 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Thoughts Are Not Secret: Reasoning Trace Exposure in LLMs
May 30, 2026Reasoning traces have become a valuable form of learning signals for improving and transferring the capabilities of large language models. In particular, detailed traces can help distill reasoning behavior from stronger teacher models into weaker student models. The value of capability transfer has motivated many deployed systems with reasoning models to hide raw internal traces and expose at most summaries and answers to users. As a result, we ask whether such interface-level trace hiding prevents users from obtaining useful reasoning supervision through prompting. We study this question with Reasoning Exposure Prompting (REP), a lightweight in-context elicitation method that uses shadow-model-generated demonstrations wrapped in auxiliary code-like formats to raise user-visible reasoning traces from a victim model. Across the common reasoning dataset, different victim models, and different student model distillation, REP substantially increases similarity between exposed and REP-conditioned internal traces while preserving useful reasoning signals.
Filtering Memorization from Parameter-Space in Diffusion Models
May 11, 2026Low-Rank Adaptation (LoRA) has become a widely used mechanism for customizing diffusion models, enabling users to inject new visual concepts or styles through lightweight parameter updates. However, LoRAs can memorize training images, causing generated outputs to reproduce copyrighted or sensitive content. This risk is particularly concerning in LoRA-sharing ecosystems, where users distribute trained LoRAs without releasing the underlying training data. Existing approaches for mitigating memorization rely on access to the training pipeline, training data, or control over the inference process, making them difficult to apply when only the released LoRA weights are available. We propose \textbf{Base-Anchored Filtering (BAF)}, a training-free and data-free framework for post-hoc memorization mitigation in diffusion LoRAs. BAF decomposes LoRA updates into spectral channels and measures their alignment with the principal subspace of the pretrained backbone. Channels strongly aligned with this subspace are retained as generalizable adaptations, while weakly aligned channels are suppressed as potential carriers of memorized content. Experiments on multiple datasets and diffusion backbones demonstrate that BAF consistently reduces memorization while preserving or even improving generation quality. Our code is available in the supplementary material.
VP-NTK: Exploring the Benefits of Visual Prompting in Differentially Private Data Synthesis
Mar 20, 2025Differentially private (DP) synthetic data has become the de facto standard for releasing sensitive data. However, many DP generative models suffer from the low utility of synthetic data, especially for high-resolution images. On the other hand, one of the emerging techniques in parameter efficient fine-tuning (PEFT) is visual prompting (VP), which allows well-trained existing models to be reused for the purpose of adapting to subsequent downstream tasks. In this work, we explore such a phenomenon in constructing captivating generative models with DP constraints. We show that VP in conjunction with DP-NTK, a DP generator that exploits the power of the neural tangent kernel (NTK) in training DP generative models, achieves a significant performance boost, particularly for high-resolution image datasets, with accuracy improving from 0.644$\pm$0.044 to 0.769. Lastly, we perform ablation studies on the effect of different parameters that influence the overall performance of VP-NTK. Our work demonstrates a promising step forward in improving the utility of DP synthetic data, particularly for high-resolution images.
BADTV: Unveiling Backdoor Threats in Third-Party Task Vectors
Jan 04, 2025Task arithmetic in large-scale pre-trained models enables flexible adaptation to diverse downstream tasks without extensive re-training. By leveraging task vectors (TVs), users can perform modular updates to pre-trained models through simple arithmetic operations like addition and subtraction. However, this flexibility introduces new security vulnerabilities. In this paper, we identify and evaluate the susceptibility of TVs to backdoor attacks, demonstrating how malicious actors can exploit TVs to compromise model integrity. By developing composite backdoors and eliminating redudant clean tasks, we introduce BadTV, a novel backdoor attack specifically designed to remain effective under task learning, forgetting, and analogies operations. Our extensive experiments reveal that BadTV achieves near-perfect attack success rates across various scenarios, significantly impacting the security of models using task arithmetic. We also explore existing defenses, showing that current methods fail to detect or mitigate BadTV. Our findings highlight the need for robust defense mechanisms to secure TVs in real-world applications, especially as TV services become more popular in machine-learning ecosystems.
Safe LoRA: the Silver Lining of Reducing Safety Risks when Fine-tuning Large Language Models
May 27, 2024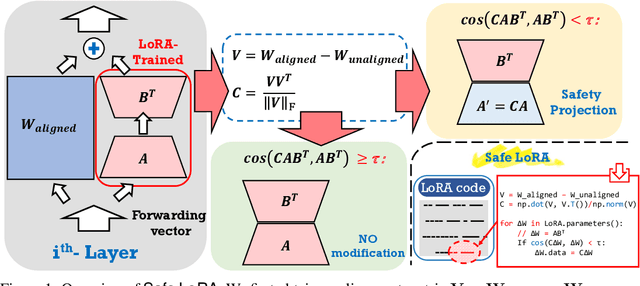

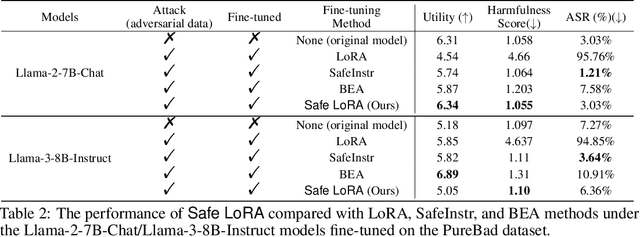
While large language models (LLMs) such as Llama-2 or GPT-4 have shown impressive zero-shot performance, fine-tuning is still necessary to enhance their performance for customized datasets, domain-specific tasks, or other private needs. However, fine-tuning all parameters of LLMs requires significant hardware resources, which can be impractical for typical users. Therefore, parameter-efficient fine-tuning such as LoRA have emerged, allowing users to fine-tune LLMs without the need for considerable computing resources, with little performance degradation compared to fine-tuning all parameters. Unfortunately, recent studies indicate that fine-tuning can increase the risk to the safety of LLMs, even when data does not contain malicious content. To address this challenge, we propose Safe LoRA, a simple one-liner patch to the original LoRA implementation by introducing the projection of LoRA weights from selected layers to the safety-aligned subspace, effectively reducing the safety risks in LLM fine-tuning while maintaining utility. It is worth noting that Safe LoRA is a training-free and data-free approach, as it only requires the knowledge of the weights from the base and aligned LLMs. Our extensive experiments demonstrate that when fine-tuning on purely malicious data, Safe LoRA retains similar safety performance as the original aligned model. Moreover, when the fine-tuning dataset contains a mixture of both benign and malicious data, Safe LoRA mitigates the negative effect made by malicious data while preserving performance on downstream tasks.
Ring-A-Bell! How Reliable are Concept Removal Methods for Diffusion Models?
Oct 16, 2023


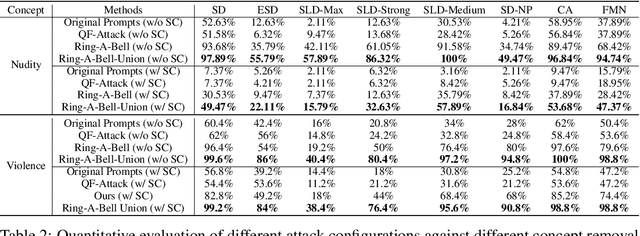
Diffusion models for text-to-image (T2I) synthesis, such as Stable Diffusion (SD), have recently demonstrated exceptional capabilities for generating high-quality content. However, this progress has raised several concerns of potential misuse, particularly in creating copyrighted, prohibited, and restricted content, or NSFW (not safe for work) images. While efforts have been made to mitigate such problems, either by implementing a safety filter at the evaluation stage or by fine-tuning models to eliminate undesirable concepts or styles, the effectiveness of these safety measures in dealing with a wide range of prompts remains largely unexplored. In this work, we aim to investigate these safety mechanisms by proposing one novel concept retrieval algorithm for evaluation. We introduce Ring-A-Bell, a model-agnostic red-teaming tool for T2I diffusion models, where the whole evaluation can be prepared in advance without prior knowledge of the target model. Specifically, Ring-A-Bell first performs concept extraction to obtain holistic representations for sensitive and inappropriate concepts. Subsequently, by leveraging the extracted concept, Ring-A-Bell automatically identifies problematic prompts for diffusion models with the corresponding generation of inappropriate content, allowing the user to assess the reliability of deployed safety mechanisms. Finally, we empirically validate our method by testing online services such as Midjourney and various methods of concept removal. Our results show that Ring-A-Bell, by manipulating safe prompting benchmarks, can transform prompts that were originally regarded as safe to evade existing safety mechanisms, thus revealing the defects of the so-called safety mechanisms which could practically lead to the generation of harmful contents.
Exploring the Benefits of Visual Prompting in Differential Privacy
Mar 22, 2023



Visual Prompting (VP) is an emerging and powerful technique that allows sample-efficient adaptation to downstream tasks by engineering a well-trained frozen source model. In this work, we explore the benefits of VP in constructing compelling neural network classifiers with differential privacy (DP). We explore and integrate VP into canonical DP training methods and demonstrate its simplicity and efficiency. In particular, we discover that VP in tandem with PATE, a state-of-the-art DP training method that leverages the knowledge transfer from an ensemble of teachers, achieves the state-of-the-art privacy-utility trade-off with minimum expenditure of privacy budget. Moreover, we conduct additional experiments on cross-domain image classification with a sufficient domain gap to further unveil the advantage of VP in DP. Lastly, we also conduct extensive ablation studies to validate the effectiveness and contribution of VP under DP consideration.
Certified Robustness of Quantum Classifiers against Adversarial Examples through Quantum Noise
Nov 02, 2022Recently, quantum classifiers have been known to be vulnerable to adversarial attacks, where quantum classifiers are fooled by imperceptible noises to have misclassification. In this paper, we propose one first theoretical study that utilizing the added quantum random rotation noise can improve the robustness of quantum classifiers against adversarial attacks. We connect the definition of differential privacy and demonstrate the quantum classifier trained with the natural presence of additive noise is differentially private. Lastly, we derive a certified robustness bound to enable quantum classifiers to defend against adversarial examples supported by experimental results.
Formalizing Generalization and Robustness of Neural Networks to Weight Perturbations
Mar 03, 2021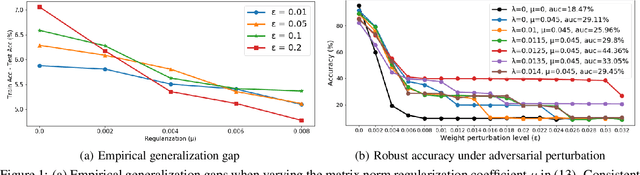

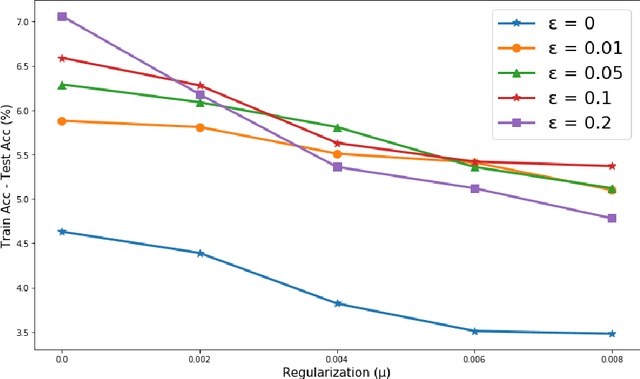
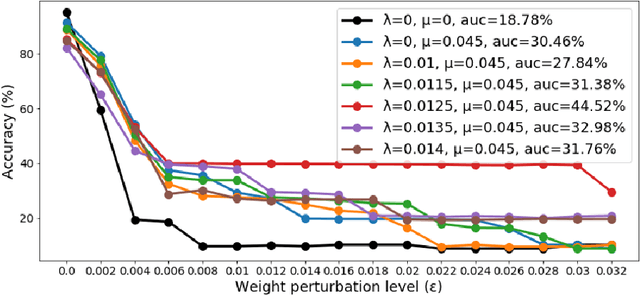
Studying the sensitivity of weight perturbation in neural networks and its impacts on model performance, including generalization and robustness, is an active research topic due to its implications on a wide range of machine learning tasks such as model compression, generalization gap assessment, and adversarial attacks. In this paper, we provide the first formal analysis for feed-forward neural networks with non-negative monotone activation functions against norm-bounded weight perturbations, in terms of the robustness in pairwise class margin functions and the Rademacher complexity for generalization. We further design a new theory-driven loss function for training generalizable and robust neural networks against weight perturbations. Empirical experiments are conducted to validate our theoretical analysis. Our results offer fundamental insights for characterizing the generalization and robustness of neural networks against weight perturbations.
Non-Singular Adversarial Robustness of Neural Networks
Feb 23, 2021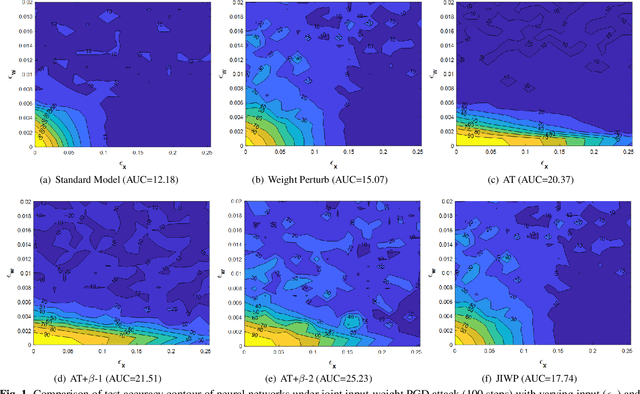
Adversarial robustness has become an emerging challenge for neural network owing to its over-sensitivity to small input perturbations. While being critical, we argue that solving this singular issue alone fails to provide a comprehensive robustness assessment. Even worse, the conclusions drawn from singular robustness may give a false sense of overall model robustness. Specifically, our findings show that adversarially trained models that are robust to input perturbations are still (or even more) vulnerable to weight perturbations when compared to standard models. In this paper, we formalize the notion of non-singular adversarial robustness for neural networks through the lens of joint perturbations to data inputs as well as model weights. To our best knowledge, this study is the first work considering simultaneous input-weight adversarial perturbations. Based on a multi-layer feed-forward neural network model with ReLU activation functions and standard classification loss, we establish error analysis for quantifying the loss sensitivity subject to $\ell_\infty$-norm bounded perturbations on data inputs and model weights. Based on the error analysis, we propose novel regularization functions for robust training and demonstrate improved non-singular robustness against joint input-weight adversarial perturbations.