 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Vision: Evaluating Multimodal LLMs Logic Understanding and Code Generation Capabilities
Paper and Code
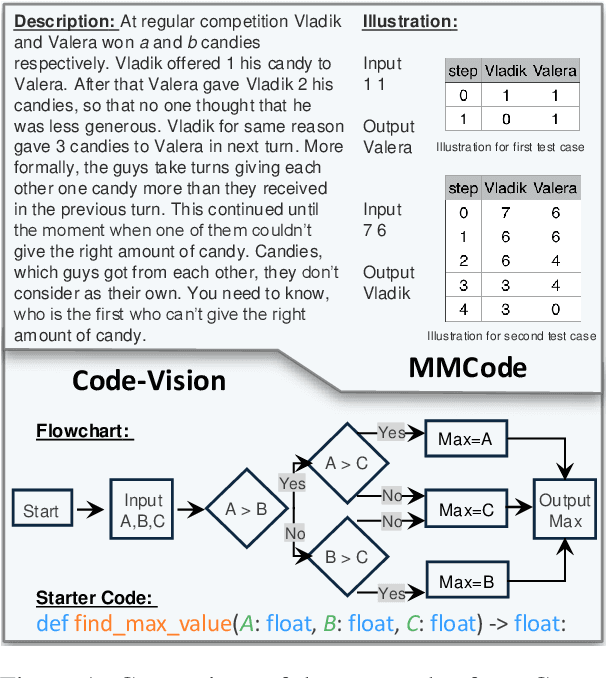

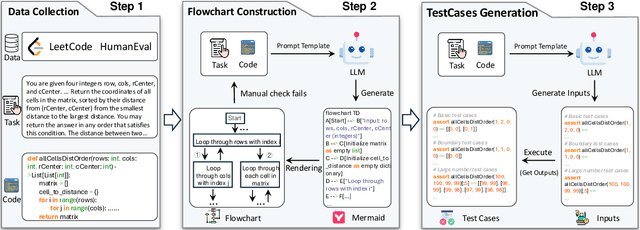
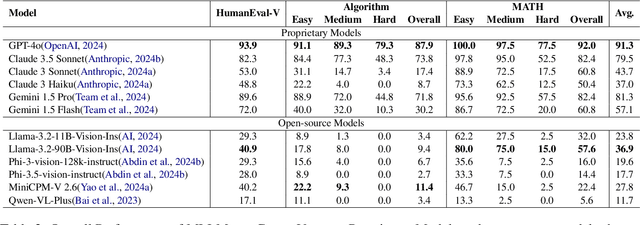
This paper introduces Code-Vision, a benchmark designed to evaluate the logical understanding and code generation capabilities of Multimodal Large Language Models (MLLMs). It challenges MLLMs to generate a correct program that fulfills specific functionality requirements based on a given flowchart, which visually represents the desired algorithm or process. Code-Vision comprises three subsets: HumanEval-V, Algorithm, and MATH, which evaluate MLLMs' coding abilities across basic programming, algorithmic, and mathematical problem-solving domains. Our experiments evaluate 12 MLLMs on Code-Vision. Experimental results demonstrate that there is a large performance difference between proprietary and open-source models. On Hard problems, GPT-4o can achieve 79.3% pass@1, but the best open-source model only achieves 15%. Further experiments reveal that Code-Vision can pose unique challenges compared to other multimodal reasoning benchmarks MMCode and MathVista. We also explore the reason for the poor performance of the open-source models. All data and codes are available at https://github.com/wanghanbinpanda/CodeVision.