 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJustRL: Scaling a 1.5B LLM with a Simple RL Recipe
Dec 18, 2025Recent advances in reinforcement learning for large language models have converged on increasing complexity: multi-stage training pipelines, dynamic hyperparameter schedules, and curriculum learning strategies. This raises a fundamental question: \textbf{Is this complexity necessary?} We present \textbf{JustRL}, a minimal approach using single-stage training with fixed hyperparameters that achieves state-of-the-art performance on two 1.5B reasoning models (54.9\% and 64.3\% average accuracy across nine mathematical benchmarks) while using 2$\times$ less compute than sophisticated approaches. The same hyperparameters transfer across both models without tuning, and training exhibits smooth, monotonic improvement over 4,000+ steps without the collapses or plateaus that typically motivate interventions. Critically, ablations reveal that adding ``standard tricks'' like explicit length penalties and robust verifiers may degrade performance by collapsing exploration. These results suggest that the field may be adding complexity to solve problems that disappear with a stable, scaled-up baseline. We release our models and code to establish a simple, validated baseline for the community.
P1: Mastering Physics Olympiads with Reinforcement Learning
Nov 17, 2025Recent progress in large language models (LLMs) has moved the frontier from puzzle-solving to science-grade reasoning-the kind needed to tackle problems whose answers must stand against nature, not merely fit a rubric. Physics is the sharpest test of this shift, which binds symbols to reality in a fundamental way, serving as the cornerstone of most modern technologies. In this work, we manage to advance physics research by developing large language models with exceptional physics reasoning capabilities, especially excel at solving Olympiad-level physics problems. We introduce P1, a family of open-source physics reasoning models trained entirely through reinforcement learning (RL). Among them, P1-235B-A22B is the first open-source model with Gold-medal performance at the latest International Physics Olympiad (IPhO 2025), and wins 12 gold medals out of 13 international/regional physics competitions in 2024/2025. P1-30B-A3B also surpasses almost all other open-source models on IPhO 2025, getting a silver medal. Further equipped with an agentic framework PhysicsMinions, P1-235B-A22B+PhysicsMinions achieves overall No.1 on IPhO 2025, and obtains the highest average score over the 13 physics competitions. Besides physics, P1 models also present great performance on other reasoning tasks like math and coding, showing the great generalibility of P1 series.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Sep 11, 2025Vision-Language-Action (VLA) models have recently emerged as a powerful paradigm for robotic manipulation. Despite substantial progress enabled by large-scale pretraining and supervised fine-tuning (SFT), these models face two fundamental challenges: (i) the scarcity and high cost of large-scale human-operated robotic trajectories required for SFT scaling, and (ii) limited generalization to tasks involving distribution shift. Recent breakthroughs in Large Reasoning Models (LRMs) demonstrate that reinforcement learning (RL) can dramatically enhance step-by-step reasoning capabilities, raising a natural question: Can RL similarly improve the long-horizon step-by-step action planning of VLA? In this work, we introduce SimpleVLA-RL, an efficient RL framework tailored for VLA models. Building upon veRL, we introduce VLA-specific trajectory sampling, scalable parallelization, multi-environment rendering, and optimized loss computation. When applied to OpenVLA-OFT, SimpleVLA-RL achieves SoTA performance on LIBERO and even outperforms $\pi_0$ on RoboTwin 1.0\&2.0 with the exploration-enhancing strategies we introduce. SimpleVLA-RL not only reduces dependence on large-scale data and enables robust generalization, but also remarkably surpasses SFT in real-world tasks. Moreover, we identify a novel phenomenon ``pushcut'' during RL training, wherein the policy discovers previously unseen patterns beyond those seen in the previous training process. Github: https://github.com/PRIME-RL/SimpleVLA-RL
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
Towards a Unified View of Large Language Model Post-Training
Sep 04, 2025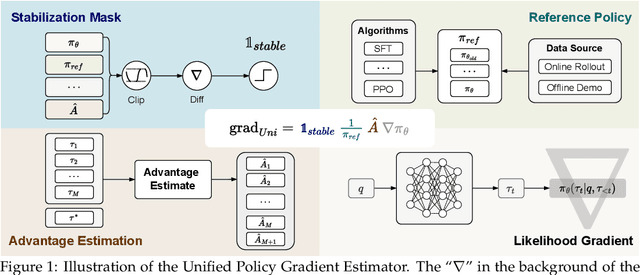

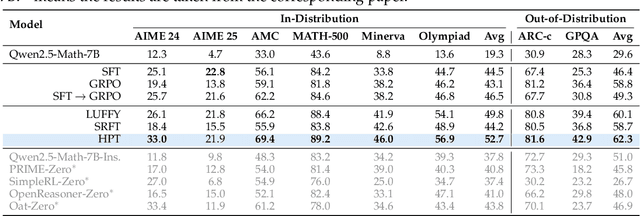
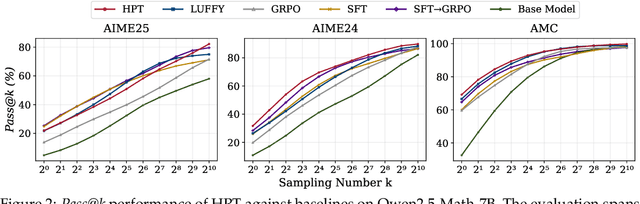
Two major sources of training data exist for post-training modern language models: online (model-generated rollouts) data, and offline (human or other-model demonstrations) data. These two types of data are typically used by approaches like Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT), respectively. In this paper, we show that these approaches are not in contradiction, but are instances of a single optimization process. We derive a Unified Policy Gradient Estimator, and present the calculations of a wide spectrum of post-training approaches as the gradient of a common objective under different data distribution assumptions and various bias-variance tradeoffs. The gradient estimator is constructed with four interchangeable parts: stabilization mask, reference policy denominator, advantage estimate, and likelihood gradient. Motivated by our theoretical findings, we propose Hybrid Post-Training (HPT), an algorithm that dynamically selects different training signals. HPT is designed to yield both effective exploitation of demonstration and stable exploration without sacrificing learned reasoning patterns. We provide extensive experiments and ablation studies to verify the effectiveness of our unified theoretical framework and HPT. Across six mathematical reasoning benchmarks and two out-of-distribution suites, HPT consistently surpasses strong baselines across models of varying scales and families.
Automating Exploratory Multiomics Research via Language Models
Jun 09, 2025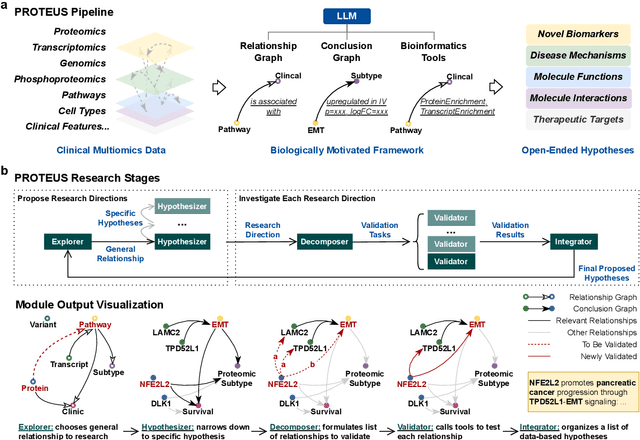
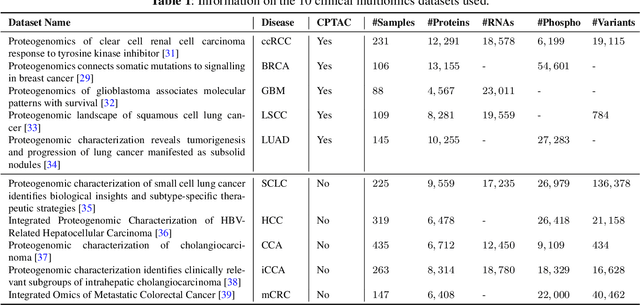
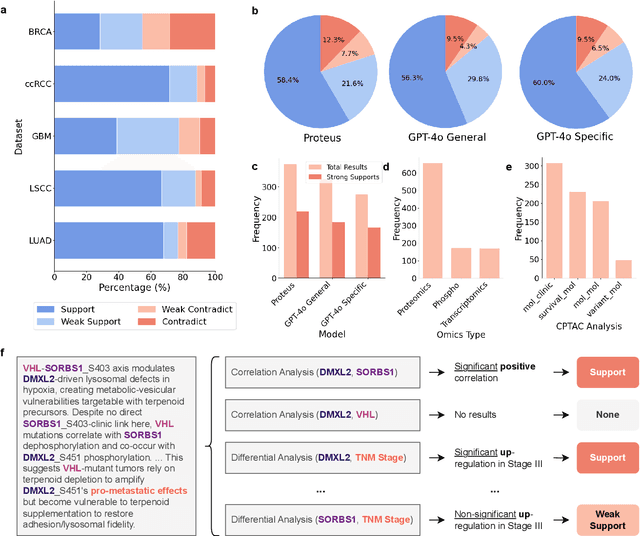

This paper introduces PROTEUS, a fully automated system that produces data-driven hypotheses from raw data files. We apply PROTEUS to clinical proteogenomics, a field where effective downstream data analysis and hypothesis proposal is crucial for producing novel discoveries. PROTEUS uses separate modules to simulate different stages of the scientific process, from open-ended data exploration to specific statistical analysis and hypothesis proposal. It formulates research directions, tools, and results in terms of relationships between biological entities, using unified graph structures to manage complex research processes. We applied PROTEUS to 10 clinical multiomics datasets from published research, arriving at 360 total hypotheses. Results were evaluated through external data validation and automatic open-ended scoring. Through exploratory and iterative research, the system can navigate high-throughput and heterogeneous multiomics data to arrive at hypotheses that balance reliability and novelty. In addition to accelerating multiomic analysis, PROTEUS represents a path towards tailoring general autonomous systems to specialized scientific domains to achieve open-ended hypothesis generation from data.
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
May 28, 2025



This paper aims to overcome a major obstacle in scaling RL for reasoning with LLMs, namely the collapse of policy entropy. Such phenomenon is consistently observed across vast RL runs without entropy intervention, where the policy entropy dropped sharply at the early training stage, this diminished exploratory ability is always accompanied with the saturation of policy performance. In practice, we establish a transformation equation R=-a*e^H+b between entropy H and downstream performance R. This empirical law strongly indicates that, the policy performance is traded from policy entropy, thus bottlenecked by its exhaustion, and the ceiling is fully predictable H=0, R=-a+b. Our finding necessitates entropy management for continuous exploration toward scaling compute for RL. To this end, we investigate entropy dynamics both theoretically and empirically. Our derivation highlights that, the change in policy entropy is driven by the covariance between action probability and the change in logits, which is proportional to its advantage when using Policy Gradient-like algorithms. Empirical study shows that, the values of covariance term and entropy differences matched exactly, supporting the theoretical conclusion. Moreover, the covariance term stays mostly positive throughout training, further explaining why policy entropy would decrease monotonically. Through understanding the mechanism behind entropy dynamics, we motivate to control entropy by restricting the update of high-covariance tokens. Specifically, we propose two simple yet effective techniques, namely Clip-Cov and KL-Cov, which clip and apply KL penalty to tokens with high covariances respectively. Experiments show that these methods encourage exploration, thus helping policy escape entropy collapse and achieve better downstream performance.
TTRL: Test-Time Reinforcement Learning
Apr 22, 2025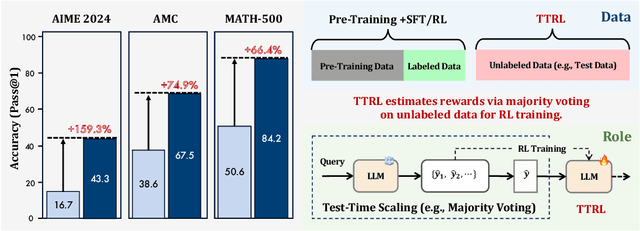
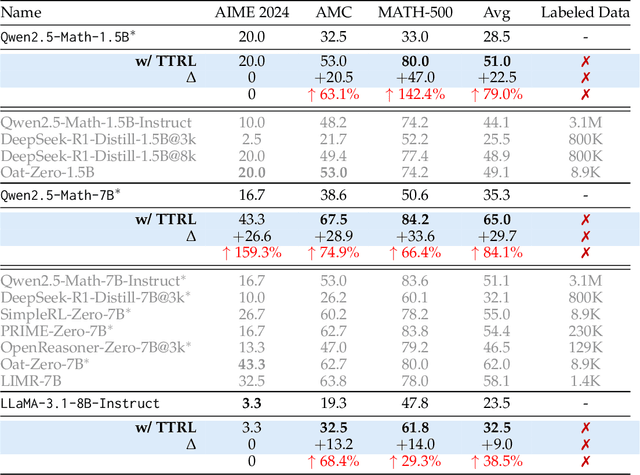
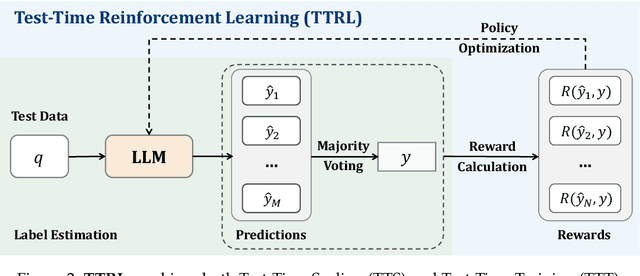
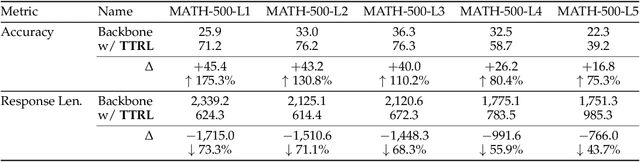
This paper investigates Reinforcement Learning (RL) on data without explicit labels for reasoning tasks in Large Language Models (LLMs). The core challenge of the problem is reward estimation during inference while not having access to ground-truth information. While this setting appears elusive, we find that common practices in Test-Time Scaling (TTS), such as majority voting, yield surprisingly effective rewards suitable for driving RL training. In this work, we introduce Test-Time Reinforcement Learning (TTRL), a novel method for training LLMs using RL on unlabeled data. TTRL enables self-evolution of LLMs by utilizing the priors in the pre-trained models. Our experiments demonstrate that TTRL consistently improves performance across a variety of tasks and models. Notably, TTRL boosts the pass@1 performance of Qwen-2.5-Math-7B by approximately 159% on the AIME 2024 with only unlabeled test data. Furthermore, although TTRL is only supervised by the Maj@N metric, TTRL has demonstrated performance to consistently surpass the upper limit of the initial model, and approach the performance of models trained directly on test data with ground-truth labels. Our experimental findings validate the general effectiveness of TTRL across various tasks, and highlight TTRL's potential for broader tasks and domains. GitHub: https://github.com/PRIME-RL/TTRL
Towards Event Extraction with Massive Types: LLM-based Collaborative Annotation and Partitioning Extraction
Mar 04, 2025Developing a general-purpose extraction system that can extract events with massive types is a long-standing target in Event Extraction (EE). In doing so, the challenge comes from two aspects: 1) The absence of an efficient and effective annotation method. 2) The absence of a powerful extraction method can handle massive types. For the first challenge, we propose a collaborative annotation method based on Large Language Models (LLMs). Through collaboration among multiple LLMs, it first refines annotations of trigger words from distant supervision and then carries out argument annotation. Next, a voting phase consolidates the annotation preferences across different LLMs. Finally, we create the EEMT dataset, the largest EE dataset to date, featuring over 200,000 samples, 3,465 event types, and 6,297 role types. For the second challenge, we propose an LLM-based Partitioning EE method called LLM-PEE. To overcome the limited context length of LLMs, LLM-PEE first recalls candidate event types and then splits them into multiple partitions for LLMs to extract events. The results in the supervised setting show that LLM-PEE outperforms the state-of-the-art methods by 5.4 in event detection and 6.1 in argument extraction. In the zero-shot setting, LLM-PEE achieves up to 12.9 improvement compared to mainstream LLMs, demonstrating its strong generalization capabilities.