 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Knowledgeable Deep Research: Framework and Benchmark
Apr 09, 2026Deep Research (DR) requires LLM agents to autonomously perform multi-step information seeking, processing, and reasoning to generate comprehensive reports. In contrast to existing studies that mainly focus on unstructured web content, a more challenging DR task should additionally utilize structured knowledge to provide a solid data foundation, facilitate quantitative computation, and lead to in-depth analyses. In this paper, we refer to this novel task as Knowledgeable Deep Research (KDR), which requires DR agents to generate reports with both structured and unstructured knowledge. Furthermore, we propose the Hybrid Knowledge Analysis framework (HKA), a multi-agent architecture that reasons over both kinds of knowledge and integrates the texts, figures, and tables into coherent multimodal reports. The key design is the Structured Knowledge Analyzer, which utilizes both coding and vision-language models to produce figures, tables, and corresponding insights. To support systematic evaluation, we construct KDR-Bench, which covers 9 domains, includes 41 expert-level questions, and incorporates a large number of structured knowledge resources (e.g., 1,252 tables). We further annotate the main conclusions and key points for each question and propose three categories of evaluation metrics including general-purpose, knowledge-centric, and vision-enhanced ones. Experimental results demonstrate that HKA consistently outperforms most existing DR agents on general-purpose and knowledge-centric metrics, and even surpasses the Gemini DR agent on vision-enhanced metrics, highlighting its effectiveness in deep, structure-aware knowledge analysis. Finally, we hope this work can serve as a new foundation for structured knowledge analysis in DR agents and facilitate future multimodal DR studies.
TR-ICRL: Test-Time Rethinking for In-Context Reinforcement Learning
Apr 01, 2026In-Context Reinforcement Learning (ICRL) enables Large Language Models (LLMs) to learn online from external rewards directly within the context window. However, a central challenge in ICRL is reward estimation, as models typically lack access to ground-truths during inference. To address this limitation, we propose Test-Time Rethinking for In-Context Reinforcement Learning (TR-ICRL), a novel ICRL framework designed for both reasoning and knowledge-intensive tasks. TR-ICRL operates by first retrieving the most relevant instances from an unlabeled evaluation set for a given query. During each ICRL iteration, LLM generates a set of candidate answers for every retrieved instance. Next, a pseudo-label is derived from this set through majority voting. This label then serves as a proxy to give reward messages and generate formative feedbacks, guiding LLM through iterative refinement. In the end, this synthesized contextual information is integrated with the original query to form a comprehensive prompt, with the answer determining through a final round of majority voting. TR-ICRL is evaluated on mainstream reasoning and knowledge-intensive tasks, where it demonstrates significant performance gains. Remarkably, TR-ICRL improves Qwen2.5-7B by 21.23% on average on MedQA and even 137.59% on AIME2024. Extensive ablation studies and analyses further validate the effectiveness and robustness of our approach. Our code is available at https://github.com/pangpang-xuan/TR_ICRL.
OpenClaw-RL: Train Any Agent Simply by Talking
Mar 10, 2026Every agent interaction generates a next-state signal, namely the user reply, tool output, terminal or GUI state change that follows each action, yet no existing agentic RL system recovers it as a live, online learning source. We present OpenClaw-RL, a framework built on a simple observation: next-state signals are universal, and policy can learn from all of them simultaneously. Personal conversations, terminal executions, GUI interactions, SWE tasks, and tool-call traces are not separate training problems. They are all interactions that can be used to train the same policy in the same loop. Next-state signals encode two forms of information: evaluative signals, which indicate how well the action performed and are extracted as scalar rewards via a PRM judge; and directive signals, which indicate how the action should have been different and are recovered through Hindsight-Guided On-Policy Distillation (OPD). We extract textual hints from the next state, construct an enhanced teacher context, and provide token-level directional advantage supervision that is richer than any scalar reward. Due to the asynchronous design, the model serves live requests, the PRM judges ongoing interactions, and the trainer updates the policy at the same time, with zero coordination overhead between them. Applied to personal agents, OpenClaw-RL enables an agent to improve simply by being used, recovering conversational signals from user re-queries, corrections, and explicit feedback. Applied to general agents, the same infrastructure supports scalable RL across terminal, GUI, SWE, and tool-call settings, where we additionally demonstrate the utility of process rewards. Code: https://github.com/Gen-Verse/OpenClaw-RL
Beyond Dialogue Time: Temporal Semantic Memory for Personalized LLM Agents
Jan 12, 2026Memory enables Large Language Model (LLM) agents to perceive, store, and use information from past dialogues, which is essential for personalization. However, existing methods fail to properly model the temporal dimension of memory in two aspects: 1) Temporal inaccuracy: memories are organized by dialogue time rather than their actual occurrence time; 2) Temporal fragmentation: existing methods focus on point-wise memory, losing durative information that captures persistent states and evolving patterns. To address these limitations, we propose Temporal Semantic Memory (TSM), a memory framework that models semantic time for point-wise memory and supports the construction and utilization of durative memory. During memory construction, it first builds a semantic timeline rather than a dialogue one. Then, it consolidates temporally continuous and semantically related information into a durative memory. During memory utilization, it incorporates the query's temporal intent on the semantic timeline, enabling the retrieval of temporally appropriate durative memories and providing time-valid, duration-consistent context to support response generation. Experiments on LongMemEval and LoCoMo show that TSM consistently outperforms existing methods and achieves up to 12.2% absolute improvement in accuracy, demonstrating the effectiveness of the proposed method.
StruProKGR: A Structural and Probabilistic Framework for Sparse Knowledge Graph Reasoning
Dec 14, 2025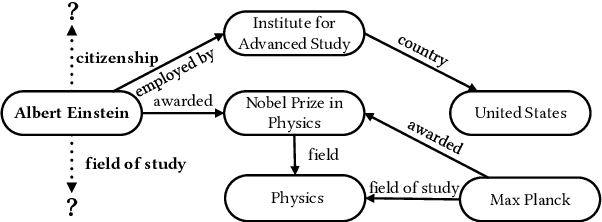
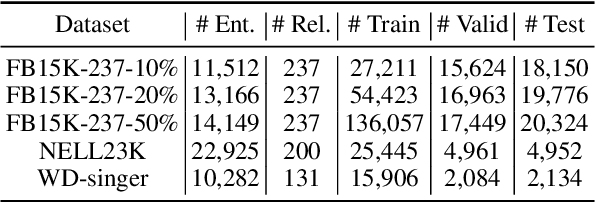
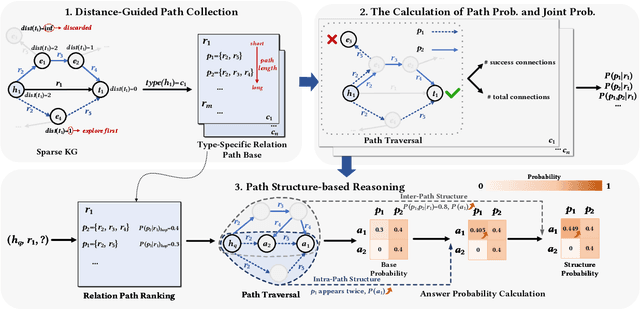
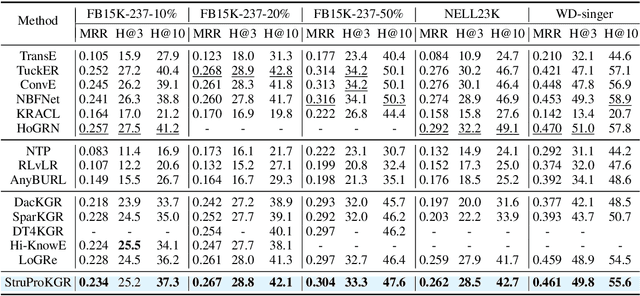
Sparse Knowledge Graphs (KGs) are commonly encountered in real-world applications, where knowledge is often incomplete or limited. Sparse KG reasoning, the task of inferring missing knowledge over sparse KGs, is inherently challenging due to the scarcity of knowledge and the difficulty of capturing relational patterns in sparse scenarios. Among all sparse KG reasoning methods, path-based ones have attracted plenty of attention due to their interpretability. Existing path-based methods typically rely on computationally intensive random walks to collect paths, producing paths of variable quality. Additionally, these methods fail to leverage the structured nature of graphs by treating paths independently. To address these shortcomings, we propose a Structural and Probabilistic framework named StruProKGR, tailored for efficient and interpretable reasoning on sparse KGs. StruProKGR utilizes a distance-guided path collection mechanism to significantly reduce computational costs while exploring more relevant paths. It further enhances the reasoning process by incorporating structural information through probabilistic path aggregation, which prioritizes paths that reinforce each other. Extensive experiments on five sparse KG reasoning benchmarks reveal that StruProKGR surpasses existing path-based methods in both effectiveness and efficiency, providing an effective, efficient, and interpretable solution for sparse KG reasoning.
RouteRAG: Efficient Retrieval-Augmented Generation from Text and Graph via Reinforcement Learning
Dec 10, 2025Retrieval-Augmented Generation (RAG) integrates non-parametric knowledge into Large Language Models (LLMs), typically from unstructured texts and structured graphs. While recent progress has advanced text-based RAG to multi-turn reasoning through Reinforcement Learning (RL), extending these advances to hybrid retrieval introduces additional challenges. Existing graph-based or hybrid systems typically depend on fixed or handcrafted retrieval pipelines, lacking the ability to integrate supplementary evidence as reasoning unfolds. Besides, while graph evidence provides relational structures crucial for multi-hop reasoning, it is substantially more expensive to retrieve. To address these limitations, we introduce \model{}, an RL-based framework that enables LLMs to perform multi-turn and adaptive graph-text hybrid RAG. \model{} jointly optimizes the entire generation process via RL, allowing the model to learn when to reason, what to retrieve from either texts or graphs, and when to produce final answers, all within a unified generation policy. To guide this learning process, we design a two-stage training framework that accounts for both task outcome and retrieval efficiency, enabling the model to exploit hybrid evidence while avoiding unnecessary retrieval overhead. Experimental results across five question answering benchmarks demonstrate that \model{} significantly outperforms existing RAG baselines, highlighting the benefits of end-to-end RL in supporting adaptive and efficient retrieval for complex reasoning.
An Investigation on Group Query Hallucination Attacks
Aug 26, 2025With the widespread use of large language models (LLMs), understanding their potential failure modes during user interactions is essential. In practice, users often pose multiple questions in a single conversation with LLMs. Therefore, in this study, we propose Group Query Attack, a technique that simulates this scenario by presenting groups of queries to LLMs simultaneously. We investigate how the accumulated context from consecutive prompts influences the outputs of LLMs. Specifically, we observe that Group Query Attack significantly degrades the performance of models fine-tuned on specific tasks. Moreover, we demonstrate that Group Query Attack induces a risk of triggering potential backdoors of LLMs. Besides, Group Query Attack is also effective in tasks involving reasoning, such as mathematical reasoning and code generation for pre-trained and aligned models.
ASTRA: Autonomous Spatial-Temporal Red-teaming for AI Software Assistants
Aug 05, 2025AI coding assistants like GitHub Copilot are rapidly transforming software development, but their safety remains deeply uncertain-especially in high-stakes domains like cybersecurity. Current red-teaming tools often rely on fixed benchmarks or unrealistic prompts, missing many real-world vulnerabilities. We present ASTRA, an automated agent system designed to systematically uncover safety flaws in AI-driven code generation and security guidance systems. ASTRA works in three stages: (1) it builds structured domain-specific knowledge graphs that model complex software tasks and known weaknesses; (2) it performs online vulnerability exploration of each target model by adaptively probing both its input space, i.e., the spatial exploration, and its reasoning processes, i.e., the temporal exploration, guided by the knowledge graphs; and (3) it generates high-quality violation-inducing cases to improve model alignment. Unlike prior methods, ASTRA focuses on realistic inputs-requests that developers might actually ask-and uses both offline abstraction guided domain modeling and online domain knowledge graph adaptation to surface corner-case vulnerabilities. Across two major evaluation domains, ASTRA finds 11-66% more issues than existing techniques and produces test cases that lead to 17% more effective alignment training, showing its practical value for building safer AI systems.
A Survey of Link Prediction in N-ary Knowledge Graphs
Jun 10, 2025



N-ary Knowledge Graphs (NKGs) are a specialized type of knowledge graph designed to efficiently represent complex real-world facts. Unlike traditional knowledge graphs, where a fact typically involves two entities, NKGs can capture n-ary facts containing more than two entities. Link prediction in NKGs aims to predict missing elements within these n-ary facts, which is essential for completing NKGs and improving the performance of downstream applications. This task has recently gained significant attention. In this paper, we present the first comprehensive survey of link prediction in NKGs, providing an overview of the field, systematically categorizing existing methods, and analyzing their performance and application scenarios. We also outline promising directions for future research.
KnowCoder-V2: Deep Knowledge Analysis
Jun 07, 2025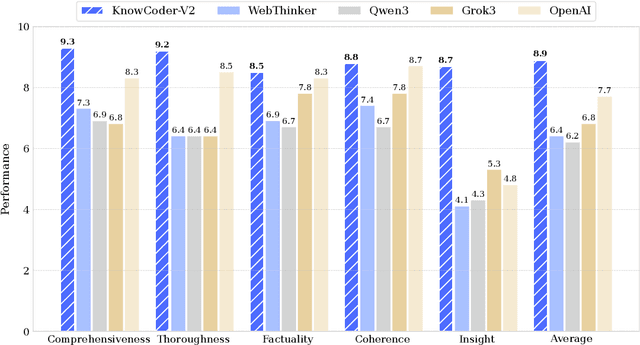
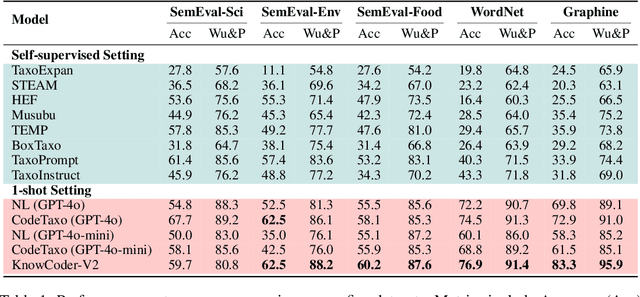
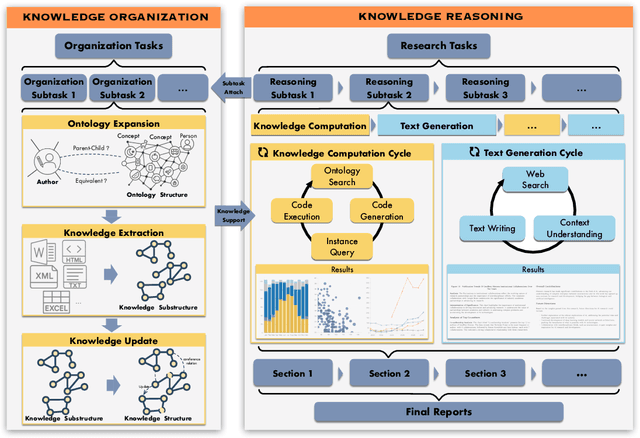
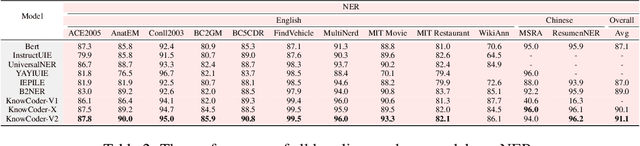
Deep knowledge analysis tasks always involve the systematic extraction and association of knowledge from large volumes of data, followed by logical reasoning to discover insights. However, to solve such complex tasks, existing deep research frameworks face three major challenges: 1) They lack systematic organization and management of knowledge; 2) They operate purely online, making it inefficient for tasks that rely on shared and large-scale knowledge; 3) They cannot perform complex knowledge computation, limiting their abilities to produce insightful analytical results. Motivated by these, in this paper, we propose a \textbf{K}nowledgeable \textbf{D}eep \textbf{R}esearch (\textbf{KDR}) framework that empowers deep research with deep knowledge analysis capability. Specifically, it introduces an independent knowledge organization phase to preprocess large-scale, domain-relevant data into systematic knowledge offline. Based on this knowledge, it extends deep research with an additional kind of reasoning steps that perform complex knowledge computation in an online manner. To enhance the abilities of LLMs to solve knowledge analysis tasks in the above framework, we further introduce \textbf{\KCII}, an LLM that bridges knowledge organization and reasoning via unified code generation. For knowledge organization, it generates instantiation code for predefined classes, transforming data into knowledge objects. For knowledge computation, it generates analysis code and executes on the above knowledge objects to obtain deep analysis results. Experimental results on more than thirty datasets across six knowledge analysis tasks demonstrate the effectiveness of \KCII. Moreover, when integrated into the KDR framework, \KCII can generate high-quality reports with insightful analytical results compared to the mainstream deep research framework.