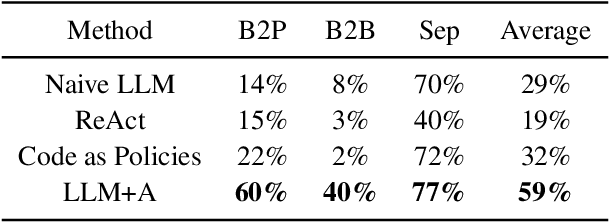
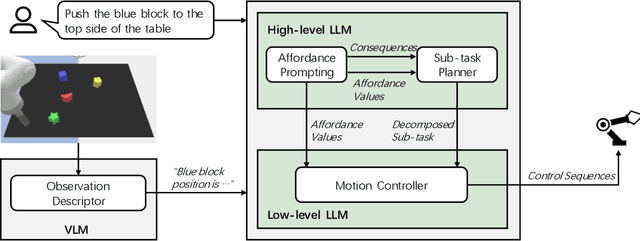
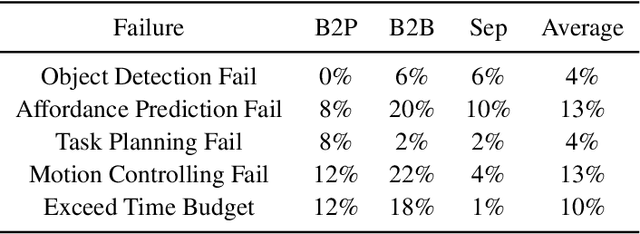
While large language models (LLMs) are successful in completing various language processing tasks, they easily fail to interact with the physical world by generating control sequences properly. We find that the main reason is that LLMs are not grounded in the physical world. Existing LLM-based approaches circumvent this problem by relying on additional pre-defined skills or pre-trained sub-policies, making it hard to adapt to new tasks. In contrast, we aim to address this problem and explore the possibility to prompt pre-trained LLMs to accomplish a series of robotic manipulation tasks in a training-free paradigm. Accordingly, we propose a framework called LLM+A(ffordance) where the LLM serves as both the sub-task planner (that generates high-level plans) and the motion controller (that generates low-level control sequences). To ground these plans and control sequences on the physical world, we develop the affordance prompting technique that stimulates the LLM to 1) predict the consequences of generated plans and 2) generate affordance values for relevant objects. Empirically, we evaluate the effectiveness of LLM+A in various language-conditioned robotic manipulation tasks, which show that our approach substantially improves performance by enhancing the feasibility of generated plans and control and can easily generalize to different environments.