 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as Noisy Channels: A Shannon Perspective on Model Capacity and Scaling Laws
May 22, 2026Existing scaling laws for Large Language Models (LLMs), predominantly monotonic power laws, fail to explain emerging non-monotonic phenomena such as catastrophic overtraining and quantization-induced degradation, where performance deteriorates despite increased compute. We propose the Shannon Scaling Law, a unified theoretical framework that models LLM training as information transmission over a noisy channel, grounded in the Shannon-Hartley theorem. By mapping model parameters to channel bandwidth and training tokens to signal power, our formulation explicitly captures the interaction between learning signal and intrinsic noise. This perspective reveals a fundamental Shannon capacity for LLMs: scaling model size or data without preserving a sufficient signal-to-noise ratio (SNR) inevitably amplifies noise, inducing a transition from monotonic improvement to U-shaped performance degradation. We validate our theory through experiments on Pythia and OLMo2 under perturbations, including Gaussian noise, quantization and supervised fine-tuning on math, QA and code tasks. The Shannon Scaling Law consistently outperforms classical scaling laws and recent perturbation-aware laws, achieving strong $R^2$ scores and accurately capturing loss basins missed by prior approaches. It also extrapolates: fitted on $\leq$6.9B Pythia models with $\leq$180B tokens, it predicts the unseen 12B model up to 307B tokens at pooled $R^2{=}0.847$, while monotonic baselines collapse.
A Comprehensive LLM-powered Framework for Driving Intelligence Evaluation
Mar 07, 2025


Evaluation methods for autonomous driving are crucial for algorithm optimization. However, due to the complexity of driving intelligence, there is currently no comprehensive evaluation method for the level of autonomous driving intelligence. In this paper, we propose an evaluation framework for driving behavior intelligence in complex traffic environments, aiming to fill this gap. We constructed a natural language evaluation dataset of human professional drivers and passengers through naturalistic driving experiments and post-driving behavior evaluation interviews. Based on this dataset, we developed an LLM-powered driving evaluation framework. The effectiveness of this framework was validated through simulated experiments in the CARLA urban traffic simulator and further corroborated by human assessment. Our research provides valuable insights for evaluating and designing more intelligent, human-like autonomous driving agents. The implementation details of the framework and detailed information about the dataset can be found at Github.
* 8 pages, 3 figures
Instruct Large Language Models to Generate Scientific Literature Survey Step by Step
Aug 15, 2024Abstract. Automatically generating scientific literature surveys is a valuable task that can significantly enhance research efficiency. However, the diverse and complex nature of information within a literature survey poses substantial challenges for generative models. In this paper, we design a series of prompts to systematically leverage large language models (LLMs), enabling the creation of comprehensive literature surveys through a step-by-step approach. Specifically, we design prompts to guide LLMs to sequentially generate the title, abstract, hierarchical headings, and the main content of the literature survey. We argue that this design enables the generation of the headings from a high-level perspective. During the content generation process, this design effectively harnesses relevant information while minimizing costs by restricting the length of both input and output content in LLM queries. Our implementation with Qwen-long achieved third place in the NLPCC 2024 Scientific Literature Survey Generation evaluation task, with an overall score only 0.03% lower than the second-place team. Additionally, our soft heading recall is 95.84%, the second best among the submissions. Thanks to the efficient prompt design and the low cost of the Qwen-long API, our method reduces the expense for generating each literature survey to 0.1 RMB, enhancing the practical value of our method.
Self-Supervised Pretext Tasks for Alzheimer's Disease Classification using 3D Convolutional Neural Networks on Large-Scale Synthetic Neuroimaging Dataset
Jun 20, 2024Structural magnetic resonance imaging (MRI) studies have shown that Alzheimer's Disease (AD) induces both localised and widespread neural degenerative changes throughout the brain. However, the absence of segmentation that highlights brain degenerative changes presents unique challenges for training CNN-based classifiers in a supervised fashion. In this work, we evaluated several unsupervised methods to train a feature extractor for downstream AD vs. CN classification. Using the 3D T1-weighted MRI data of cognitive normal (CN) subjects from the synthetic neuroimaging LDM100K dataset, lightweight 3D CNN-based models are trained for brain age prediction, brain image rotation classification, brain image reconstruction and a multi-head task combining all three tasks into one. Feature extractors trained on the LDM100K synthetic dataset achieved similar performance compared to the same model using real-world data. This supports the feasibility of utilising large-scale synthetic data for pretext task training. All the training and testing splits are performed on the subject-level to prevent data leakage issues. Alongside the simple preprocessing steps, the random cropping data augmentation technique shows consistent improvement across all experiments.
Mistral-C2F: Coarse to Fine Actor for Analytical and Reasoning Enhancement in RLHF and Effective-Merged LLMs
Jun 12, 2024



Despite the advances in Large Language Models (LLMs), exemplified by models like GPT-4 and Claude, smaller-scale LLMs such as Llama and Mistral often struggle with generating in-depth and coherent dialogues. This paper presents a novel two-step Coarse-to-Fine Actor model to address the inherent limitations in conversational and analytical capabilities of small-sized LLMs. Our approach begins with the Policy-based Coarse Actor, employing a technique we term "Continuous Maximization". The Coarse Actor establishes an enhanced, knowledge-rich pool adept at aligning with human preference styles in analysis and reasoning. Through the RLHF process, it employs Continuous Maximization, a strategy that dynamically and adaptively extends the output length limit, enabling the generation of more detailed and analytical content. Subsequently, the Fine Actor refines this analytical content, addressing the generation of excessively redundant information from the Coarse Actor. We introduce a "Knowledge Residue Merger" approach, refining the content from the Coarse Actor and merging it with an existing Instruction model to improve quality, correctness, and reduce redundancies. We applied our methodology to the popular Mistral model, creating Mistral-C2F, which has demonstrated exceptional performance across 11 general language tasks and the MT-Bench Dialogue task, outperforming similar-scale models and even larger models with 13B and 30B parameters. Our model has significantly improved conversational and analytical reasoning abilities.
Balancing Enhancement, Harmlessness, and General Capabilities: Enhancing Conversational LLMs with Direct RLHF
Mar 04, 2024



In recent advancements in Conversational Large Language Models (LLMs), a concerning trend has emerged, showing that many new base LLMs experience a knowledge reduction in their foundational capabilities following Supervised Fine-Tuning (SFT). This process often leads to issues such as forgetting or a decrease in the base model's abilities. Moreover, fine-tuned models struggle to align with user preferences, inadvertently increasing the generation of toxic outputs when specifically prompted. To overcome these challenges, we adopted an innovative approach by completely bypassing SFT and directly implementing Harmless Reinforcement Learning from Human Feedback (RLHF). Our method not only preserves the base model's general capabilities but also significantly enhances its conversational abilities, while notably reducing the generation of toxic outputs. Our approach holds significant implications for fields that demand a nuanced understanding and generation of responses, such as customer service. We applied this methodology to Mistral, the most popular base model, thereby creating Mistral-Plus. Our validation across 11 general tasks demonstrates that Mistral-Plus outperforms similarly sized open-source base models and their corresponding instruct versions. Importantly, the conversational abilities of Mistral-Plus were significantly improved, indicating a substantial advancement over traditional SFT models in both safety and user preference alignment.
ICE-GRT: Instruction Context Enhancement by Generative Reinforcement based Transformers
Jan 04, 2024The emergence of Large Language Models (LLMs) such as ChatGPT and LLaMA encounter limitations in domain-specific tasks, with these models often lacking depth and accuracy in specialized areas, and exhibiting a decrease in general capabilities when fine-tuned, particularly analysis ability in small sized models. To address these gaps, we introduce ICE-GRT, utilizing Reinforcement Learning from Human Feedback (RLHF) grounded in Proximal Policy Optimization (PPO), demonstrating remarkable ability in in-domain scenarios without compromising general task performance. Our exploration of ICE-GRT highlights its understanding and reasoning ability to not only generate robust answers but also to provide detailed analyses of the reasons behind the answer. This capability marks a significant progression beyond the scope of Supervised Fine-Tuning models. The success of ICE-GRT is dependent on several crucial factors, including Appropriate Data, Reward Size Scaling, KL-Control, Advantage Normalization, etc. The ICE-GRT model exhibits state-of-the-art performance in domain-specific tasks and across 12 general Language tasks against equivalent size and even larger size LLMs, highlighting the effectiveness of our approach. We provide a comprehensive analysis of the ICE-GRT, underscoring the significant advancements it brings to the field of LLM.
A Self-enhancement Approach for Domain-specific Chatbot Training via Knowledge Mining and Digest
Nov 17, 2023



Large Language Models (LLMs), despite their great power in language generation, often encounter challenges when dealing with intricate and knowledge-demanding queries in specific domains. This paper introduces a novel approach to enhance LLMs by effectively extracting the relevant knowledge from domain-specific textual sources, and the adaptive training of a chatbot with domain-specific inquiries. Our two-step approach starts from training a knowledge miner, namely LLMiner, which autonomously extracts Question-Answer pairs from relevant documents through a chain-of-thought reasoning process. Subsequently, we blend the mined QA pairs with a conversational dataset to fine-tune the LLM as a chatbot, thereby enriching its domain-specific expertise and conversational capabilities. We also developed a new evaluation benchmark which comprises four domain-specific text corpora and associated human-crafted QA pairs for testing. Our model shows remarkable performance improvement over generally aligned LLM and surpasses domain-adapted models directly fine-tuned on domain corpus. In particular, LLMiner achieves this with minimal human intervention, requiring only 600 seed instances, thereby providing a pathway towards self-improvement of LLMs through model-synthesized training data.
Balancing Specialized and General Skills in LLMs: The Impact of Modern Tuning and Data Strategy
Oct 07, 2023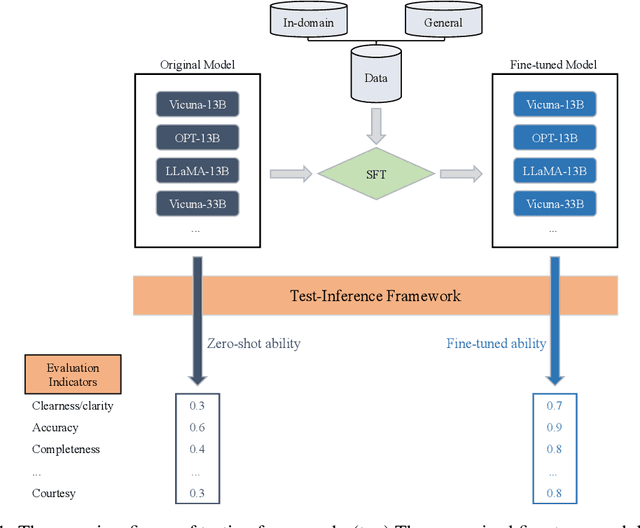
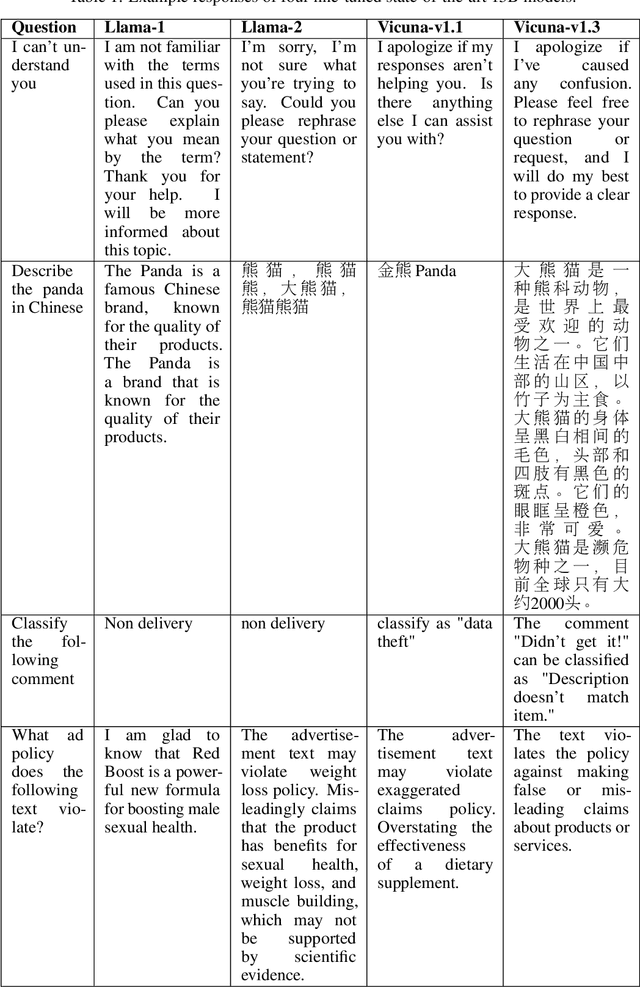
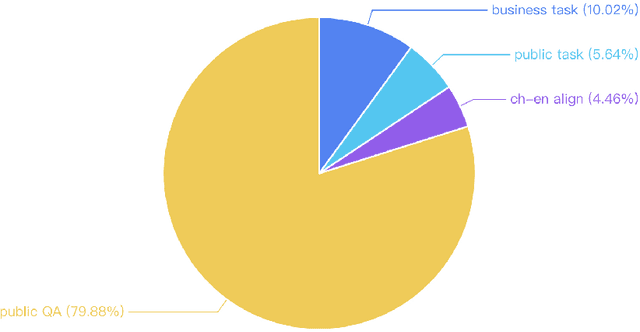
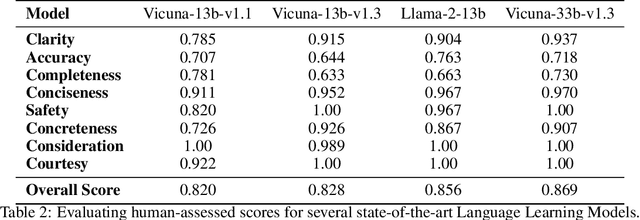
This paper introduces a multifaceted methodology for fine-tuning and evaluating large language models (LLMs) for specialized monetization tasks. The goal is to balance general language proficiency with domain-specific skills. The methodology has three main components: 1) Carefully blending in-domain and general-purpose data during fine-tuning to achieve an optimal balance between general and specialized capabilities; 2) Designing a comprehensive evaluation framework with 45 questions tailored to assess performance on functionally relevant dimensions like reliability, consistency, and business impact; 3) Analyzing how model size and continual training influence metrics to guide efficient resource allocation during fine-tuning. The paper details the design, data collection, analytical techniques, and results validating the proposed frameworks. It aims to provide businesses and researchers with actionable insights on effectively adapting LLMs for specialized contexts. We also intend to make public the comprehensive evaluation framework, which includes the 45 tailored questions and their respective scoring guidelines, to foster transparency and collaboration in adapting LLMs for specialized tasks.
Improving the Generalization Ability in Essay Coherence Evaluation through Monotonic Constraints
Jul 25, 2023Coherence is a crucial aspect of evaluating text readability and can be assessed through two primary factors when evaluating an essay in a scoring scenario. The first factor is logical coherence, characterized by the appropriate use of discourse connectives and the establishment of logical relationships between sentences. The second factor is the appropriateness of punctuation, as inappropriate punctuation can lead to confused sentence structure. To address these concerns, we propose a coherence scoring model consisting of a regression model with two feature extractors: a local coherence discriminative model and a punctuation correction model. We employ gradient-boosting regression trees as the regression model and impose monotonicity constraints on the input features. The results show that our proposed model better generalizes unseen data. The model achieved third place in track 1 of NLPCC 2023 shared task 7. Additionally, we briefly introduce our solution for the remaining tracks, which achieves second place for track 2 and first place for both track 3 and track 4.