 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Urban-scale Point Clouds Segmentation with BEV Projection
Paper and Code
Sep 19, 2021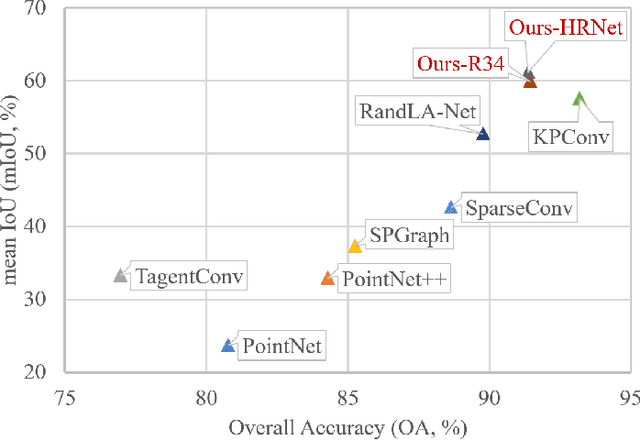



Point clouds analysis has grasped researchers' eyes in recent years, while 3D semantic segmentation remains a problem. Most deep point clouds models directly conduct learning on 3D point clouds, which will suffer from the severe sparsity and extreme data processing load in urban-scale data. To tackle the challenge, we propose to transfer the 3D point clouds to dense bird's-eye-view projection. In this case, the segmentation task is simplified because of class unbalance reduction and the feasibility of leveraging various 2D segmentation methods. We further design an attention-based fusion network that can conduct multi-modal learning on the projected images. Finally, the 2D out are remapped to generate 3D semantic segmentation results. To demonstrate the benefits of our method, we conduct various experiments on the SensatUrban dataset, in which our model presents competitive evaluation results (61.17% mIoU and 91.37% OverallAccuracy). We hope our work can inspire further exploration in point cloud analysis.