 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitectural Foundations for the Large Language Model Infrastructures
Aug 21, 2024The development of a large language model (LLM) infrastructure is a pivotal undertaking in artificial intelligence. This paper explores the intricate landscape of LLM infrastructure, software, and data management. By analyzing these core components, we emphasize the pivotal considerations and safeguards crucial for successful LLM development. This work presents a concise synthesis of the challenges and strategies inherent in constructing a robust and effective LLM infrastructure, offering valuable insights for researchers and practitioners alike.
Challenges and Responses in the Practice of Large Language Models
Aug 21, 2024This paper carefully summarizes extensive and profound questions from all walks of life, focusing on the current high-profile AI field, covering multiple dimensions such as industry trends, academic research, technological innovation and business applications. This paper meticulously curates questions that are both thought-provoking and practically relevant, providing nuanced and insightful answers to each. To facilitate readers' understanding and reference, this paper specifically classifies and organizes these questions systematically and meticulously from the five core dimensions of computing power infrastructure, software architecture, data resources, application scenarios, and brain science. This work aims to provide readers with a comprehensive, in-depth and cutting-edge AI knowledge framework to help people from all walks of life grasp the pulse of AI development, stimulate innovative thinking, and promote industrial progress.
Node Classification via Semantic-Structural Attention-Enhanced Graph Convolutional Networks
Mar 24, 2024Graph data, also known as complex network data, is omnipresent across various domains and applications. Prior graph neural network models primarily focused on extracting task-specific structural features through supervised learning objectives, but they fell short in capturing the inherent semantic and structural features of the entire graph. In this paper, we introduce the semantic-structural attention-enhanced graph convolutional network (SSA-GCN), which not only models the graph structure but also extracts generalized unsupervised features to enhance vertex classification performance. The SSA-GCN's key contributions lie in three aspects: firstly, it derives semantic information through unsupervised feature extraction from a knowledge graph perspective; secondly, it obtains structural information through unsupervised feature extraction from a complex network perspective; and finally, it integrates these features through a cross-attention mechanism. By leveraging these features, we augment the graph convolutional network, thereby enhancing the model's generalization capabilities. Our experiments on the Cora and CiteSeer datasets demonstrate the performance improvements achieved by our proposed method. Furthermore, our approach also exhibits excellent accuracy under privacy settings, making it a robust and effective solution for graph data analysis.
MetaAID 2.5: A Secure Framework for Developing Metaverse Applications via Large Language Models
Dec 22, 2023Large language models (LLMs) are increasingly being used in Metaverse environments to generate dynamic and realistic content and to control the behavior of non-player characters (NPCs). However, the cybersecurity concerns associated with LLMs have become increasingly prominent. Previous research has primarily focused on patching system vulnerabilities to enhance cybersecurity, but these approaches are not well-suited to the Metaverse, where the virtual space is more complex, LLMs are vulnerable, and ethical user interaction is critical. Moreover, the scope of cybersecurity in the Metaverse is expected to expand significantly. This paper proposes a method for enhancing cybersecurity through the simulation of user interaction with LLMs. Our goal is to educate users and strengthen their defense capabilities through exposure to a comprehensive simulation system. This system includes extensive Metaverse cybersecurity Q&A and attack simulation scenarios. By engaging with these, users will improve their ability to recognize and withstand risks. Additionally, to address the ethical implications of user input, we propose using LLMs as evaluators to assess user content across five dimensions. We further adapt the models through vocabulary expansion training to better understand personalized inputs and emoticons. We conduct experiments on multiple LLMs and find that our approach is effective.
Climate Change from Large Language Models
Dec 20, 2023Climate change presents significant challenges to the global community, and it is imperative to raise widespread awareness of the climate crisis and educate users about low-carbon living. Artificial intelligence, particularly large language models (LLMs), have emerged as powerful tools in mitigating the climate crisis, leveraging their extensive knowledge, broad user base, and natural language interaction capabilities. However, despite the growing body of research on climate change, there is a lack of comprehensive assessments of climate crisis knowledge within LLMs. This paper aims to resolve this gap by proposing an automatic evaluation framework. We employ a hybrid approach to data acquisition that combines data synthesis and manual collection to compile a diverse set of questions related to the climate crisis. These questions cover various aspects of climate change, including its causes, impacts, mitigation strategies, and adaptation measures. We then evaluate the model knowledge through prompt engineering based on the collected questions and generated answers. We propose a set of comprehensive metrics to evaluate the climate crisis knowledge, incorporating indicators from 10 different perspectives. Experimental results show that our method is effective in evaluating the knowledge of LLMs regarding the climate crisis. We evaluate several state-of-the-art LLMs and find that their knowledge falls short in terms of timeliness.
Reranking Passages with Coarse-to-Fine Neural Retriever using List-Context Information
Aug 23, 2023Passage reranking is a crucial task in many applications, particularly when dealing with large-scale documents. Traditional neural architectures are limited in retrieving the best passage for a question because they usually match the question to each passage separately, seldom considering contextual information in other passages that can provide comparison and reference information. This paper presents a list-context attention mechanism to augment the passage representation by incorporating the list-context information from other candidates. The proposed coarse-to-fine (C2F) neural retriever addresses the out-of-memory limitation of the passage attention mechanism by dividing the list-context modeling process into two sub-processes, allowing for efficient encoding of context information from a large number of candidate answers. This method can be generally used to encode context information from any number of candidate answers in one pass. Different from most multi-stage information retrieval architectures, this model integrates the coarse and fine rankers into the joint optimization process, allowing for feedback between the two layers to update the model simultaneously. Experiments demonstrate the effectiveness of the proposed approach.
Extracting Relational Triples Based on Graph Recursive Neural Network via Dynamic Feedback Forest Algorithm
Aug 22, 2023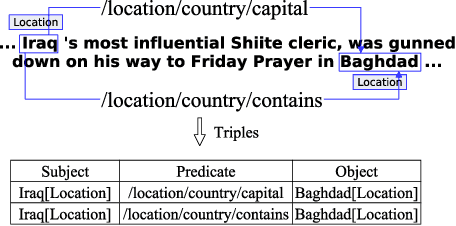
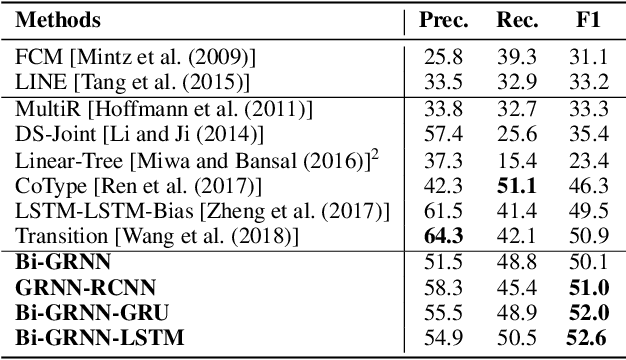
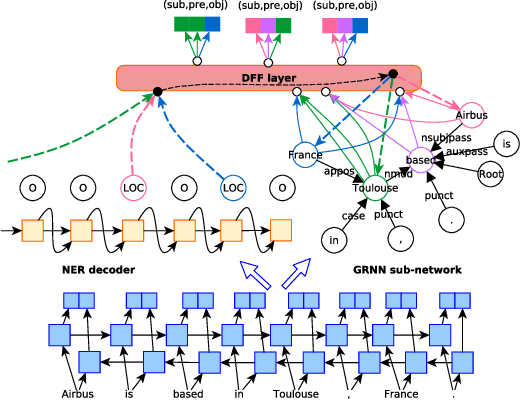
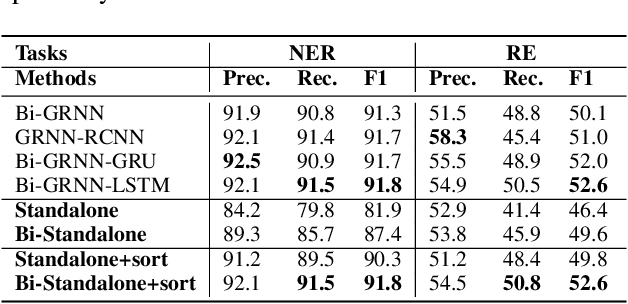
Extracting relational triples (subject, predicate, object) from text enables the transformation of unstructured text data into structured knowledge. The named entity recognition (NER) and the relation extraction (RE) are two foundational subtasks in this knowledge generation pipeline. The integration of subtasks poses a considerable challenge due to their disparate nature. This paper presents a novel approach that converts the triple extraction task into a graph labeling problem, capitalizing on the structural information of dependency parsing and graph recursive neural networks (GRNNs). To integrate subtasks, this paper proposes a dynamic feedback forest algorithm that connects the representations of subtasks by inference operations during model training. Experimental results demonstrate the effectiveness of the proposed method.
FQP 2.0: Industry Trend Analysis via Hierarchical Financial Data
Mar 05, 2023Analyzing trends across industries is critical to maintaining a healthy and stable economy. Previous research has mainly analyzed official statistics, which are more accurate but not necessarily real-time. In this paper, we propose a method for analyzing industry trends using stock market data. The difficulty of this task is that the raw data is relatively noisy, which affects the accuracy of statistical analysis. In addition, textual data for industry analysis needs to be better understood through language models. For this reason, we introduce the method of industry trend analysis from two perspectives of explicit analysis and implicit analysis. For the explicit analysis, we introduce a hierarchical data (industry and listed company) analysis method to reduce the impact of noise. For implicit analysis, we further pre-train GPT-2 to analyze industry trends with current affairs background as input, making full use of the knowledge learned in the pre-training corpus. We conduct experiments based on the proposed method and achieve good industry trend analysis results.
MetaAID 2.0: An Extensible Framework for Developing Metaverse Applications via Human-controllable Pre-trained Models
Feb 25, 2023Pre-trained models (PM) have achieved promising results in content generation. However, the space for human creativity and imagination is endless, and it is still unclear whether the existing models can meet the needs. Model-generated content faces uncontrollable responsibility and potential unethical problems. This paper presents the MetaAID 2.0 framework, dedicated to human-controllable PM information flow. Through the PM information flow, humans can autonomously control their creativity. Through the Universal Resource Identifier extension (URI-extension), the responsibility of the model outputs can be controlled. Our framework includes modules for handling multimodal data and supporting transformation and generation. The URI-extension consists of URI, detailed description, and URI embeddings, and supports fuzzy retrieval of model outputs. Based on this framework, we conduct experiments on PM information flow and URI embeddings, and the results demonstrate the good performance of our system.
Financial data analysis application via multi-strategy text processing
Apr 25, 2022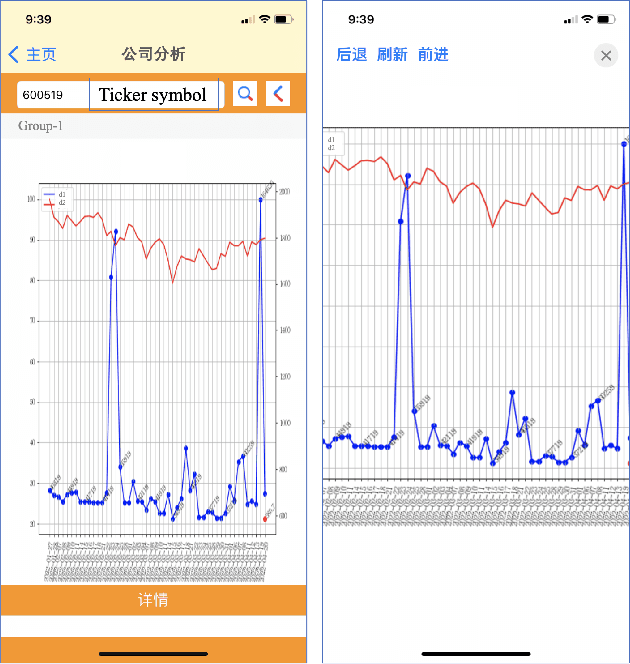
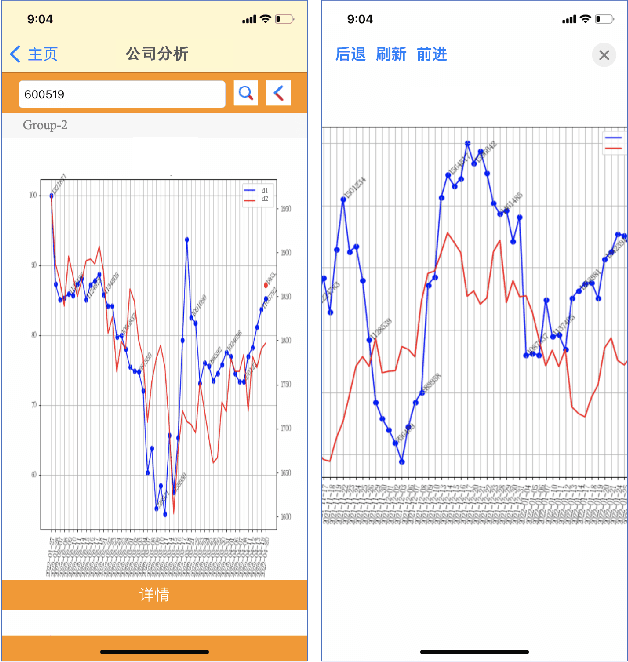
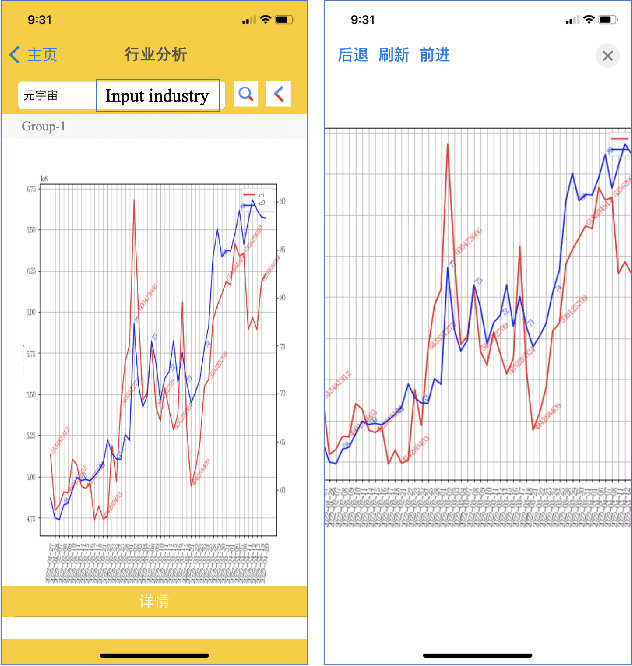
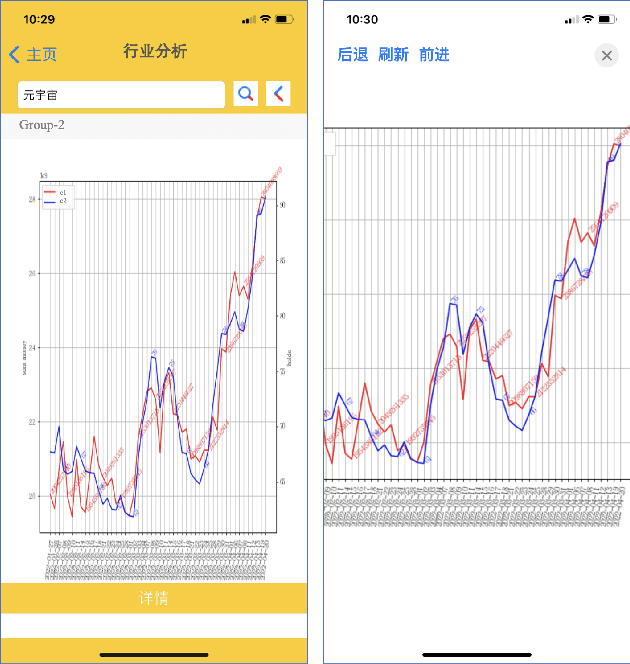
Maintaining financial system stability is critical to economic development, and early identification of risks and opportunities is essential. The financial industry contains a wide variety of data, such as financial statements, customer information, stock trading data, news, etc. Massive heterogeneous data calls for intelligent algorithms for machines to process and understand. This paper mainly focuses on the stock trading data and news about China A-share companies. We present a financial data analysis application, Financial Quotient Porter, designed to combine textual and numerical data by using a multi-strategy data mining approach. Additionally, we present our efforts and plans in deep learning financial text processing application scenarios using natural language processing (NLP) and knowledge graph (KG) technologies. Based on KG technology, risks and opportunities can be identified from heterogeneous data. NLP technology can be used to extract entities, relations, and events from unstructured text, and analyze market sentiment. Experimental results show market sentiments towards a company and an industry, as well as news-level associations between companies.