 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Anchored Knowledge Indexing for Retrieval-Augmented Generation
Jan 23, 2026Retrieval-Augmented Generation (RAG) has emerged as a dominant paradigm for mitigating hallucinations in Large Language Models (LLMs) by incorporating external knowledge. Nevertheless, effectively integrating and interpreting key evidence scattered across noisy documents remains a critical challenge for existing RAG systems. In this paper, we propose GraphAnchor, a novel Graph-Anchored Knowledge Indexing approach that reconceptualizes graph structures from static knowledge representations into active, evolving knowledge indices. GraphAnchor incrementally updates a graph during iterative retrieval to anchor salient entities and relations, yielding a structured index that guides the LLM in evaluating knowledge sufficiency and formulating subsequent subqueries. The final answer is generated by jointly leveraging all retrieved documents and the final evolved graph. Experiments on four multi-hop question answering benchmarks demonstrate the effectiveness of GraphAnchor, and reveal that GraphAnchor modulates the LLM's attention to more effectively associate key information distributed in retrieved documents. All code and data are available at https://github.com/NEUIR/GraphAnchor.
MSC-180: A Benchmark for Automated Formal Theorem Proving from Mathematical Subject Classification
Dec 20, 2025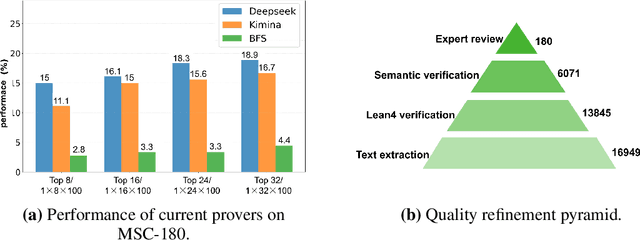



Automated Theorem Proving (ATP) represents a core research direction in artificial intelligence for achieving formal reasoning and verification, playing a significant role in advancing machine intelligence. However, current large language model (LLM)-based theorem provers suffer from limitations such as restricted domain coverage and weak generalization in mathematical reasoning. To address these issues, we propose MSC-180, a benchmark for evaluation based on the MSC2020 mathematical subject classification. It comprises 180 formal verification problems, 3 advanced problems from each of 60 mathematical branches, spanning from undergraduate to graduate levels. Each problem has undergone multiple rounds of verification and refinement by domain experts to ensure formal accuracy. Evaluations of state-of-the-art LLM-based theorem provers under the pass@32 setting reveal that the best model achieves only an 18.89% overall pass rate, with prominent issues including significant domain bias (maximum domain coverage 41.7%) and a difficulty gap (significantly lower pass rates on graduate-level problems). To further quantify performance variability across mathematical domains, we introduce the coefficient of variation (CV) as an evaluation metric. The observed CV values are 4-6 times higher than the statistical high-variability threshold, indicating that the models still rely on pattern matching from training corpora rather than possessing transferable reasoning mechanisms and systematic generalization capabilities. MSC-180, together with its multi-dimensional evaluation framework, provides a discriminative and systematic benchmark for driving the development of next-generation AI systems with genuine mathematical reasoning abilities.
Advancing Knowledge Tracing by Exploring Follow-up Performance Trends
Aug 11, 2025


Intelligent Tutoring Systems (ITS), such as Massive Open Online Courses, offer new opportunities for human learning. At the core of such systems, knowledge tracing (KT) predicts students' future performance by analyzing their historical learning activities, enabling an accurate evaluation of students' knowledge states over time. We show that existing KT methods often encounter correlation conflicts when analyzing the relationships between historical learning sequences and future performance. To address such conflicts, we propose to extract so-called Follow-up Performance Trends (FPTs) from historical ITS data and to incorporate them into KT. We propose a method called Forward-Looking Knowledge Tracing (FINER) that combines historical learning sequences with FPTs to enhance student performance prediction accuracy. FINER constructs learning patterns that facilitate the retrieval of FPTs from historical ITS data in linear time; FINER includes a novel similarity-aware attention mechanism that aggregates FPTs based on both frequency and contextual similarity; and FINER offers means of combining FPTs and historical learning sequences to enable more accurate prediction of student future performance. Experiments on six real-world datasets show that FINER can outperform ten state-of-the-art KT methods, increasing accuracy by 8.74% to 84.85%.
Automated Formalization via Conceptual Retrieval-Augmented LLMs
Aug 09, 2025



Interactive theorem provers (ITPs) require manual formalization, which is labor-intensive and demands expert knowledge. While automated formalization offers a potential solution, it faces two major challenges: model hallucination (e.g., undefined predicates, symbol misuse, and version incompatibility) and the semantic gap caused by ambiguous or missing premises in natural language descriptions. To address these issues, we propose CRAMF, a Concept-driven Retrieval-Augmented Mathematical Formalization framework. CRAMF enhances LLM-based autoformalization by retrieving formal definitions of core mathematical concepts, providing contextual grounding during code generation. However, applying retrieval-augmented generation (RAG) in this setting is non-trivial due to the lack of structured knowledge bases, the polymorphic nature of mathematical concepts, and the high precision required in formal retrieval. We introduce a framework for automatically constructing a concept-definition knowledge base from Mathlib4, the standard mathematical library for the Lean 4 theorem prover, indexing over 26,000 formal definitions and 1,000+ core mathematical concepts. To address conceptual polymorphism, we propose contextual query augmentation with domain- and application-level signals. In addition, we design a dual-channel hybrid retrieval strategy with reranking to ensure accurate and relevant definition retrieval. Experiments on miniF2F, ProofNet, and our newly proposed AdvancedMath benchmark show that CRAMF can be seamlessly integrated into LLM-based autoformalizers, yielding consistent improvements in translation accuracy, achieving up to 62.1% and an average of 29.9% relative improvement.
Learning to Route Queries Across Knowledge Bases for Step-wise Retrieval-Augmented Reasoning
May 28, 2025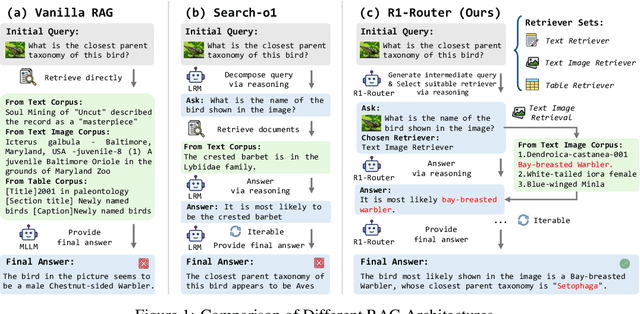
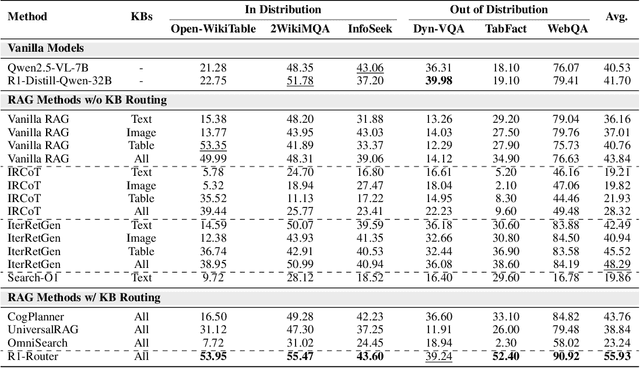
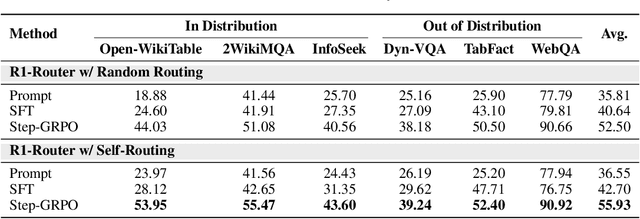
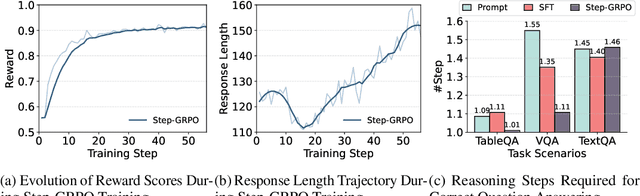
Multimodal Retrieval-Augmented Generation (MRAG) has shown promise in mitigating hallucinations in Multimodal Large Language Models (MLLMs) by incorporating external knowledge during generation. Existing MRAG methods typically adopt a static retrieval pipeline that fetches relevant information from multiple Knowledge Bases (KBs), followed by a refinement step. However, these approaches overlook the reasoning and planning capabilities of MLLMs to dynamically determine how to interact with different KBs during the reasoning process. To address this limitation, we propose R1-Router, a novel MRAG framework that learns to decide when and where to retrieve knowledge based on the evolving reasoning state. Specifically, R1-Router can generate follow-up queries according to the current reasoning step, routing these intermediate queries to the most suitable KB, and integrating external knowledge into a coherent reasoning trajectory to answer the original query. Furthermore, we introduce Step-wise Group Relative Policy Optimization (Step-GRPO), a tailored reinforcement learning algorithm that assigns step-specific rewards to optimize the reasoning behavior of MLLMs. Experimental results on various open-domain QA benchmarks across multiple modalities demonstrate that R1-Router outperforms baseline models by over 7%. Further analysis shows that R1-Router can adaptively and effectively leverage diverse KBs, reducing unnecessary retrievals and improving both efficiency and accuracy.
EULER: Enhancing the Reasoning Ability of Large Language Models through Error-Induced Learning
May 28, 2025Large Language Models (LLMs) have demonstrated strong reasoning capabilities and achieved promising results in mathematical problem-solving tasks. Learning from errors offers the potential to further enhance the performance of LLMs during Supervised Fine-Tuning (SFT). However, the errors in synthesized solutions are typically gathered from sampling trails, making it challenging to generate solution errors for each mathematical problem. This paper introduces the Error-IndUced LEaRning (EULER) model, which aims to develop an error exposure model that generates high-quality solution errors to enhance the mathematical reasoning capabilities of LLMs. Specifically, EULER optimizes the error exposure model to increase the generation probability of self-made solution errors while utilizing solutions produced by a superior LLM to regularize the generation quality. Our experiments across various mathematical problem datasets demonstrate the effectiveness of the EULER model, achieving an improvement of over 4% compared to all baseline models. Further analysis reveals that EULER is capable of synthesizing more challenging and educational solution errors, which facilitate both the training and inference processes of LLMs. All codes are available at https://github.com/NEUIR/EULER.
Enhancing the Code Debugging Ability of LLMs via Communicative Agent Based Data Refinement
Aug 09, 2024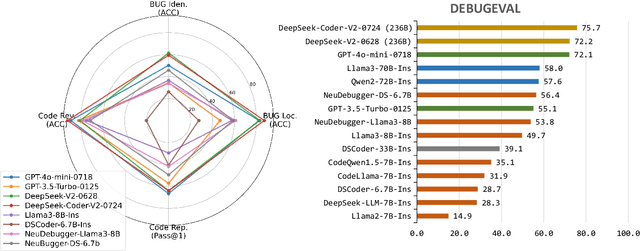
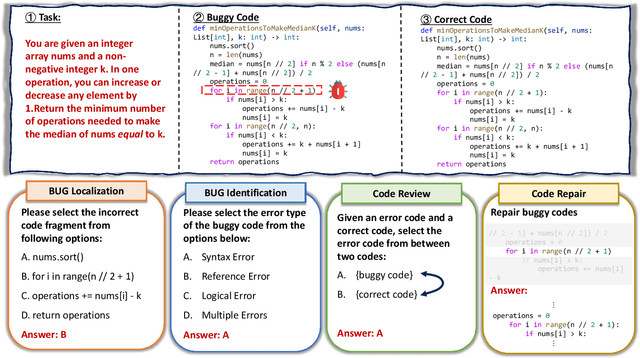
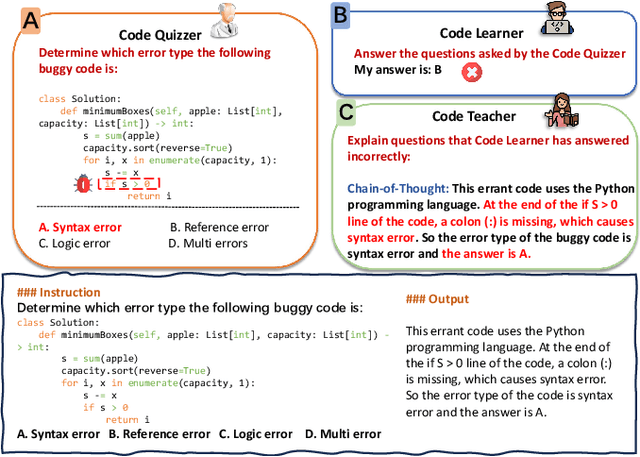

Debugging is a vital aspect of software development, yet the debugging capabilities of Large Language Models (LLMs) remain largely unexplored. This paper first introduces DEBUGEVAL, a comprehensive benchmark designed to evaluate the debugging capabilities of LLMs. DEBUGEVAL collects data from existing high-quality datasets and designs four different tasks to evaluate the debugging effectiveness, including BUG Localization, BUG Identification, Code Review, and Code Repair. Additionally, to enhance the code debugging ability of LLMs, this paper proposes a CoMmunicative Agent BaSed DaTa REfinement FRamework (MASTER), which generates the refined code debugging data for supervised finetuning. Specifically, MASTER employs the Code Quizzer to generate refined data according to the defined tasks of DEBUGEVAL. Then the Code Learner acts as a critic and reserves the generated problems that it can not solve. Finally, the Code Teacher provides a detailed Chain-of-Thought based solution to deal with the generated problem. We collect the synthesized data and finetune the Code Learner to enhance the debugging ability and conduct the NeuDebugger model. Our experiments evaluate various LLMs and NeuDebugger in the zero-shot setting on DEBUGEVAL. Experimental results demonstrate that these 7B-scale LLMs have weaker debugging capabilities, even these code-oriented LLMs. On the contrary, these larger models (over 70B) show convincing debugging ability. Our further analyses illustrate that MASTER is an effective method to enhance the code debugging ability by synthesizing data for Supervised Fine-Tuning (SFT) LLMs.
A Probabilistic Generative Model for Tracking Multi-Knowledge Concept Mastery Probability
Feb 17, 2023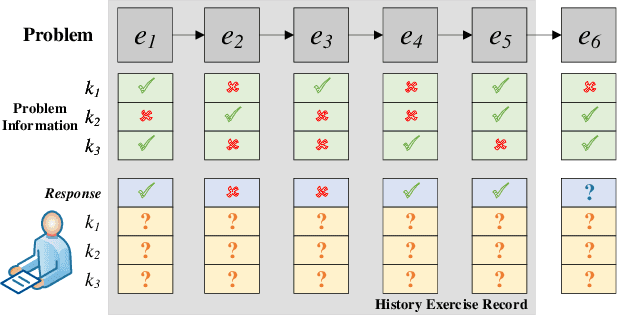

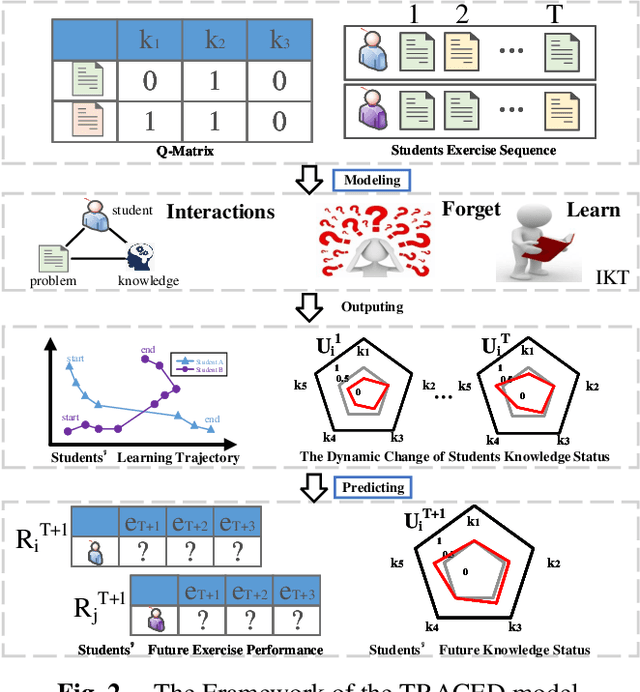

Knowledge tracing aims to track students' knowledge status over time to predict students' future performance accurately. Markov chain-based knowledge tracking (MCKT) models can track knowledge concept mastery probability over time. However, as the number of tracked knowledge concepts increases, the time complexity of MCKT predicting student performance increases exponentially (also called explaining away problem. In addition, the existing MCKT models only consider the relationship between students' knowledge status and problems when modeling students' responses but ignore the relationship between knowledge concepts in the same problem. To address these challenges, we propose an inTerpretable pRobAbilistiC gEnerative moDel (TRACED), which can track students' numerous knowledge concepts mastery probabilities over time. To solve \emph{explain away problem}, we design Long and Short-Term Memory (LSTM)-based networks to approximate the posterior distribution, predict students' future performance, and propose a heuristic algorithm to train LSTMs and probabilistic graphical model jointly. To better model students' exercise responses, we proposed a logarithmic linear model with three interactive strategies, which models students' exercise responses by considering the relationship among students' knowledge status, knowledge concept, and problems. We conduct experiments with four real-world datasets in three knowledge-driven tasks. The experimental results show that TRACED outperforms existing knowledge tracing methods in predicting students' future performance and can learn the relationship among students, knowledge concepts, and problems from students' exercise sequences. We also conduct several case studies. The case studies show that TRACED exhibits excellent interpretability and thus has the potential for personalized automatic feedback in the real-world educational environment.
AIBench: An Industry Standard AI Benchmark Suite from Internet Services
Apr 30, 2020
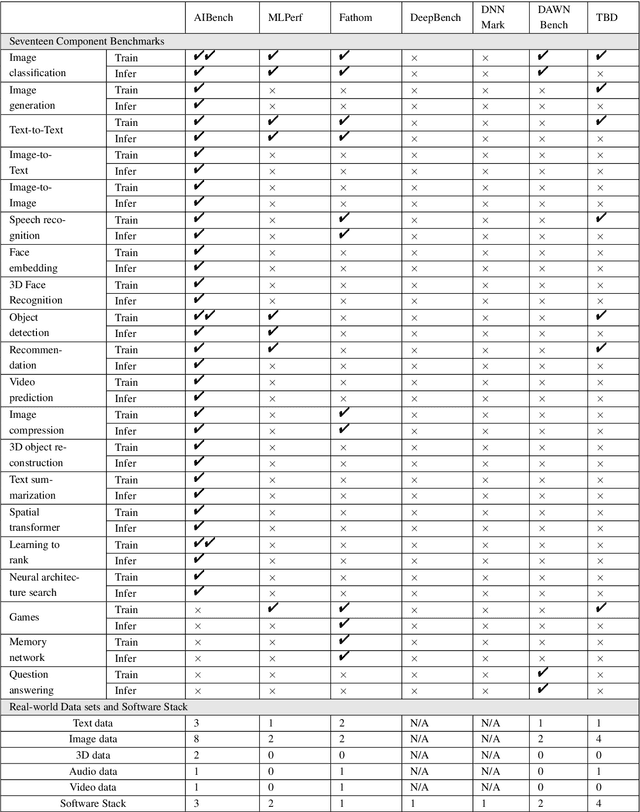
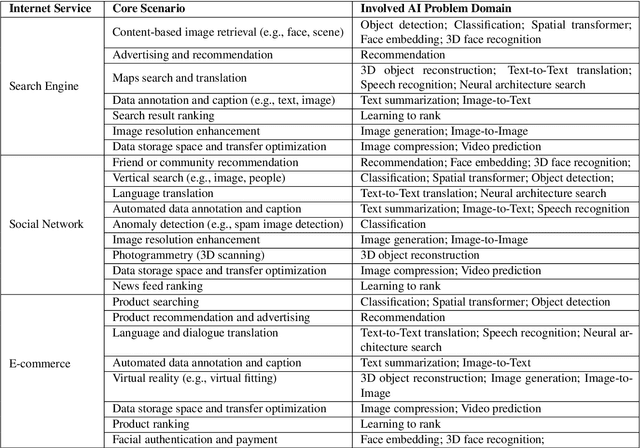
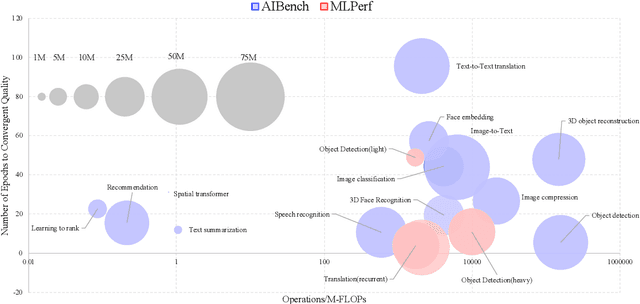
The booming successes of machine learning in different domains boost industry-scale deployments of innovative AI algorithms, systems, and architectures, and thus the importance of benchmarking grows. However, the confidential nature of the workloads, the paramount importance of the representativeness and diversity of benchmarks, and the prohibitive cost of training a state-of-the-art model mutually aggravate the AI benchmarking challenges. In this paper, we present a balanced AI benchmarking methodology for meeting the subtly different requirements of different stages in developing a new system/architecture and ranking/purchasing commercial off-the-shelf ones. Performing an exhaustive survey on the most important AI domain-Internet services with seventeen industry partners, we identify and include seventeen representative AI tasks to guarantee the representativeness and diversity of the benchmarks. Meanwhile, for reducing the benchmarking cost, we select a benchmark subset to a minimum-three tasks-according to the criteria: diversity of model complexity, computational cost, and convergence rate, repeatability, and having widely-accepted metrics or not. We contribute by far the most comprehensive AI benchmark suite-AIBench. The evaluations show AIBench outperforms MLPerf in terms of the diversity and representativeness of model complexity, computational cost, convergent rate, computation and memory access patterns, and hotspot functions. With respect to the AIBench full benchmarks, its subset shortens the benchmarking cost by 41%, while maintaining the primary workload characteristics. The specifications, source code, and performance numbers are publicly available from the web site http://www.benchcouncil.org/AIBench/index.html.
AIBench: An Agile Domain-specific Benchmarking Methodology and an AI Benchmark Suite
Feb 17, 2020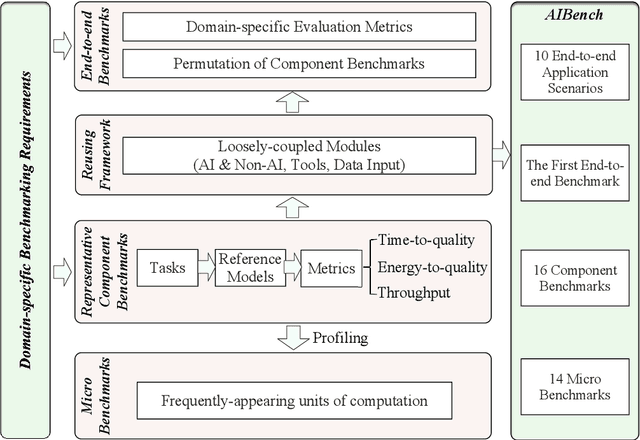
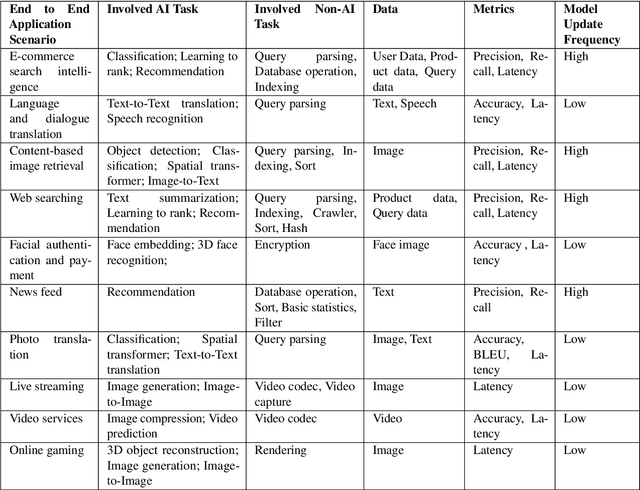

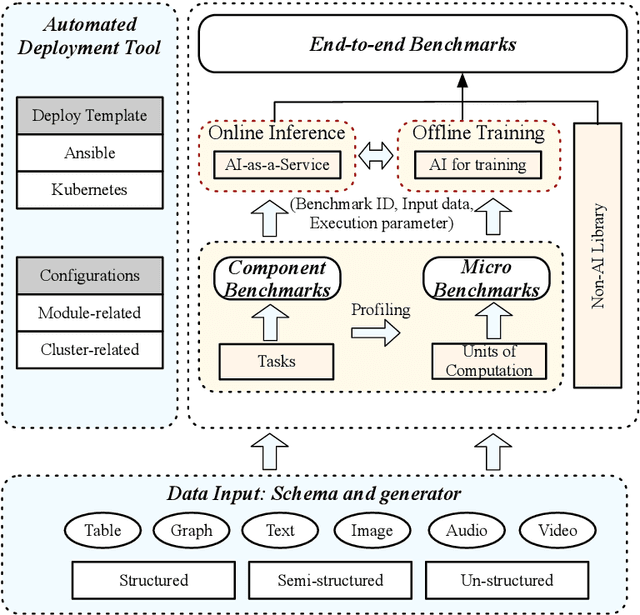
Domain-specific software and hardware co-design is encouraging as it is much easier to achieve efficiency for fewer tasks. Agile domain-specific benchmarking speeds up the process as it provides not only relevant design inputs but also relevant metrics, and tools. Unfortunately, modern workloads like Big data, AI, and Internet services dwarf the traditional one in terms of code size, deployment scale, and execution path, and hence raise serious benchmarking challenges. This paper proposes an agile domain-specific benchmarking methodology. Together with seventeen industry partners, we identify ten important end-to-end application scenarios, among which sixteen representative AI tasks are distilled as the AI component benchmarks. We propose the permutations of essential AI and non-AI component benchmarks as end-to-end benchmarks. An end-to-end benchmark is a distillation of the essential attributes of an industry-scale application. We design and implement a highly extensible, configurable, and flexible benchmark framework, on the basis of which, we propose the guideline for building end-to-end benchmarks, and present the first end-to-end Internet service AI benchmark. The preliminary evaluation shows the value of our benchmark suite---AIBench against MLPerf and TailBench for hardware and software designers, micro-architectural researchers, and code developers. The specifications, source code, testbed, and results are publicly available from the web site \url{http://www.benchcouncil.org/AIBench/index.html}.