 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Vision: Evaluating Multimodal LLMs Logic Understanding and Code Generation Capabilities
Feb 17, 2025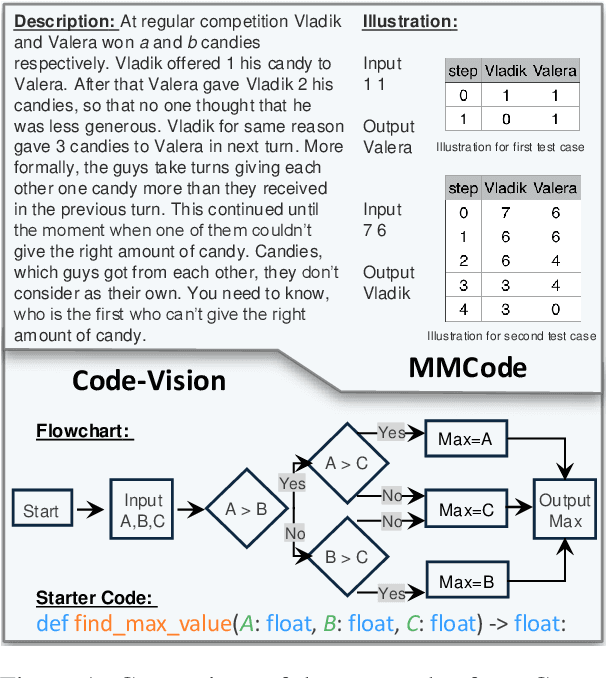

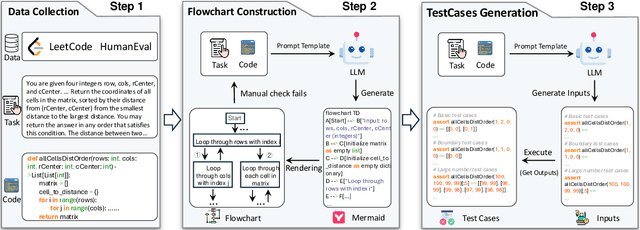
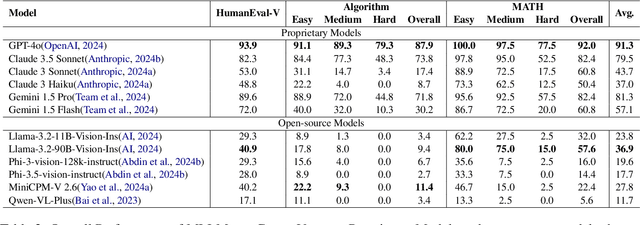
This paper introduces Code-Vision, a benchmark designed to evaluate the logical understanding and code generation capabilities of Multimodal Large Language Models (MLLMs). It challenges MLLMs to generate a correct program that fulfills specific functionality requirements based on a given flowchart, which visually represents the desired algorithm or process. Code-Vision comprises three subsets: HumanEval-V, Algorithm, and MATH, which evaluate MLLMs' coding abilities across basic programming, algorithmic, and mathematical problem-solving domains. Our experiments evaluate 12 MLLMs on Code-Vision. Experimental results demonstrate that there is a large performance difference between proprietary and open-source models. On Hard problems, GPT-4o can achieve 79.3% pass@1, but the best open-source model only achieves 15%. Further experiments reveal that Code-Vision can pose unique challenges compared to other multimodal reasoning benchmarks MMCode and MathVista. We also explore the reason for the poor performance of the open-source models. All data and codes are available at https://github.com/wanghanbinpanda/CodeVision.
Bridging Modality Gap for Visual Grounding with Effecitve Cross-modal Distillation
Dec 29, 2023Visual grounding aims to align visual information of specific regions of images with corresponding natural language expressions. Current visual grounding methods leverage pre-trained visual and language backbones separately to obtain visual features and linguistic features. Although these two types of features are then fused via delicately designed networks, the heterogeneity of the features makes them inapplicable for multi-modal reasoning. This problem arises from the domain gap between the single-modal pre-training backbone used in current visual grounding methods, which can hardly be overcome by the traditional end-to-end training method. To alleviate this, our work proposes an Empowering pre-trained model for Visual Grounding (EpmVG) framework, which distills a multimodal pre-trained model to guide the visual grounding task. EpmVG is based on a novel cross-modal distillation mechanism, which can effectively introduce the consistency information of images and texts in the pre-trained model, to reduce the domain gap existing in the backbone networks, thereby improving the performance of the model in the visual grounding task. Extensive experiments are carried out on five conventionally used datasets, and results demonstrate that our method achieves better performance than state-of-the-art methods.