 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS: Unleashing the Power of Speculative Decoding via Margin-Aware Verification
Jan 21, 2026Speculative Decoding (SD) accelerates autoregressive large language model (LLM) inference by decoupling generation and verification. While recent methods improve draft quality by tightly coupling the drafter with the target model, the verification mechanism itself remains largely unchanged, relying on strict token-level rejection sampling. In practice, modern LLMs frequently operate in low-margin regimes where the target model exhibits weak preference among top candidates. In such cases, rejecting plausible runner-up tokens yields negligible information gain while incurring substantial rollback cost, leading to a fundamental inefficiency in verification. We propose Margin-Aware Speculative Verification, a training-free and domain-agnostic verification strategy that adapts to the target model's local decisiveness. Our method conditions verification on decision stability measured directly from the target logits and relaxes rejection only when strict verification provides minimal benefit. Importantly, the approach modifies only the verification rule and is fully compatible with existing target-coupled speculative decoding frameworks. Extensive experiments across model scales ranging from 8B to 235B demonstrate that our method delivers consistent and significant inference speedups over state-of-the-art baselines while preserving generation quality across diverse benchmarks.
Teaching Large Reasoning Models Effective Reflection
Jan 19, 2026Large Reasoning Models (LRMs) have recently shown impressive performance on complex reasoning tasks, often by engaging in self-reflective behaviors such as self-critique and backtracking. However, not all reflections are beneficial-many are superficial, offering little to no improvement over the original answer and incurring computation overhead. In this paper, we identify and address the problem of superficial reflection in LRMs. We first propose Self-Critique Fine-Tuning (SCFT), a training framework that enhances the model's reflective reasoning ability using only self-generated critiques. SCFT prompts models to critique their own outputs, filters high-quality critiques through rejection sampling, and fine-tunes the model using a critique-based objective. Building on this strong foundation, we further introduce Reinforcement Learning with Effective Reflection Rewards (RLERR). RLERR leverages the high-quality reflections initialized by SCFT to construct reward signals, guiding the model to internalize the self-correction process via reinforcement learning. Experiments on two challenging benchmarks, AIME2024 and AIME2025, show that SCFT and RLERR significantly improve both reasoning accuracy and reflection quality, outperforming state-of-the-art baselines. All data and codes are available at https://github.com/wanghanbinpanda/SCFT.
Group Pattern Selection Optimization: Let LRMs Pick the Right Pattern for Reasoning
Jan 12, 2026Large reasoning models (LRMs) exhibit diverse high-level reasoning patterns (e.g., direct solution, reflection-and-verification, and exploring multiple solutions), yet prevailing training recipes implicitly bias models toward a limited set of dominant patterns. Through a systematic analysis, we identify substantial accuracy variance across these patterns on mathematics and science benchmarks, revealing that a model's default reasoning pattern is often sub-optimal for a given problem. To address this, we introduce Group Pattern Selection Optimization (GPSO), a reinforcement learning framework that extends GRPO by incorporating multi-pattern rollouts, verifier-guided optimal pattern selection per problem, and attention masking during optimization to prevent the leakage of explicit pattern suffixes into the learned policy. By exploring a portfolio of diverse reasoning strategies and optimizing the policy on the most effective ones, GPSO enables the model to internalize the mapping from problem characteristics to optimal reasoning patterns. Extensive experiments demonstrate that GPSO delivers consistent and substantial performance gains across various model backbones and benchmarks, effectively mitigating pattern sub-optimality and fostering more robust, adaptable reasoning. All data and codes are available at https://github.com/wanghanbinpanda/GPSO.
Code-Vision: Evaluating Multimodal LLMs Logic Understanding and Code Generation Capabilities
Feb 17, 2025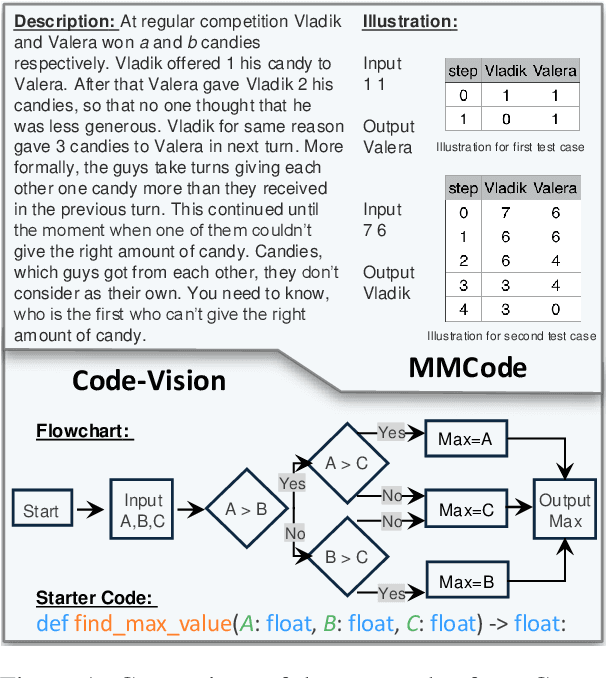

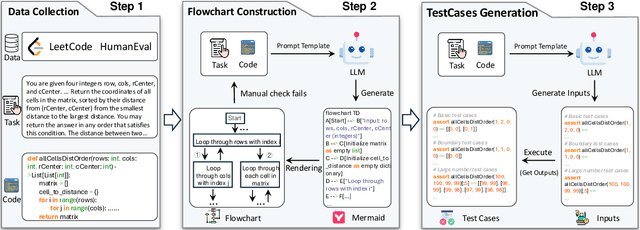
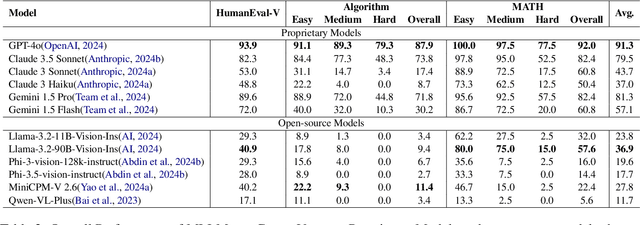
This paper introduces Code-Vision, a benchmark designed to evaluate the logical understanding and code generation capabilities of Multimodal Large Language Models (MLLMs). It challenges MLLMs to generate a correct program that fulfills specific functionality requirements based on a given flowchart, which visually represents the desired algorithm or process. Code-Vision comprises three subsets: HumanEval-V, Algorithm, and MATH, which evaluate MLLMs' coding abilities across basic programming, algorithmic, and mathematical problem-solving domains. Our experiments evaluate 12 MLLMs on Code-Vision. Experimental results demonstrate that there is a large performance difference between proprietary and open-source models. On Hard problems, GPT-4o can achieve 79.3% pass@1, but the best open-source model only achieves 15%. Further experiments reveal that Code-Vision can pose unique challenges compared to other multimodal reasoning benchmarks MMCode and MathVista. We also explore the reason for the poor performance of the open-source models. All data and codes are available at https://github.com/wanghanbinpanda/CodeVision.
Process Reinforcement through Implicit Rewards
Feb 03, 2025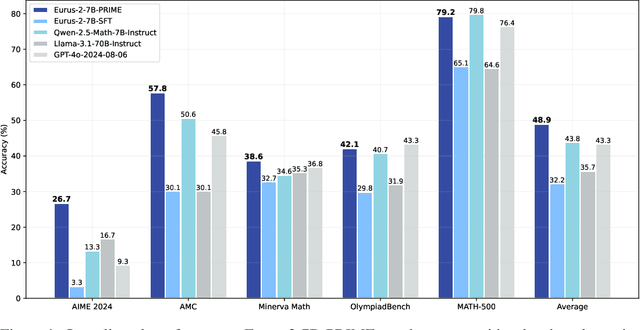

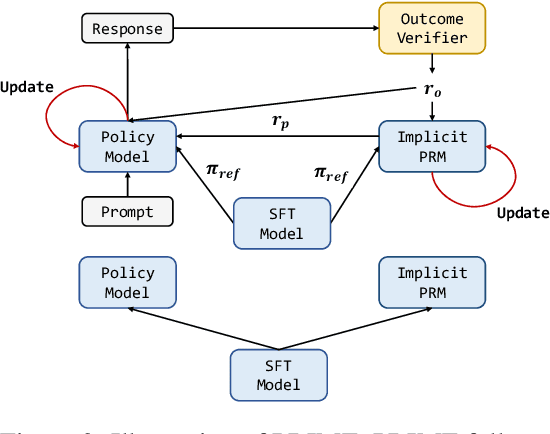
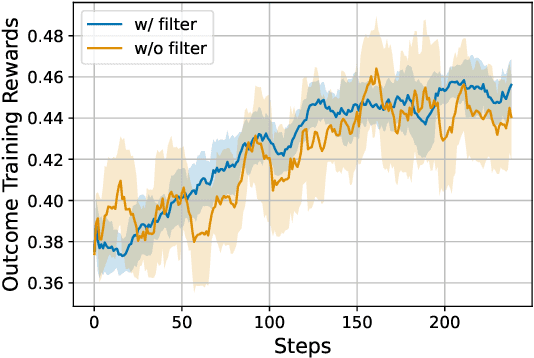
Dense process rewards have proven a more effective alternative to the sparse outcome-level rewards in the inference-time scaling of large language models (LLMs), particularly in tasks requiring complex multi-step reasoning. While dense rewards also offer an appealing choice for the reinforcement learning (RL) of LLMs since their fine-grained rewards have the potential to address some inherent issues of outcome rewards, such as training efficiency and credit assignment, this potential remains largely unrealized. This can be primarily attributed to the challenges of training process reward models (PRMs) online, where collecting high-quality process labels is prohibitively expensive, making them particularly vulnerable to reward hacking. To address these challenges, we propose PRIME (Process Reinforcement through IMplicit rEwards), which enables online PRM updates using only policy rollouts and outcome labels through implict process rewards. PRIME combines well with various advantage functions and forgoes the dedicated reward model training phrase that existing approaches require, substantially reducing the development overhead. We demonstrate PRIME's effectiveness on competitional math and coding. Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 15.1% average improvement across several key reasoning benchmarks over the SFT model. Notably, our resulting model, Eurus-2-7B-PRIME, surpasses Qwen2.5-Math-7B-Instruct on seven reasoning benchmarks with 10% of its training data.
AADNet: Exploring EEG Spatiotemporal Information for Fast and Accurate Orientation and Timbre Detection of Auditory Attention Based on A Cue-Masked Paradigm
Jan 07, 2025Auditory attention decoding from electroencephalogram (EEG) could infer to which source the user is attending in noisy environments. Decoding algorithms and experimental paradigm designs are crucial for the development of technology in practical applications. To simulate real-world scenarios, this study proposed a cue-masked auditory attention paradigm to avoid information leakage before the experiment. To obtain high decoding accuracy with low latency, an end-to-end deep learning model, AADNet, was proposed to exploit the spatiotemporal information from the short time window of EEG signals. The results showed that with a 0.5-second EEG window, AADNet achieved an average accuracy of 93.46% and 91.09% in decoding auditory orientation attention (OA) and timbre attention (TA), respectively. It significantly outperformed five previous methods and did not need the knowledge of the original audio source. This work demonstrated that it was possible to detect the orientation and timbre of auditory attention from EEG signals fast and accurately. The results are promising for the real-time multi-property auditory attention decoding, facilitating the application of the neuro-steered hearing aids and other assistive listening devices.
AlignXIE: Improving Multilingual Information Extraction by Cross-Lingual Alignment
Nov 07, 2024
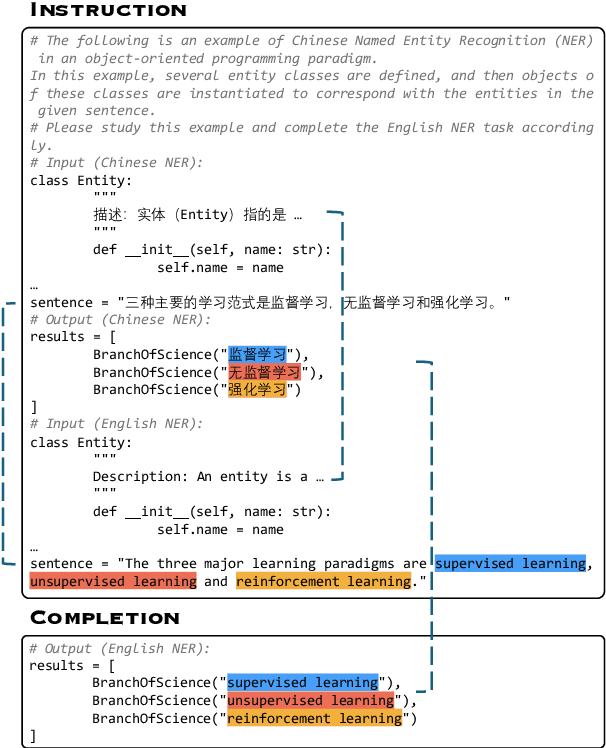


Empirical evidence suggests that LLMs exhibit spontaneous cross-lingual alignment. Our findings suggest that although LLMs also demonstrate promising cross-lingual alignment in Information Extraction, there remains significant imbalance across languages, revealing an underlying deficiency in the IE alignment. To address this issue, we propose AlignXIE, a powerful code-based LLM that significantly enhances cross-lingual IE alignment through two strategies. Firstly, AlignXIE formulates IE across different languages, especially non-English ones, as code generation tasks, standardizing the representation of various schemas using Python classes to ensure consistency of the same ontology in different languages and align the schema. Secondly, it incorporates an IE cross-lingual alignment phase through a translated instance prediction task proposed in this paper to align the extraction process, utilizing ParallelNER, an IE bilingual parallel dataset with 257,190 samples, generated by our proposed LLM-based automatic pipeline for IE parallel data construction, with manual annotation to ensure quality. Ultimately, we obtain AlignXIE through multilingual IE instruction tuning. Although without training in 9 unseen languages, AlignXIE surpasses ChatGPT by $30.17\%$ and SoTA by $20.03\%$, thereby demonstrating superior cross-lingual IE capabilities. Comprehensive evaluations on 63 IE benchmarks in Chinese and English under various settings, demonstrate that AlignXIE significantly enhances cross-lingual and multilingual IE through boosting the IE alignment.
Building A Coding Assistant via the Retrieval-Augmented Language Model
Oct 21, 2024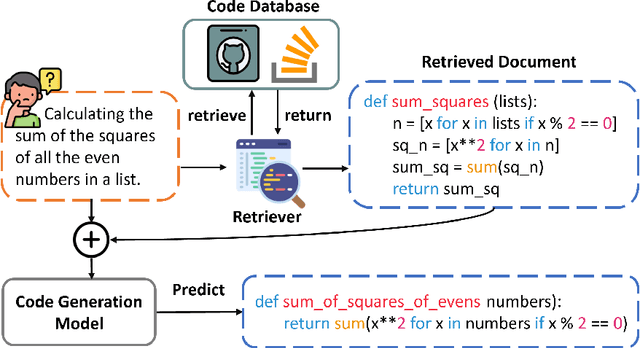

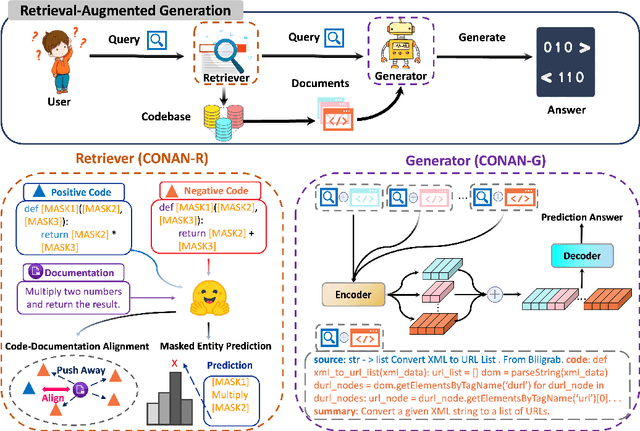
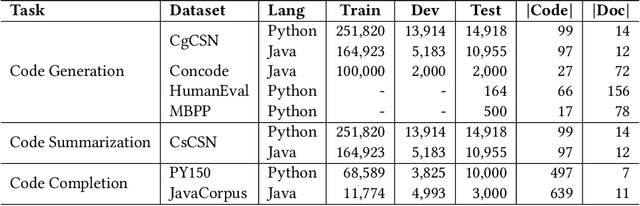
Pretrained language models have shown strong effectiveness in code-related tasks, such as code retrieval, code generation, code summarization, and code completion tasks. In this paper, we propose COde assistaNt viA retrieval-augmeNted language model (CONAN), which aims to build a code assistant by mimicking the knowledge-seeking behaviors of humans during coding. Specifically, it consists of a code structure aware retriever (CONAN-R) and a dual-view code representation-based retrieval-augmented generation model (CONAN-G). CONAN-R pretrains CodeT5 using Code-Documentation Alignment and Masked Entity Prediction tasks to make language models code structure-aware and learn effective representations for code snippets and documentation. Then CONAN-G designs a dual-view code representation mechanism for implementing a retrieval-augmented code generation model. CONAN-G regards the code documentation descriptions as prompts, which help language models better understand the code semantics. Our experiments show that CONAN achieves convincing performance on different code generation tasks and significantly outperforms previous retrieval augmented code generation models. Our further analyses show that CONAN learns tailored representations for both code snippets and documentation by aligning code-documentation data pairs and capturing structural semantics by masking and predicting entities in the code data. Additionally, the retrieved code snippets and documentation provide necessary information from both program language and natural language to assist the code generation process. CONAN can also be used as an assistant for Large Language Models (LLMs), providing LLMs with external knowledge in shorter code document lengths to improve their effectiveness on various code tasks. It shows the ability of CONAN to extract necessary information and help filter out the noise from retrieved code documents.
Enhancing the Code Debugging Ability of LLMs via Communicative Agent Based Data Refinement
Aug 09, 2024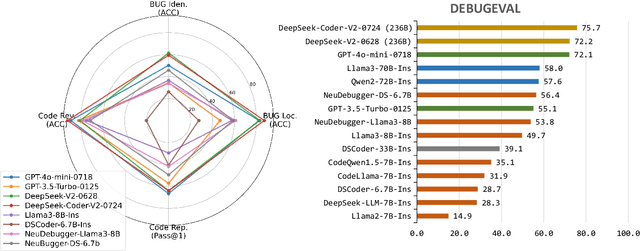
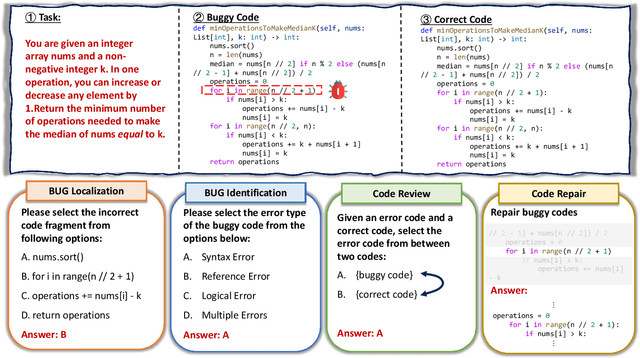
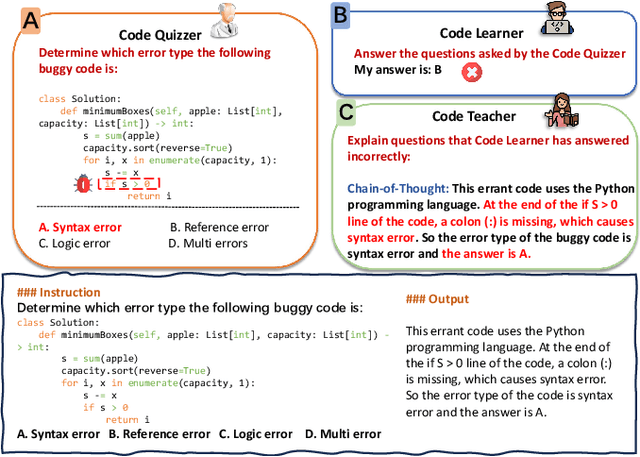

Debugging is a vital aspect of software development, yet the debugging capabilities of Large Language Models (LLMs) remain largely unexplored. This paper first introduces DEBUGEVAL, a comprehensive benchmark designed to evaluate the debugging capabilities of LLMs. DEBUGEVAL collects data from existing high-quality datasets and designs four different tasks to evaluate the debugging effectiveness, including BUG Localization, BUG Identification, Code Review, and Code Repair. Additionally, to enhance the code debugging ability of LLMs, this paper proposes a CoMmunicative Agent BaSed DaTa REfinement FRamework (MASTER), which generates the refined code debugging data for supervised finetuning. Specifically, MASTER employs the Code Quizzer to generate refined data according to the defined tasks of DEBUGEVAL. Then the Code Learner acts as a critic and reserves the generated problems that it can not solve. Finally, the Code Teacher provides a detailed Chain-of-Thought based solution to deal with the generated problem. We collect the synthesized data and finetune the Code Learner to enhance the debugging ability and conduct the NeuDebugger model. Our experiments evaluate various LLMs and NeuDebugger in the zero-shot setting on DEBUGEVAL. Experimental results demonstrate that these 7B-scale LLMs have weaker debugging capabilities, even these code-oriented LLMs. On the contrary, these larger models (over 70B) show convincing debugging ability. Our further analyses illustrate that MASTER is an effective method to enhance the code debugging ability by synthesizing data for Supervised Fine-Tuning (SFT) LLMs.
Advancing LLM Reasoning Generalists with Preference Trees
Apr 02, 2024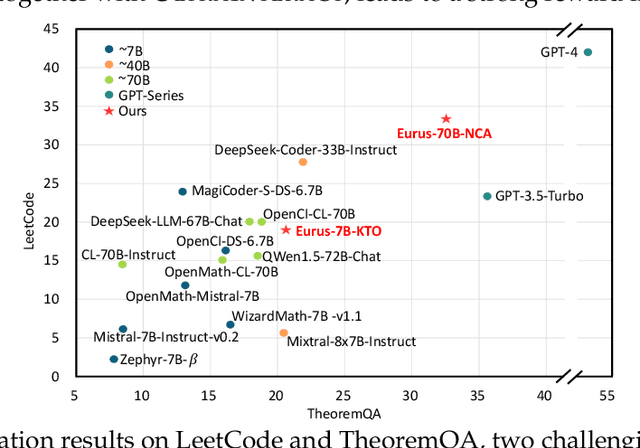
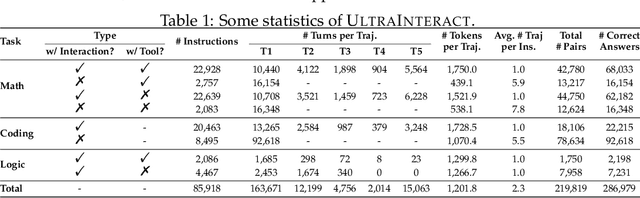
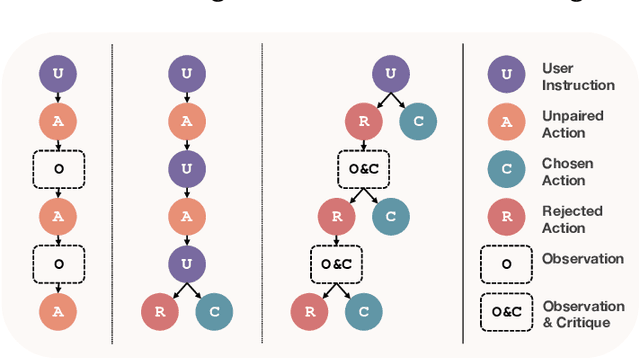

We introduce Eurus, a suite of large language models (LLMs) optimized for reasoning. Finetuned from Mistral-7B and CodeLlama-70B, Eurus models achieve state-of-the-art results among open-source models on a diverse set of benchmarks covering mathematics, code generation, and logical reasoning problems. Notably, Eurus-70B beats GPT-3.5 Turbo in reasoning through a comprehensive benchmarking across 12 tests covering five tasks, and achieves a 33.3% pass@1 accuracy on LeetCode and 32.6% on TheoremQA, two challenging benchmarks, substantially outperforming existing open-source models by margins more than 13.3%. The strong performance of Eurus can be primarily attributed to UltraInteract, our newly-curated large-scale, high-quality alignment dataset specifically designed for complex reasoning tasks. UltraInteract can be used in both supervised fine-tuning and preference learning. For each instruction, it includes a preference tree consisting of (1) reasoning chains with diverse planning strategies in a unified format, (2) multi-turn interaction trajectories with the environment and the critique, and (3) pairwise data to facilitate preference learning. UltraInteract allows us to conduct an in-depth exploration of preference learning for reasoning tasks. Our investigation reveals that some well-established preference learning algorithms may be less suitable for reasoning tasks compared to their effectiveness in general conversations. Inspired by this, we derive a novel reward modeling objective which, together with UltraInteract, leads to a strong reward model.