 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld In Your Hands: A Large-Scale and Open-source Ecosystem for Learning Human-centric Manipulation in the Wild
Dec 30, 2025Large-scale pre-training is fundamental for generalization in language and vision models, but data for dexterous hand manipulation remains limited in scale and diversity, hindering policy generalization. Limited scenario diversity, misaligned modalities, and insufficient benchmarking constrain current human manipulation datasets. To address these gaps, we introduce World In Your Hands (WiYH), a large-scale open-source ecosystem for human-centric manipulation learning. WiYH includes (1) the Oracle Suite, a wearable data collection kit with an auto-labeling pipeline for accurate motion capture; (2) the WiYH Dataset, featuring over 1,000 hours of multi-modal manipulation data across hundreds of skills in diverse real-world scenarios; and (3) extensive annotations and benchmarks supporting tasks from perception to action. Furthermore, experiments based on the WiYH ecosystem show that integrating WiYH's human-centric data significantly enhances the generalization and robustness of dexterous hand policies in tabletop manipulation tasks. We believe that World In Your Hands will bring new insights into human-centric data collection and policy learning to the community.
Informative Data Selection with Uncertainty for Multi-modal Object Detection
Apr 23, 2023



Noise has always been nonnegligible trouble in object detection by creating confusion in model reasoning, thereby reducing the informativeness of the data. It can lead to inaccurate recognition due to the shift in the observed pattern, that requires a robust generalization of the models. To implement a general vision model, we need to develop deep learning models that can adaptively select valid information from multi-modal data. This is mainly based on two reasons. Multi-modal learning can break through the inherent defects of single-modal data, and adaptive information selection can reduce chaos in multi-modal data. To tackle this problem, we propose a universal uncertainty-aware multi-modal fusion model. It adopts a multi-pipeline loosely coupled architecture to combine the features and results from point clouds and images. To quantify the correlation in multi-modal information, we model the uncertainty, as the inverse of data information, in different modalities and embed it in the bounding box generation. In this way, our model reduces the randomness in fusion and generates reliable output. Moreover, we conducted a completed investigation on the KITTI 2D object detection dataset and its derived dirty data. Our fusion model is proven to resist severe noise interference like Gaussian, motion blur, and frost, with only slight degradation. The experiment results demonstrate the benefits of our adaptive fusion. Our analysis on the robustness of multi-modal fusion will provide further insights for future research.
Efficient Urban-scale Point Clouds Segmentation with BEV Projection
Sep 19, 2021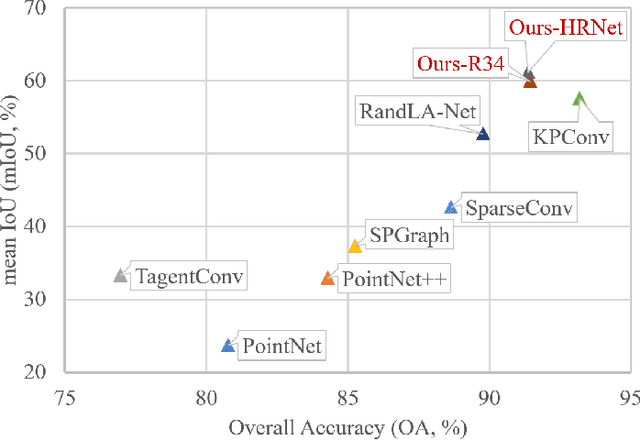



Point clouds analysis has grasped researchers' eyes in recent years, while 3D semantic segmentation remains a problem. Most deep point clouds models directly conduct learning on 3D point clouds, which will suffer from the severe sparsity and extreme data processing load in urban-scale data. To tackle the challenge, we propose to transfer the 3D point clouds to dense bird's-eye-view projection. In this case, the segmentation task is simplified because of class unbalance reduction and the feasibility of leveraging various 2D segmentation methods. We further design an attention-based fusion network that can conduct multi-modal learning on the projected images. Finally, the 2D out are remapped to generate 3D semantic segmentation results. To demonstrate the benefits of our method, we conduct various experiments on the SensatUrban dataset, in which our model presents competitive evaluation results (61.17% mIoU and 91.37% OverallAccuracy). We hope our work can inspire further exploration in point cloud analysis.
A novel multimodal fusion network based on a joint coding model for lane line segmentation
Mar 20, 2021
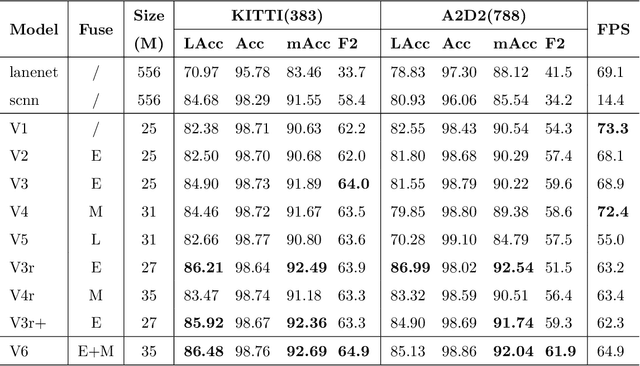
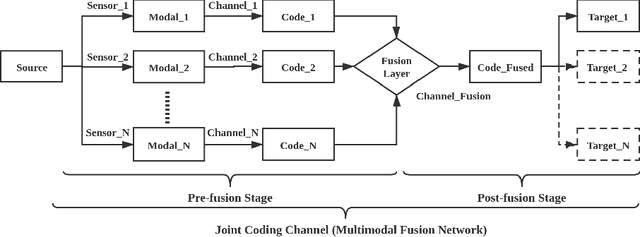
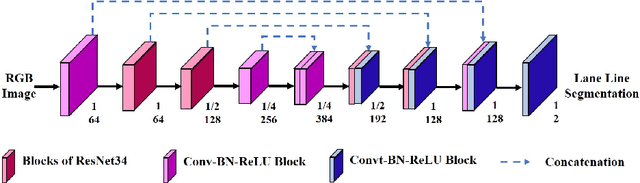
There has recently been growing interest in utilizing multimodal sensors to achieve robust lane line segmentation. In this paper, we introduce a novel multimodal fusion architecture from an information theory perspective, and demonstrate its practical utility using Light Detection and Ranging (LiDAR) camera fusion networks. In particular, we develop, for the first time, a multimodal fusion network as a joint coding model, where each single node, layer, and pipeline is represented as a channel. The forward propagation is thus equal to the information transmission in the channels. Then, we can qualitatively and quantitatively analyze the effect of different fusion approaches. We argue the optimal fusion architecture is related to the essential capacity and its allocation based on the source and channel. To test this multimodal fusion hypothesis, we progressively determine a series of multimodal models based on the proposed fusion methods and evaluate them on the KITTI and the A2D2 datasets. Our optimal fusion network achieves 85%+ lane line accuracy and 98.7%+ overall. The performance gap among the models will inform continuing future research into development of optimal fusion algorithms for the deep multimodal learning community.
Topic-aware chatbot using Recurrent Neural Networks and Nonnegative Matrix Factorization
Dec 04, 2019


We propose a novel model for a topic-aware chatbot by combining the traditional Recurrent Neural Network (RNN) encoder-decoder model with a topic attention layer based on Nonnegative Matrix Factorization (NMF). After learning topic vectors from an auxiliary text corpus via NMF, the decoder is trained so that it is more likely to sample response words from the most correlated topic vectors. One of the main advantages in our architecture is that the user can easily switch the NMF-learned topic vectors so that the chatbot obtains desired topic-awareness. We demonstrate our model by training on a single conversational data set which is then augmented with topic matrices learned from different auxiliary data sets. We show that our topic-aware chatbot not only outperforms the non-topic counterpart, but also that each topic-aware model qualitatively and contextually gives the most relevant answer depending on the topic of question.