 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgramming by Examples Meets Historical Linguistics: A Large Language Model Based Approach to Sound Law Induction
Jan 27, 2025



Historical linguists have long written "programs" that convert reconstructed words in an ancestor language into their attested descendants via ordered string rewrite functions (called sound laws) However, writing these programs is time-consuming, motivating the development of automated Sound Law Induction (SLI) which we formulate as Programming by Examples (PBE) with Large Language Models (LLMs) in this paper. While LLMs have been effective for code generation, recent work has shown that PBE is challenging but improvable by fine-tuning, especially with training data drawn from the same distribution as evaluation data. In this paper, we create a conceptual framework of what constitutes a "similar distribution" for SLI and propose four kinds of synthetic data generation methods with varying amounts of inductive bias to investigate what leads to the best performance. Based on the results we create a SOTA open-source model for SLI as PBE (+6% pass rate with a third of the parameters of the second-best LLM) and also highlight exciting future directions for PBE research.
Calibrated Seq2seq Models for Efficient and Generalizable Ultra-fine Entity Typing
Nov 01, 2023



Ultra-fine entity typing plays a crucial role in information extraction by predicting fine-grained semantic types for entity mentions in text. However, this task poses significant challenges due to the massive number of entity types in the output space. The current state-of-the-art approaches, based on standard multi-label classifiers or cross-encoder models, suffer from poor generalization performance or inefficient inference. In this paper, we present CASENT, a seq2seq model designed for ultra-fine entity typing that predicts ultra-fine types with calibrated confidence scores. Our model takes an entity mention as input and employs constrained beam search to generate multiple types autoregressively. The raw sequence probabilities associated with the predicted types are then transformed into confidence scores using a novel calibration method. We conduct extensive experiments on the UFET dataset which contains over 10k types. Our method outperforms the previous state-of-the-art in terms of F1 score and calibration error, while achieving an inference speedup of over 50 times. Additionally, we demonstrate the generalization capabilities of our model by evaluating it in zero-shot and few-shot settings on five specialized domain entity typing datasets that are unseen during training. Remarkably, our model outperforms large language models with 10 times more parameters in the zero-shot setting, and when fine-tuned on 50 examples, it significantly outperforms ChatGPT on all datasets. Our code, models and demo are available at https://github.com/yanlinf/CASENT.
ASR2K: Speech Recognition for Around 2000 Languages without Audio
Sep 06, 2022
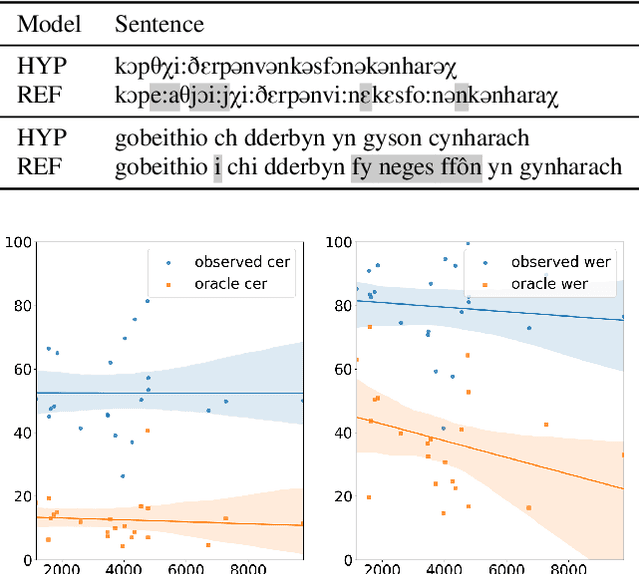
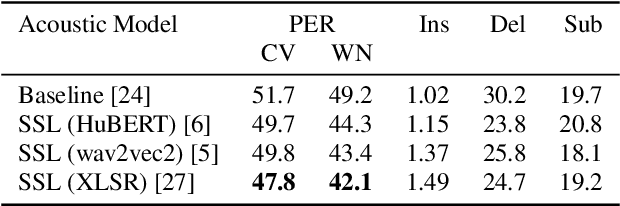
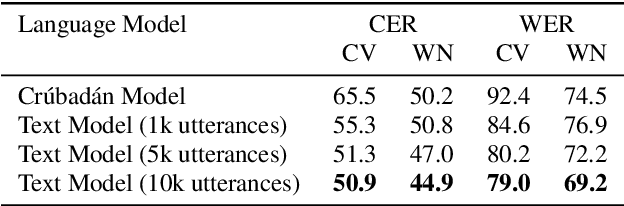
Most recent speech recognition models rely on large supervised datasets, which are unavailable for many low-resource languages. In this work, we present a speech recognition pipeline that does not require any audio for the target language. The only assumption is that we have access to raw text datasets or a set of n-gram statistics. Our speech pipeline consists of three components: acoustic, pronunciation, and language models. Unlike the standard pipeline, our acoustic and pronunciation models use multilingual models without any supervision. The language model is built using n-gram statistics or the raw text dataset. We build speech recognition for 1909 languages by combining it with Crubadan: a large endangered languages n-gram database. Furthermore, we test our approach on 129 languages across two datasets: Common Voice and CMU Wilderness dataset. We achieve 50% CER and 74% WER on the Wilderness dataset with Crubadan statistics only and improve them to 45% CER and 69% WER when using 10000 raw text utterances.
AUTOLEX: An Automatic Framework for Linguistic Exploration
Mar 25, 2022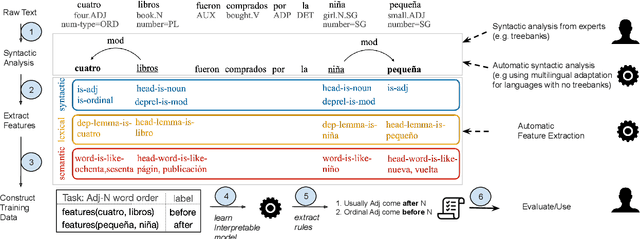
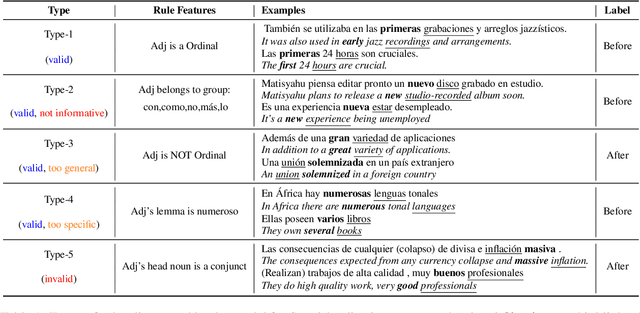
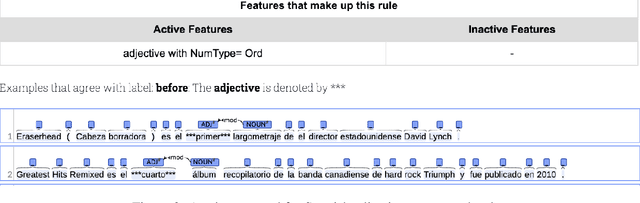
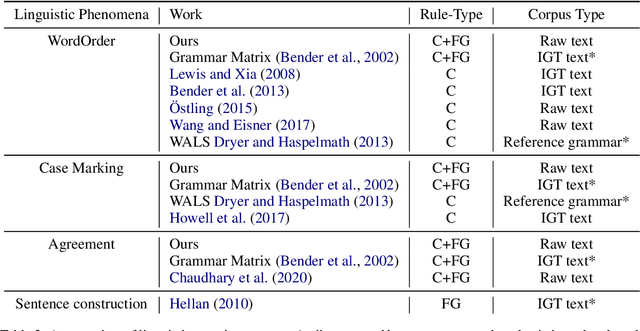
Each language has its own complex systems of word, phrase, and sentence construction, the guiding principles of which are often summarized in grammar descriptions for the consumption of linguists or language learners. However, manual creation of such descriptions is a fraught process, as creating descriptions which describe the language in "its own terms" without bias or error requires both a deep understanding of the language at hand and linguistics as a whole. We propose an automatic framework AutoLEX that aims to ease linguists' discovery and extraction of concise descriptions of linguistic phenomena. Specifically, we apply this framework to extract descriptions for three phenomena: morphological agreement, case marking, and word order, across several languages. We evaluate the descriptions with the help of language experts and propose a method for automated evaluation when human evaluation is infeasible.