 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCypherBench: Towards Precise Retrieval over Full-scale Modern Knowledge Graphs in the LLM Era
Dec 24, 2024Retrieval from graph data is crucial for augmenting large language models (LLM) with both open-domain knowledge and private enterprise data, and it is also a key component in the recent GraphRAG system (edge et al., 2024). Despite decades of research on knowledge graphs and knowledge base question answering, leading LLM frameworks (e.g. Langchain and LlamaIndex) have only minimal support for retrieval from modern encyclopedic knowledge graphs like Wikidata. In this paper, we analyze the root cause and suggest that modern RDF knowledge graphs (e.g. Wikidata, Freebase) are less efficient for LLMs due to overly large schemas that far exceed the typical LLM context window, use of resource identifiers, overlapping relation types and lack of normalization. As a solution, we propose property graph views on top of the underlying RDF graph that can be efficiently queried by LLMs using Cypher. We instantiated this idea on Wikidata and introduced CypherBench, the first benchmark with 11 large-scale, multi-domain property graphs with 7.8 million entities and over 10,000 questions. To achieve this, we tackled several key challenges, including developing an RDF-to-property graph conversion engine, creating a systematic pipeline for text-to-Cypher task generation, and designing new evaluation metrics.
A Blueprint Architecture of Compound AI Systems for Enterprise
Jun 02, 2024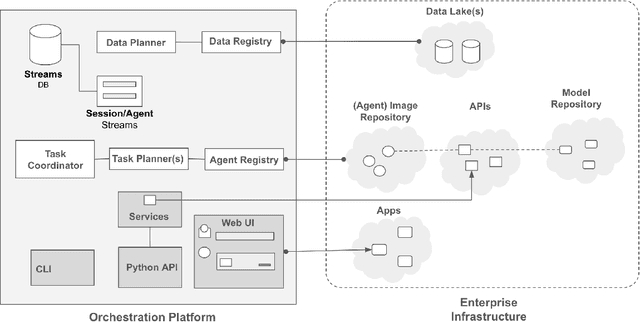
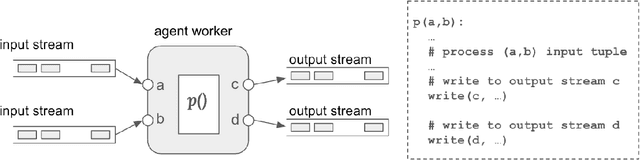
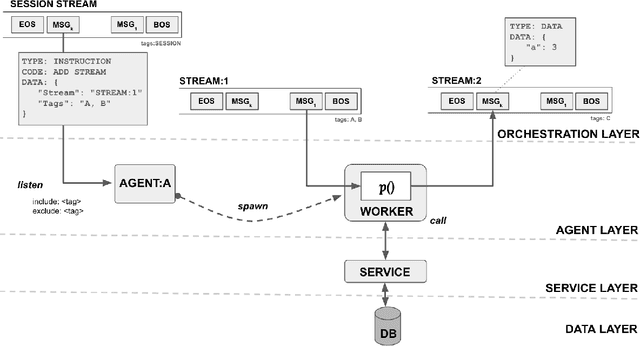
Large Language Models (LLMs) have showcased remarkable capabilities surpassing conventional NLP challenges, creating opportunities for use in production use cases. Towards this goal, there is a notable shift to building compound AI systems, wherein LLMs are integrated into an expansive software infrastructure with many components like models, retrievers, databases and tools. In this paper, we introduce a blueprint architecture for compound AI systems to operate in enterprise settings cost-effectively and feasibly. Our proposed architecture aims for seamless integration with existing compute and data infrastructure, with ``stream'' serving as the key orchestration concept to coordinate data and instructions among agents and other components. Task and data planners, respectively, break down, map, and optimize tasks and data to available agents and data sources defined in respective registries, given production constraints such as accuracy and latency.
CMDBench: A Benchmark for Coarse-to-fine Multimodal Data Discovery in Compound AI Systems
Jun 02, 2024Compound AI systems (CASs) that employ LLMs as agents to accomplish knowledge-intensive tasks via interactions with tools and data retrievers have garnered significant interest within database and AI communities. While these systems have the potential to supplement typical analysis workflows of data analysts in enterprise data platforms, unfortunately, CASs are subject to the same data discovery challenges that analysts have encountered over the years -- silos of multimodal data sources, created across teams and departments within an organization, make it difficult to identify appropriate data sources for accomplishing the task at hand. Existing data discovery benchmarks do not model such multimodality and multiplicity of data sources. Moreover, benchmarks of CASs prioritize only evaluating end-to-end task performance. To catalyze research on evaluating the data discovery performance of multimodal data retrievers in CASs within a real-world setting, we propose CMDBench, a benchmark modeling the complexity of enterprise data platforms. We adapt existing datasets and benchmarks in open-domain -- from question answering and complex reasoning tasks to natural language querying over structured data -- to evaluate coarse- and fine-grained data discovery and task execution performance. Our experiments reveal the impact of data retriever design on downstream task performance -- a 46% drop in task accuracy on average -- across various modalities, data sources, and task difficulty. The results indicate the need to develop optimization strategies to identify appropriate LLM agents and retrievers for efficient execution of CASs over enterprise data.
Calibrated Seq2seq Models for Efficient and Generalizable Ultra-fine Entity Typing
Nov 01, 2023



Ultra-fine entity typing plays a crucial role in information extraction by predicting fine-grained semantic types for entity mentions in text. However, this task poses significant challenges due to the massive number of entity types in the output space. The current state-of-the-art approaches, based on standard multi-label classifiers or cross-encoder models, suffer from poor generalization performance or inefficient inference. In this paper, we present CASENT, a seq2seq model designed for ultra-fine entity typing that predicts ultra-fine types with calibrated confidence scores. Our model takes an entity mention as input and employs constrained beam search to generate multiple types autoregressively. The raw sequence probabilities associated with the predicted types are then transformed into confidence scores using a novel calibration method. We conduct extensive experiments on the UFET dataset which contains over 10k types. Our method outperforms the previous state-of-the-art in terms of F1 score and calibration error, while achieving an inference speedup of over 50 times. Additionally, we demonstrate the generalization capabilities of our model by evaluating it in zero-shot and few-shot settings on five specialized domain entity typing datasets that are unseen during training. Remarkably, our model outperforms large language models with 10 times more parameters in the zero-shot setting, and when fine-tuned on 50 examples, it significantly outperforms ChatGPT on all datasets. Our code, models and demo are available at https://github.com/yanlinf/CASENT.
EvEval: A Comprehensive Evaluation of Event Semantics for Large Language Models
May 24, 2023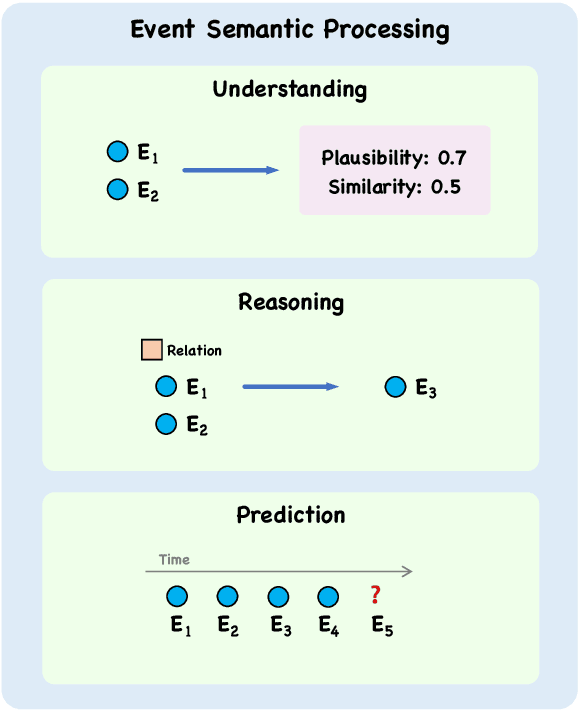
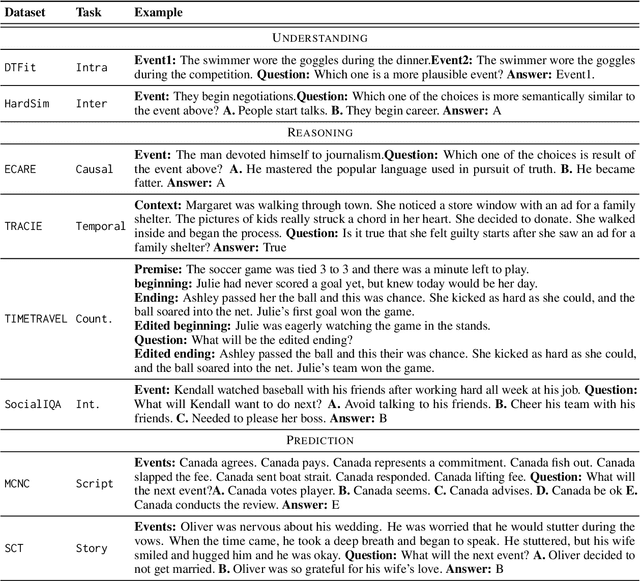
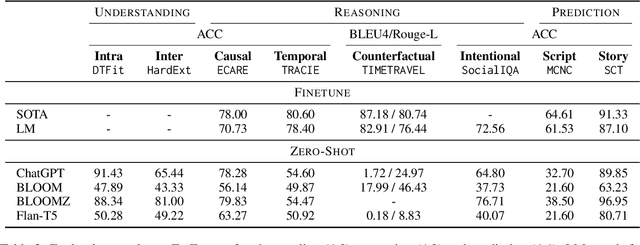
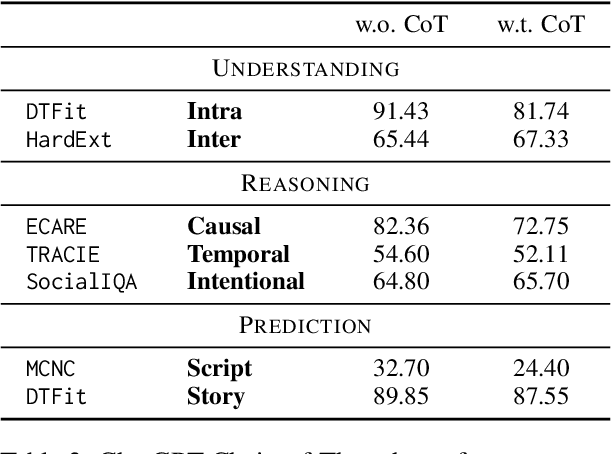
Events serve as fundamental units of occurrence within various contexts. The processing of event semantics in textual information forms the basis of numerous natural language processing (NLP) applications. Recent studies have begun leveraging large language models (LLMs) to address event semantic processing. However, the extent that LLMs can effectively tackle these challenges remains uncertain. Furthermore, the lack of a comprehensive evaluation framework for event semantic processing poses a significant challenge in evaluating these capabilities. In this paper, we propose an overarching framework for event semantic processing, encompassing understanding, reasoning, and prediction, along with their fine-grained aspects. To comprehensively evaluate the event semantic processing abilities of models, we introduce a novel benchmark called EVEVAL. We collect 8 datasets that cover all aspects of event semantic processing. Extensive experiments are conducted on EVEVAL, leading to several noteworthy findings based on the obtained results.
Scalable Multi-Hop Relational Reasoning for Knowledge-Aware Question Answering
May 01, 2020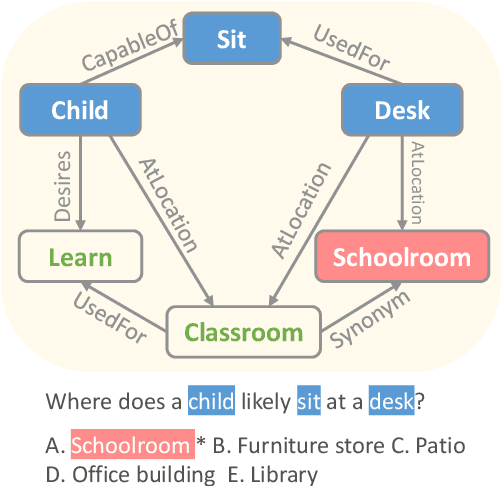

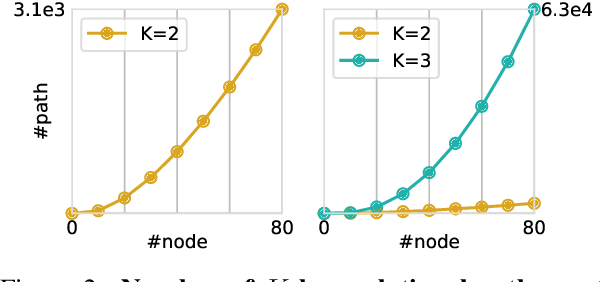

While fine-tuning pre-trained language models (PTLMs) has yielded strong results on a range of question answering (QA) benchmarks, these methods still suffer in cases when external knowledge are needed to infer the right answer. Existing work on augmenting QA models with external knowledge (e.g., knowledge graphs) either struggle to model multi-hop relations efficiently, or lack transparency into the model's prediction rationale. In this paper, we propose a novel knowledge-aware approach that equips PTLMs with a multi-hop relational reasoning module, named multi-hop graph relation networks (MHGRN). It performs multi-hop, multi-relational reasoning over subgraphs extracted from external knowledge graphs. The proposed reasoning module unifies path-based reasoning methods and graph neural networks to achieve better interpretability and scalability. We also empirically show its effectiveness and scalability on CommonsenseQA and OpenbookQA datasets, and interpret its behaviors with case studies. In particular, MHGRN achieves the state-of-the-art performance (76.5\% accuracy) on the CommonsenseQA official test set.