 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruct Large Language Models to Generate Scientific Literature Survey Step by Step
Aug 15, 2024Abstract. Automatically generating scientific literature surveys is a valuable task that can significantly enhance research efficiency. However, the diverse and complex nature of information within a literature survey poses substantial challenges for generative models. In this paper, we design a series of prompts to systematically leverage large language models (LLMs), enabling the creation of comprehensive literature surveys through a step-by-step approach. Specifically, we design prompts to guide LLMs to sequentially generate the title, abstract, hierarchical headings, and the main content of the literature survey. We argue that this design enables the generation of the headings from a high-level perspective. During the content generation process, this design effectively harnesses relevant information while minimizing costs by restricting the length of both input and output content in LLM queries. Our implementation with Qwen-long achieved third place in the NLPCC 2024 Scientific Literature Survey Generation evaluation task, with an overall score only 0.03% lower than the second-place team. Additionally, our soft heading recall is 95.84%, the second best among the submissions. Thanks to the efficient prompt design and the low cost of the Qwen-long API, our method reduces the expense for generating each literature survey to 0.1 RMB, enhancing the practical value of our method.
EvEval: A Comprehensive Evaluation of Event Semantics for Large Language Models
May 24, 2023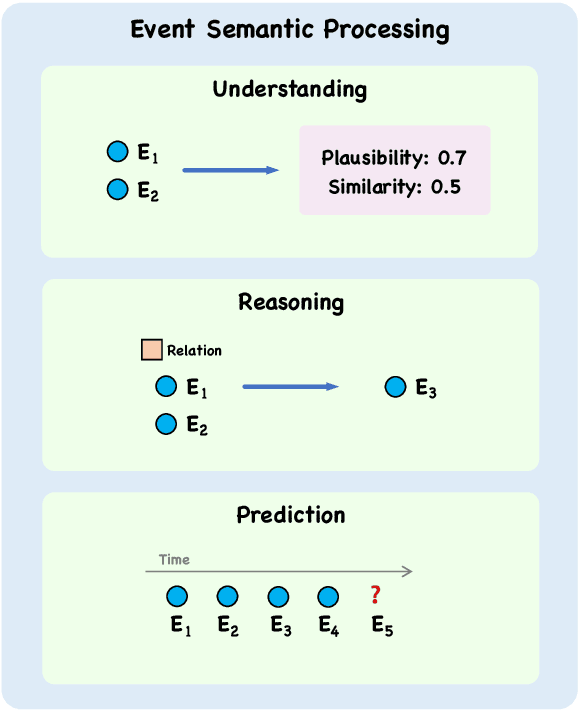
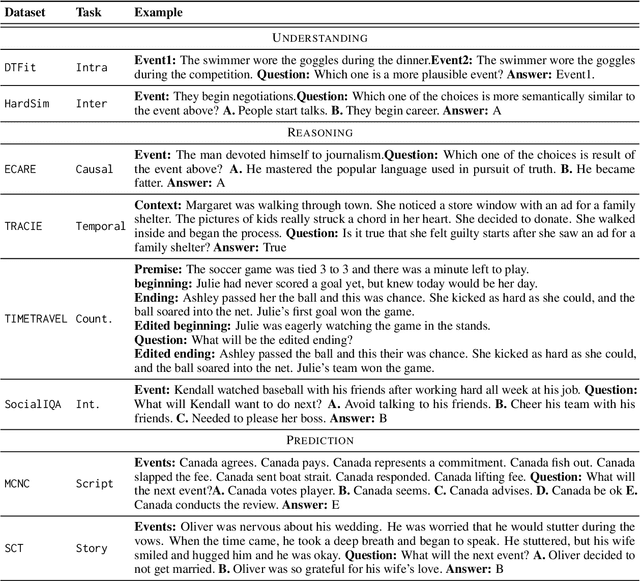
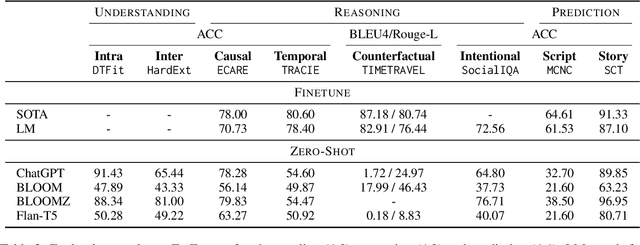
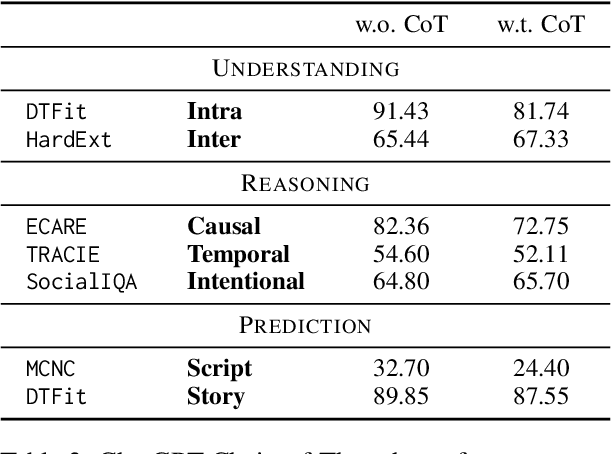
Events serve as fundamental units of occurrence within various contexts. The processing of event semantics in textual information forms the basis of numerous natural language processing (NLP) applications. Recent studies have begun leveraging large language models (LLMs) to address event semantic processing. However, the extent that LLMs can effectively tackle these challenges remains uncertain. Furthermore, the lack of a comprehensive evaluation framework for event semantic processing poses a significant challenge in evaluating these capabilities. In this paper, we propose an overarching framework for event semantic processing, encompassing understanding, reasoning, and prediction, along with their fine-grained aspects. To comprehensively evaluate the event semantic processing abilities of models, we introduce a novel benchmark called EVEVAL. We collect 8 datasets that cover all aspects of event semantic processing. Extensive experiments are conducted on EVEVAL, leading to several noteworthy findings based on the obtained results.
Text Classification with Novelty Detection
Sep 23, 2020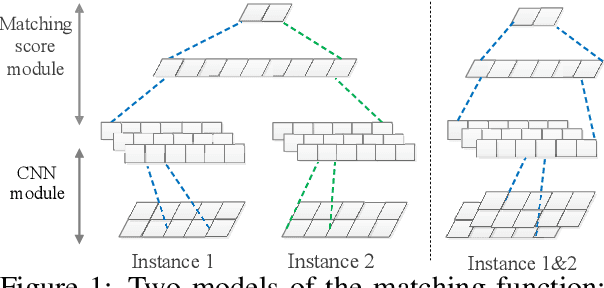

This paper studies the problem of detecting novel or unexpected instances in text classification. In traditional text classification, the classes appeared in testing must have been seen in training. However, in many applications, this is not the case because in testing, we may see unexpected instances that are not from any of the training classes. In this paper, we propose a significantly more effective approach that converts the original problem to a pair-wise matching problem and then outputs how probable two instances belong to the same class. Under this approach, we present two models. The more effective model uses two embedding matrices of a pair of instances as two channels of a CNN. The output probabilities from such pairs are used to judge whether a test instance is from a seen class or is novel/unexpected. Experimental results show that the proposed method substantially outperforms the state-of-the-art baselines.
Transformation of Dense and Sparse Text Representations
Nov 07, 2019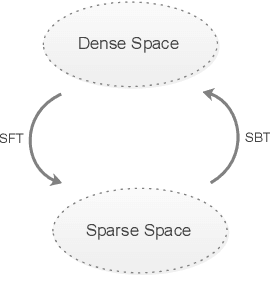
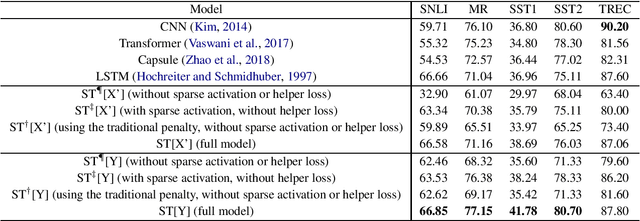
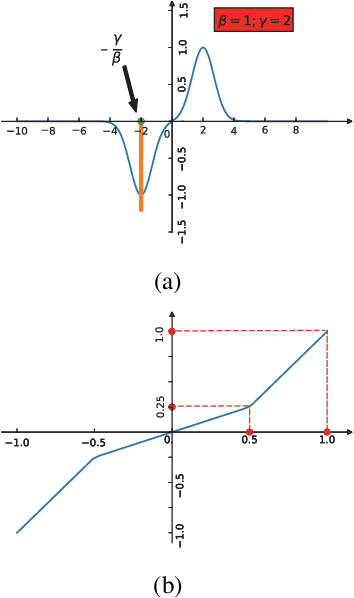
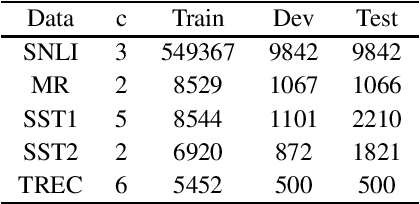
Sparsity is regarded as a desirable property of representations, especially in terms of explanation. However, its usage has been limited due to the gap with dense representations. Most NLP research progresses in recent years are based on dense representations. Thus the desirable property of sparsity cannot be leveraged. Inspired by Fourier Transformation, in this paper, we propose a novel Semantic Transformation method to bridge the dense and sparse spaces, which can facilitate the NLP research to shift from dense space to sparse space or to jointly use both spaces. The key idea of the proposed approach is to use a Forward Transformation to transform dense representations to sparse representations. Then some useful operations in the sparse space can be performed over the sparse representations, and the sparse representations can be used directly to perform downstream tasks such as text classification and natural language inference. Then, a Backward Transformation can also be carried out to transform those processed sparse representations to dense representations. Experiments using classification tasks and natural language inference task show that the proposed Semantic Transformation is effective.
Query-bag Matching with Mutual Coverage for Information-seeking Conversations in E-commerce
Nov 07, 2019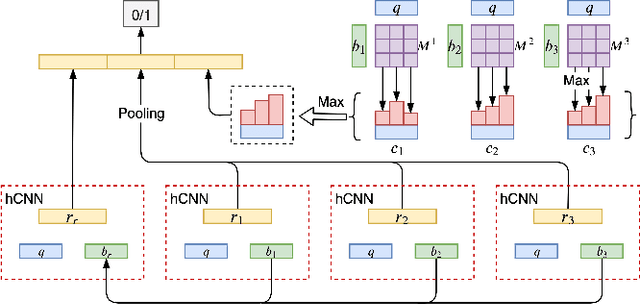
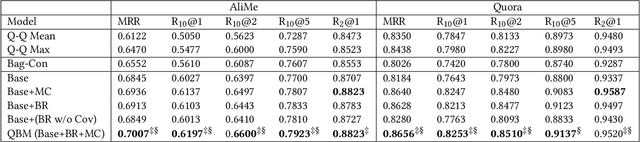
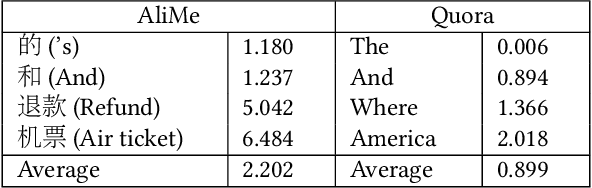
Information-seeking conversation system aims at satisfying the information needs of users through conversations. Text matching between a user query and a pre-collected question is an important part of the information-seeking conversation in E-commerce. In the practical scenario, a sort of questions always correspond to a same answer. Naturally, these questions can form a bag. Learning the matching between user query and bag directly may improve the conversation performance, denoted as query-bag matching. Inspired by such opinion, we propose a query-bag matching model which mainly utilizes the mutual coverage between query and bag and measures the degree of the content in the query mentioned by the bag, and vice verse. In addition, the learned bag representation in word level helps find the main points of a bag in a fine grade and promotes the query-bag matching performance. Experiments on two datasets show the effectiveness of our model.
FlexNER: A Flexible LSTM-CNN Stack Framework for Named Entity Recognition
Aug 14, 2019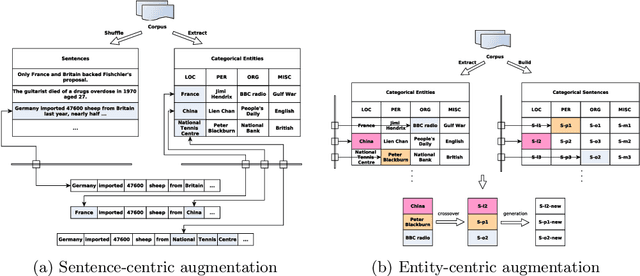
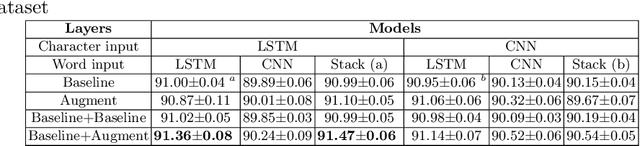
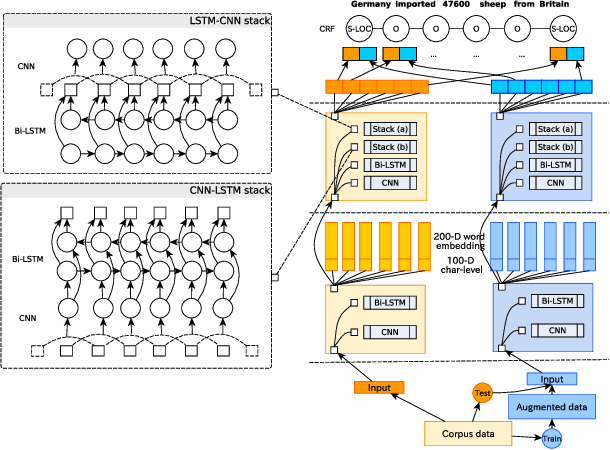

Named entity recognition (NER) is a foundational technology for information extraction. This paper presents a flexible NER framework compatible with different languages and domains. Inspired by the idea of distant supervision (DS), this paper enhances the representation by increasing the entity-context diversity without relying on external resources. We choose different layer stacks and sub-network combinations to construct the bilateral networks. This strategy can generally improve model performance on different datasets. We conduct experiments on five languages, such as English, German, Spanish, Dutch and Chinese, and biomedical fields, such as identifying the chemicals and gene/protein terms from scientific works. Experimental results demonstrate the good performance of this framework.
GSN: A Graph-Structured Network for Multi-Party Dialogues
May 31, 2019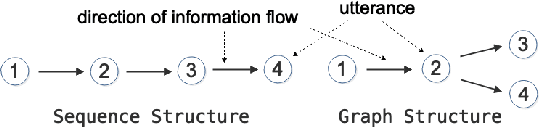

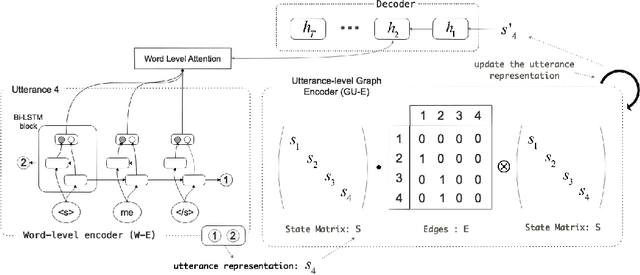
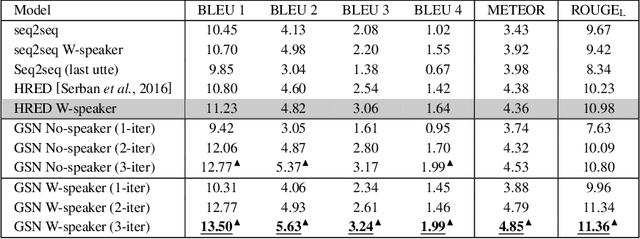
Existing neural models for dialogue response generation assume that utterances are sequentially organized. However, many real-world dialogues involve multiple interlocutors (i.e., multi-party dialogues), where the assumption does not hold as utterances from different interlocutors can occur "in parallel." This paper generalizes existing sequence-based models to a Graph-Structured neural Network (GSN) for dialogue modeling. The core of GSN is a graph-based encoder that can model the information flow along the graph-structured dialogues (two-party sequential dialogues are a special case). Experimental results show that GSN significantly outperforms existing sequence-based models.
Neural System Combination for Machine Translation
Apr 21, 2017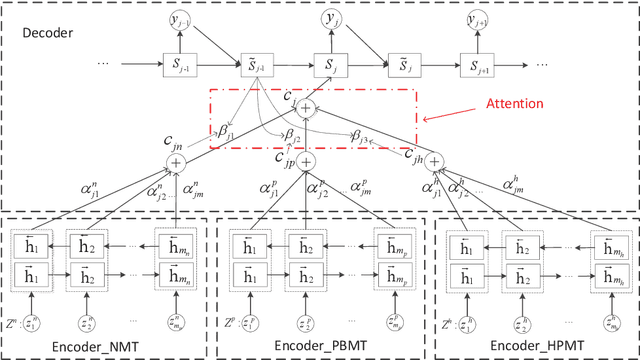
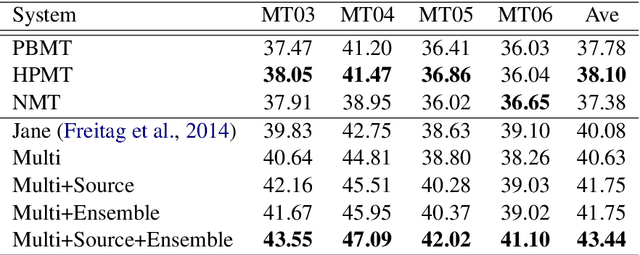
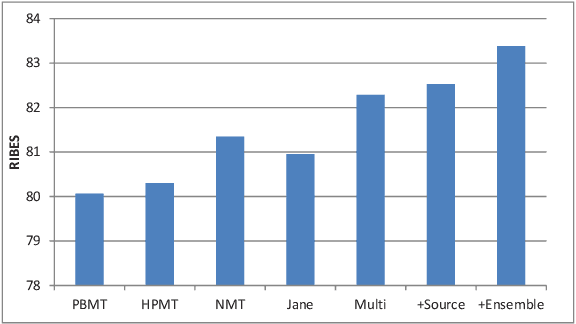
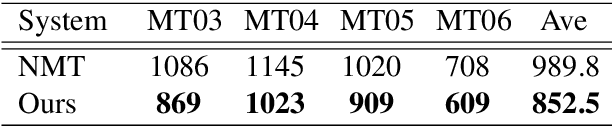
Neural machine translation (NMT) becomes a new approach to machine translation and generates much more fluent results compared to statistical machine translation (SMT). However, SMT is usually better than NMT in translation adequacy. It is therefore a promising direction to combine the advantages of both NMT and SMT. In this paper, we propose a neural system combination framework leveraging multi-source NMT, which takes as input the outputs of NMT and SMT systems and produces the final translation. Extensive experiments on the Chinese-to-English translation task show that our model archives significant improvement by 5.3 BLEU points over the best single system output and 3.4 BLEU points over the state-of-the-art traditional system combination methods.