 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVBench: Evaluating Cross-Video Synergies for Complex Multimodal Understanding and Reasoning
Aug 28, 2025While multimodal large language models (MLLMs) exhibit strong performance on single-video tasks (e.g., video question answering), their ability across multiple videos remains critically underexplored. However, this capability is essential for real-world applications, including multi-camera surveillance and cross-video procedural learning. To bridge this gap, we present CVBench, the first comprehensive benchmark designed to assess cross-video relational reasoning rigorously. CVBench comprises 1,000 question-answer pairs spanning three hierarchical tiers: cross-video object association (identifying shared entities), cross-video event association (linking temporal or causal event chains), and cross-video complex reasoning (integrating commonsense and domain knowledge). Built from five domain-diverse video clusters (e.g., sports, life records), the benchmark challenges models to synthesise information across dynamic visual contexts. Extensive evaluation of 10+ leading MLLMs (including GPT-4o, Gemini-2.0-flash, Qwen2.5-VL) under zero-shot or chain-of-thought prompting paradigms. Key findings reveal stark performance gaps: even top models, such as GPT-4o, achieve only 60% accuracy on causal reasoning tasks, compared to the 91% accuracy of human performance. Crucially, our analysis reveals fundamental bottlenecks inherent in current MLLM architectures, notably deficient inter-video context retention and poor disambiguation of overlapping entities. CVBench establishes a rigorous framework for diagnosing and advancing multi-video reasoning, offering architectural insights for next-generation MLLMs. The data and evaluation code are available at https://github.com/Hokhim2/CVBench.
Advancing Pre-trained Teacher: Towards Robust Feature Discrepancy for Anomaly Detection
May 03, 2024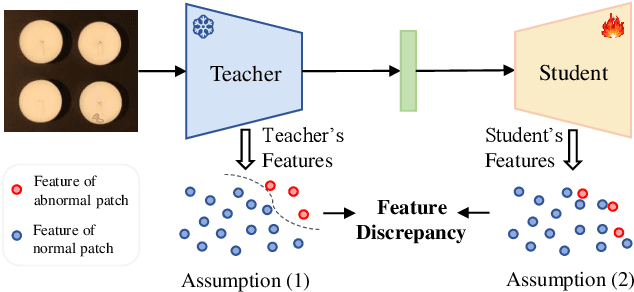
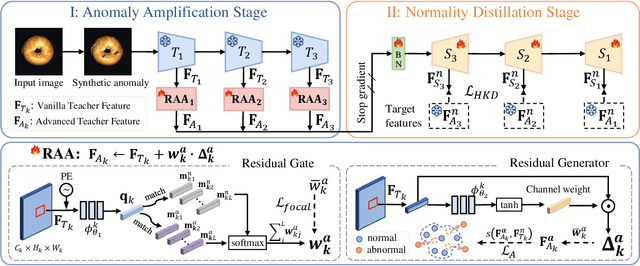
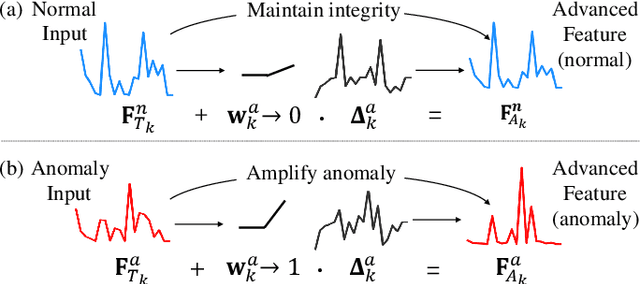
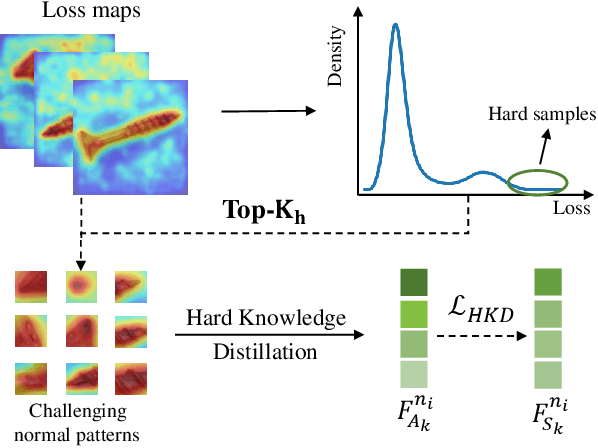
With the wide application of knowledge distillation between an ImageNet pre-trained teacher model and a learnable student model, industrial anomaly detection has witnessed a significant achievement in the past few years. The success of knowledge distillation mainly relies on how to keep the feature discrepancy between the teacher and student model, in which it assumes that: (1) the teacher model can jointly represent two different distributions for the normal and abnormal patterns, while (2) the student model can only reconstruct the normal distribution. However, it still remains a challenging issue to maintain these ideal assumptions in practice. In this paper, we propose a simple yet effective two-stage industrial anomaly detection framework, termed as AAND, which sequentially performs Anomaly Amplification and Normality Distillation to obtain robust feature discrepancy. In the first anomaly amplification stage, we propose a novel Residual Anomaly Amplification (RAA) module to advance the pre-trained teacher encoder. With the exposure of synthetic anomalies, it amplifies anomalies via residual generation while maintaining the integrity of pre-trained model. It mainly comprises a Matching-guided Residual Gate and an Attribute-scaling Residual Generator, which can determine the residuals' proportion and characteristic, respectively. In the second normality distillation stage, we further employ a reverse distillation paradigm to train a student decoder, in which a novel Hard Knowledge Distillation (HKD) loss is built to better facilitate the reconstruction of normal patterns. Comprehensive experiments on the MvTecAD, VisA, and MvTec3D-RGB datasets show that our method achieves state-of-the-art performance.
Recurrent Aligned Network for Generalized Pedestrian Trajectory Prediction
Mar 09, 2024Pedestrian trajectory prediction is a crucial component in computer vision and robotics, but remains challenging due to the domain shift problem. Previous studies have tried to tackle this problem by leveraging a portion of the trajectory data from the target domain to adapt the model. However, such domain adaptation methods are impractical in real-world scenarios, as it is infeasible to collect trajectory data from all potential target domains. In this paper, we study a task named generalized pedestrian trajectory prediction, with the aim of generalizing the model to unseen domains without accessing their trajectories. To tackle this task, we introduce a Recurrent Aligned Network~(RAN) to minimize the domain gap through domain alignment. Specifically, we devise a recurrent alignment module to effectively align the trajectory feature spaces at both time-state and time-sequence levels by the recurrent alignment strategy.Furthermore, we introduce a pre-aligned representation module to combine social interactions with the recurrent alignment strategy, which aims to consider social interactions during the alignment process instead of just target trajectories. We extensively evaluate our method and compare it with state-of-the-art methods on three widely used benchmarks. The experimental results demonstrate the superior generalization capability of our method. Our work not only fills the gap in the generalization setting for practical pedestrian trajectory prediction but also sets strong baselines in this field.
Sparse Pedestrian Character Learning for Trajectory Prediction
Nov 27, 2023
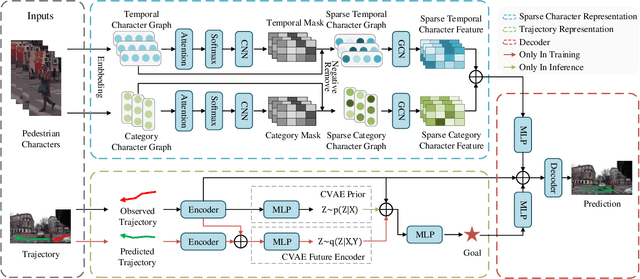
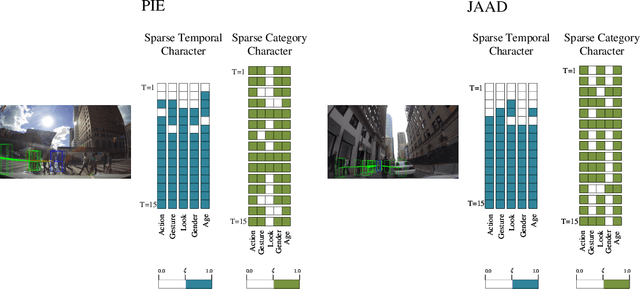

Pedestrian trajectory prediction in a first-person view has recently attracted much attention due to its importance in autonomous driving. Recent work utilizes pedestrian character information, \textit{i.e.}, action and appearance, to improve the learned trajectory embedding and achieves state-of-the-art performance. However, it neglects the invalid and negative pedestrian character information, which is harmful to trajectory representation and thus leads to performance degradation. To address this issue, we present a two-stream sparse-character-based network~(TSNet) for pedestrian trajectory prediction. Specifically, TSNet learns the negative-removed characters in the sparse character representation stream to improve the trajectory embedding obtained in the trajectory representation stream. Moreover, to model the negative-removed characters, we propose a novel sparse character graph, including the sparse category and sparse temporal character graphs, to learn the different effects of various characters in category and temporal dimensions, respectively. Extensive experiments on two first-person view datasets, PIE and JAAD, show that our method outperforms existing state-of-the-art methods. In addition, ablation studies demonstrate different effects of various characters and prove that TSNet outperforms approaches without eliminating negative characters.