 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe LoRA: the Silver Lining of Reducing Safety Risks when Fine-tuning Large Language Models
Paper and Code
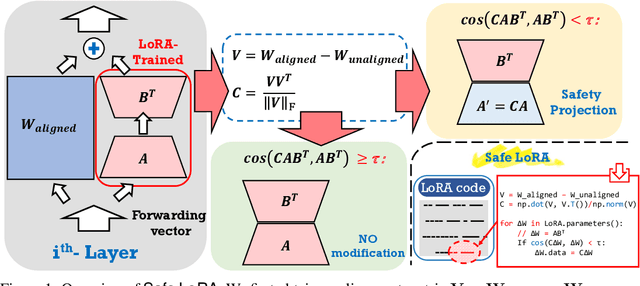

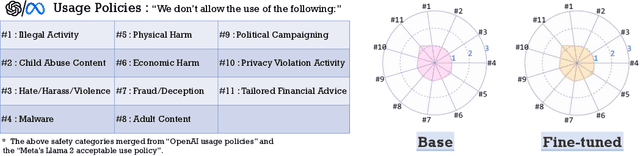
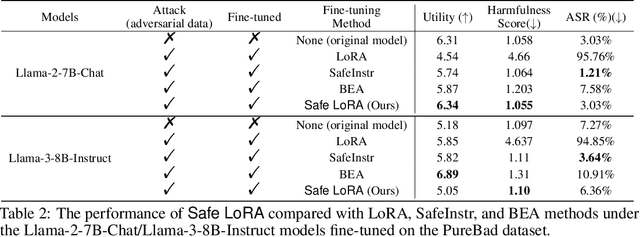
While large language models (LLMs) such as Llama-2 or GPT-4 have shown impressive zero-shot performance, fine-tuning is still necessary to enhance their performance for customized datasets, domain-specific tasks, or other private needs. However, fine-tuning all parameters of LLMs requires significant hardware resources, which can be impractical for typical users. Therefore, parameter-efficient fine-tuning such as LoRA have emerged, allowing users to fine-tune LLMs without the need for considerable computing resources, with little performance degradation compared to fine-tuning all parameters. Unfortunately, recent studies indicate that fine-tuning can increase the risk to the safety of LLMs, even when data does not contain malicious content. To address this challenge, we propose Safe LoRA, a simple one-liner patch to the original LoRA implementation by introducing the projection of LoRA weights from selected layers to the safety-aligned subspace, effectively reducing the safety risks in LLM fine-tuning while maintaining utility. It is worth noting that Safe LoRA is a training-free and data-free approach, as it only requires the knowledge of the weights from the base and aligned LLMs. Our extensive experiments demonstrate that when fine-tuning on purely malicious data, Safe LoRA retains similar safety performance as the original aligned model. Moreover, when the fine-tuning dataset contains a mixture of both benign and malicious data, Safe LoRA mitigates the negative effect made by malicious data while preserving performance on downstream tasks.