 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025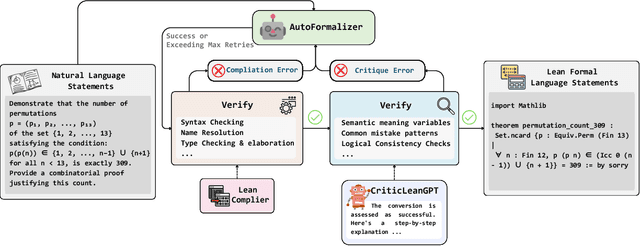

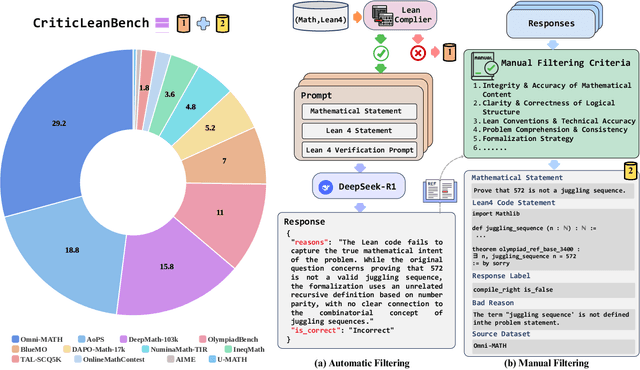
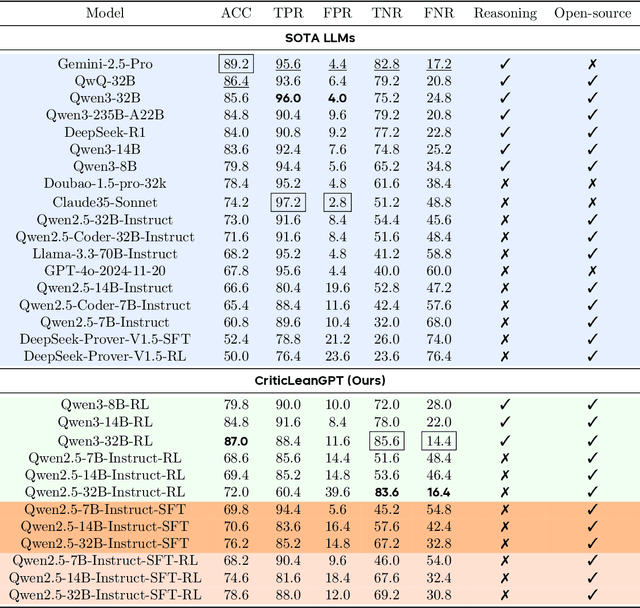
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.
Time-Unified Diffusion Policy with Action Discrimination for Robotic Manipulation
Jun 11, 2025In many complex scenarios, robotic manipulation relies on generative models to estimate the distribution of multiple successful actions. As the diffusion model has better training robustness than other generative models, it performs well in imitation learning through successful robot demonstrations. However, the diffusion-based policy methods typically require significant time to iteratively denoise robot actions, which hinders real-time responses in robotic manipulation. Moreover, existing diffusion policies model a time-varying action denoising process, whose temporal complexity increases the difficulty of model training and leads to suboptimal action accuracy. To generate robot actions efficiently and accurately, we present the Time-Unified Diffusion Policy (TUDP), which utilizes action recognition capabilities to build a time-unified denoising process. On the one hand, we build a time-unified velocity field in action space with additional action discrimination information. By unifying all timesteps of action denoising, our velocity field reduces the difficulty of policy learning and speeds up action generation. On the other hand, we propose an action-wise training method, which introduces an action discrimination branch to supply additional action discrimination information. Through action-wise training, the TUDP implicitly learns the ability to discern successful actions to better denoising accuracy. Our method achieves state-of-the-art performance on RLBench with the highest success rate of 82.6% on a multi-view setup and 83.8% on a single-view setup. In particular, when using fewer denoising iterations, TUDP achieves a more significant improvement in success rate. Additionally, TUDP can produce accurate actions for a wide range of real-world tasks.
FormalMATH: Benchmarking Formal Mathematical Reasoning of Large Language Models
May 05, 2025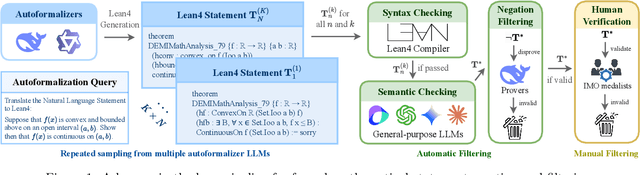

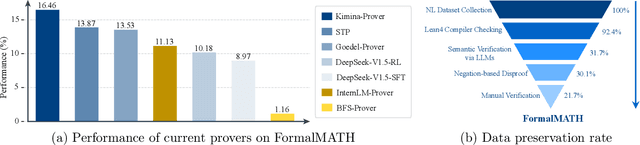

Formal mathematical reasoning remains a critical challenge for artificial intelligence, hindered by limitations of existing benchmarks in scope and scale. To address this, we present FormalMATH, a large-scale Lean4 benchmark comprising 5,560 formally verified problems spanning from high-school Olympiad challenges to undergraduate-level theorems across diverse domains (e.g., algebra, applied mathematics, calculus, number theory, and discrete mathematics). To mitigate the inefficiency of manual formalization, we introduce a novel human-in-the-loop autoformalization pipeline that integrates: (1) specialized large language models (LLMs) for statement autoformalization, (2) multi-LLM semantic verification, and (3) negation-based disproof filtering strategies using off-the-shelf LLM-based provers. This approach reduces expert annotation costs by retaining 72.09% of statements before manual verification while ensuring fidelity to the original natural-language problems. Our evaluation of state-of-the-art LLM-based theorem provers reveals significant limitations: even the strongest models achieve only 16.46% success rate under practical sampling budgets, exhibiting pronounced domain bias (e.g., excelling in algebra but failing in calculus) and over-reliance on simplified automation tactics. Notably, we identify a counterintuitive inverse relationship between natural-language solution guidance and proof success in chain-of-thought reasoning scenarios, suggesting that human-written informal reasoning introduces noise rather than clarity in the formal reasoning settings. We believe that FormalMATH provides a robust benchmark for benchmarking formal mathematical reasoning.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
DeepMF: Deep Motion Factorization for Closed-Loop Safety-Critical Driving Scenario Simulation
Dec 23, 2024



Safety-critical traffic scenarios are of great practical relevance to evaluating the robustness of autonomous driving (AD) systems. Given that these long-tail events are extremely rare in real-world traffic data, there is a growing body of work dedicated to the automatic traffic scenario generation. However, nearly all existing algorithms for generating safety-critical scenarios rely on snippets of previously recorded traffic events, transforming normal traffic flow into accident-prone situations directly. In other words, safety-critical traffic scenario generation is hindsight and not applicable to newly encountered and open-ended traffic events.In this paper, we propose the Deep Motion Factorization (DeepMF) framework, which extends static safety-critical driving scenario generation to closed-loop and interactive adversarial traffic simulation. DeepMF casts safety-critical traffic simulation as a Bayesian factorization that includes the assignment of hazardous traffic participants, the motion prediction of selected opponents, the reaction estimation of autonomous vehicle (AV) and the probability estimation of the accident occur. All the aforementioned terms are calculated using decoupled deep neural networks, with inputs limited to the current observation and historical states. Consequently, DeepMF can effectively and efficiently simulate safety-critical traffic scenarios at any triggered time and for any duration by maximizing the compounded posterior probability of traffic risk. Extensive experiments demonstrate that DeepMF excels in terms of risk management, flexibility, and diversity, showcasing outstanding performance in simulating a wide range of realistic, high-risk traffic scenarios.
Advancing Pre-trained Teacher: Towards Robust Feature Discrepancy for Anomaly Detection
May 03, 2024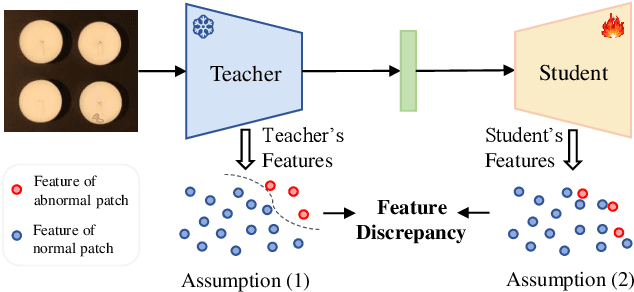
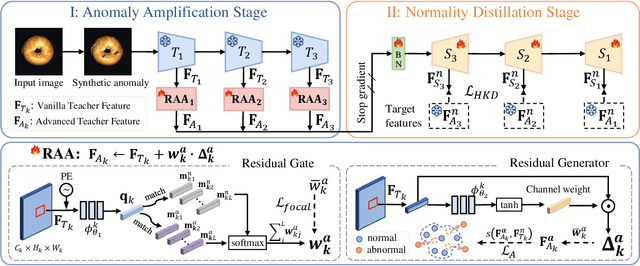
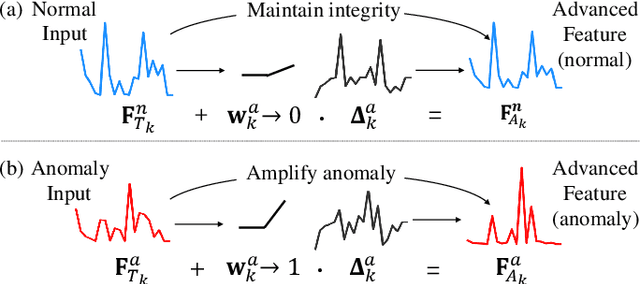
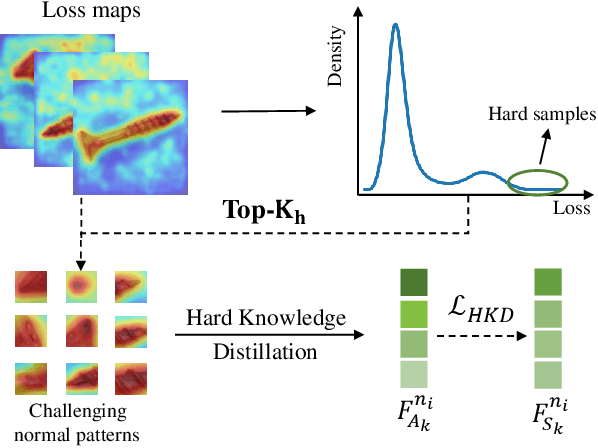
With the wide application of knowledge distillation between an ImageNet pre-trained teacher model and a learnable student model, industrial anomaly detection has witnessed a significant achievement in the past few years. The success of knowledge distillation mainly relies on how to keep the feature discrepancy between the teacher and student model, in which it assumes that: (1) the teacher model can jointly represent two different distributions for the normal and abnormal patterns, while (2) the student model can only reconstruct the normal distribution. However, it still remains a challenging issue to maintain these ideal assumptions in practice. In this paper, we propose a simple yet effective two-stage industrial anomaly detection framework, termed as AAND, which sequentially performs Anomaly Amplification and Normality Distillation to obtain robust feature discrepancy. In the first anomaly amplification stage, we propose a novel Residual Anomaly Amplification (RAA) module to advance the pre-trained teacher encoder. With the exposure of synthetic anomalies, it amplifies anomalies via residual generation while maintaining the integrity of pre-trained model. It mainly comprises a Matching-guided Residual Gate and an Attribute-scaling Residual Generator, which can determine the residuals' proportion and characteristic, respectively. In the second normality distillation stage, we further employ a reverse distillation paradigm to train a student decoder, in which a novel Hard Knowledge Distillation (HKD) loss is built to better facilitate the reconstruction of normal patterns. Comprehensive experiments on the MvTecAD, VisA, and MvTec3D-RGB datasets show that our method achieves state-of-the-art performance.
Single-Shot and Multi-Shot Feature Learning for Multi-Object Tracking
Nov 17, 2023Multi-Object Tracking (MOT) remains a vital component of intelligent video analysis, which aims to locate targets and maintain a consistent identity for each target throughout a video sequence. Existing works usually learn a discriminative feature representation, such as motion and appearance, to associate the detections across frames, which are easily affected by mutual occlusion and background clutter in practice. In this paper, we propose a simple yet effective two-stage feature learning paradigm to jointly learn single-shot and multi-shot features for different targets, so as to achieve robust data association in the tracking process. For the detections without being associated, we design a novel single-shot feature learning module to extract discriminative features of each detection, which can efficiently associate targets between adjacent frames. For the tracklets being lost several frames, we design a novel multi-shot feature learning module to extract discriminative features of each tracklet, which can accurately refind these lost targets after a long period. Once equipped with a simple data association logic, the resulting VisualTracker can perform robust MOT based on the single-shot and multi-shot feature representations. Extensive experimental results demonstrate that our method has achieved significant improvements on MOT17 and MOT20 datasets while reaching state-of-the-art performance on DanceTrack dataset.
Exploring the Benefits of Visual Prompting in Differential Privacy
Mar 22, 2023



Visual Prompting (VP) is an emerging and powerful technique that allows sample-efficient adaptation to downstream tasks by engineering a well-trained frozen source model. In this work, we explore the benefits of VP in constructing compelling neural network classifiers with differential privacy (DP). We explore and integrate VP into canonical DP training methods and demonstrate its simplicity and efficiency. In particular, we discover that VP in tandem with PATE, a state-of-the-art DP training method that leverages the knowledge transfer from an ensemble of teachers, achieves the state-of-the-art privacy-utility trade-off with minimum expenditure of privacy budget. Moreover, we conduct additional experiments on cross-domain image classification with a sufficient domain gap to further unveil the advantage of VP in DP. Lastly, we also conduct extensive ablation studies to validate the effectiveness and contribution of VP under DP consideration.
Efficient Urban-scale Point Clouds Segmentation with BEV Projection
Sep 19, 2021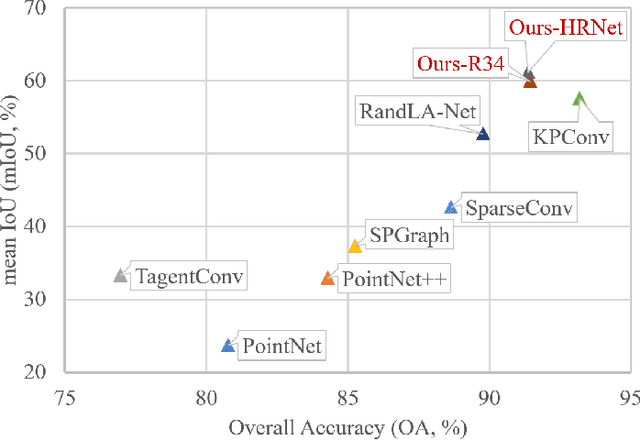



Point clouds analysis has grasped researchers' eyes in recent years, while 3D semantic segmentation remains a problem. Most deep point clouds models directly conduct learning on 3D point clouds, which will suffer from the severe sparsity and extreme data processing load in urban-scale data. To tackle the challenge, we propose to transfer the 3D point clouds to dense bird's-eye-view projection. In this case, the segmentation task is simplified because of class unbalance reduction and the feasibility of leveraging various 2D segmentation methods. We further design an attention-based fusion network that can conduct multi-modal learning on the projected images. Finally, the 2D out are remapped to generate 3D semantic segmentation results. To demonstrate the benefits of our method, we conduct various experiments on the SensatUrban dataset, in which our model presents competitive evaluation results (61.17% mIoU and 91.37% OverallAccuracy). We hope our work can inspire further exploration in point cloud analysis.