 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERLIN: A Testbed for Multilingual Multimodal Entity Recognition and Linking
Oct 16, 2025This paper introduces MERLIN, a novel testbed system for the task of Multilingual Multimodal Entity Linking. The created dataset includes BBC news article titles, paired with corresponding images, in five languages: Hindi, Japanese, Indonesian, Vietnamese, and Tamil, featuring over 7,000 named entity mentions linked to 2,500 unique Wikidata entities. We also include several benchmarks using multilingual and multimodal entity linking methods exploring different language models like LLaMa-2 and Aya-23. Our findings indicate that incorporating visual data improves the accuracy of entity linking, especially for entities where the textual context is ambiguous or insufficient, and particularly for models that do not have strong multilingual abilities. For the work, the dataset, methods are available here at https://github.com/rsathya4802/merlin
CMULAB: An Open-Source Framework for Training and Deployment of Natural Language Processing Models
Apr 03, 2024Effectively using Natural Language Processing (NLP) tools in under-resourced languages requires a thorough understanding of the language itself, familiarity with the latest models and training methodologies, and technical expertise to deploy these models. This could present a significant obstacle for language community members and linguists to use NLP tools. This paper introduces the CMU Linguistic Annotation Backend, an open-source framework that simplifies model deployment and continuous human-in-the-loop fine-tuning of NLP models. CMULAB enables users to leverage the power of multilingual models to quickly adapt and extend existing tools for speech recognition, OCR, translation, and syntactic analysis to new languages, even with limited training data. We describe various tools and APIs that are currently available and how developers can easily add new models/functionality to the framework. Code is available at https://github.com/neulab/cmulab along with a live demo at https://cmulab.dev
AUTOLEX: An Automatic Framework for Linguistic Exploration
Mar 25, 2022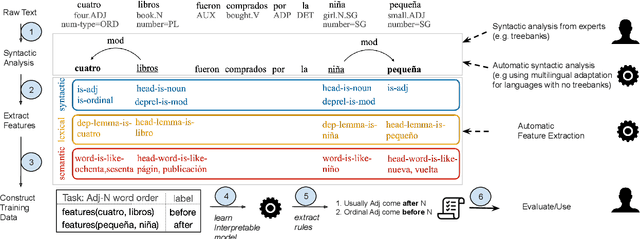
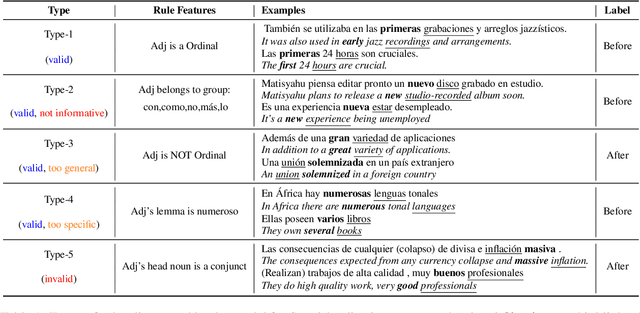
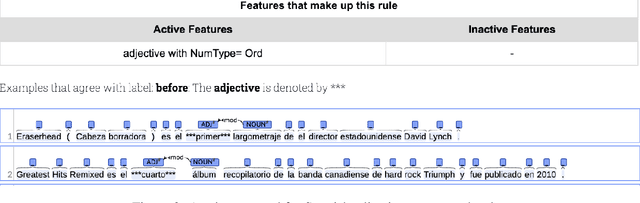
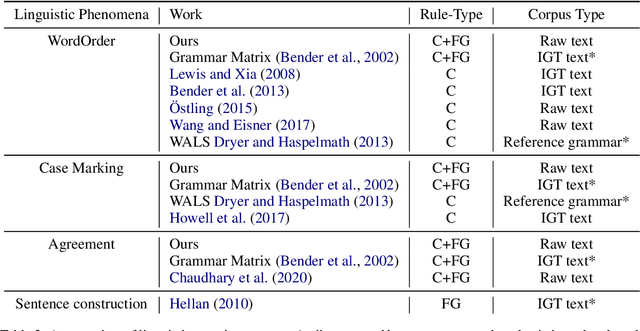
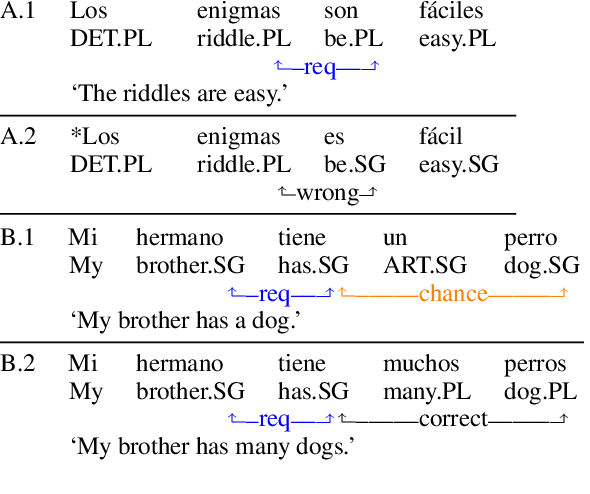
Each language has its own complex systems of word, phrase, and sentence construction, the guiding principles of which are often summarized in grammar descriptions for the consumption of linguists or language learners. However, manual creation of such descriptions is a fraught process, as creating descriptions which describe the language in "its own terms" without bias or error requires both a deep understanding of the language at hand and linguistics as a whole. We propose an automatic framework AutoLEX that aims to ease linguists' discovery and extraction of concise descriptions of linguistic phenomena. Specifically, we apply this framework to extract descriptions for three phenomena: morphological agreement, case marking, and word order, across several languages. We evaluate the descriptions with the help of language experts and propose a method for automated evaluation when human evaluation is infeasible.
Reducing Confusion in Active Learning for Part-Of-Speech Tagging
Nov 02, 2020



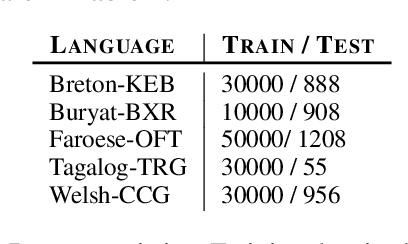
Active learning (AL) uses a data selection algorithm to select useful training samples to minimize annotation cost. This is now an essential tool for building low-resource syntactic analyzers such as part-of-speech (POS) taggers. Existing AL heuristics are generally designed on the principle of selecting uncertain yet representative training instances, where annotating these instances may reduce a large number of errors. However, in an empirical study across six typologically diverse languages (German, Swedish, Galician, North Sami, Persian, and Ukrainian), we found the surprising result that even in an oracle scenario where we know the true uncertainty of predictions, these current heuristics are far from optimal. Based on this analysis, we pose the problem of AL as selecting instances which maximally reduce the confusion between particular pairs of output tags. Extensive experimentation on the aforementioned languages shows that our proposed AL strategy outperforms other AL strategies by a significant margin. We also present auxiliary results demonstrating the importance of proper calibration of models, which we ensure through cross-view training, and analysis demonstrating how our proposed strategy selects examples that more closely follow the oracle data distribution.
Automatic Extraction of Rules Governing Morphological Agreement
Oct 06, 2020

Creating a descriptive grammar of a language is an indispensable step for language documentation and preservation. However, at the same time it is a tedious, time-consuming task. In this paper, we take steps towards automating this process by devising an automated framework for extracting a first-pass grammatical specification from raw text in a concise, human- and machine-readable format. We focus on extracting rules describing agreement, a morphosyntactic phenomenon at the core of the grammars of many of the world's languages. We apply our framework to all languages included in the Universal Dependencies project, with promising results. Using cross-lingual transfer, even with no expert annotations in the language of interest, our framework extracts a grammatical specification which is nearly equivalent to those created with large amounts of gold-standard annotated data. We confirm this finding with human expert evaluations of the rules that our framework produces, which have an average accuracy of 78%. We release an interface demonstrating the extracted rules at https://neulab.github.io/lase/.
A Little Annotation does a Lot of Good: A Study in Bootstrapping Low-resource Named Entity Recognizers
Aug 23, 2019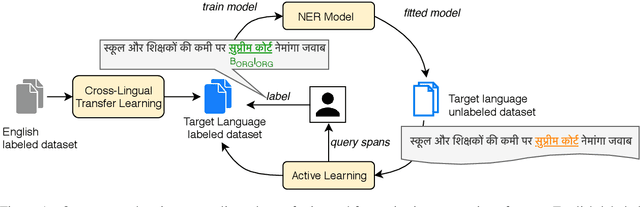
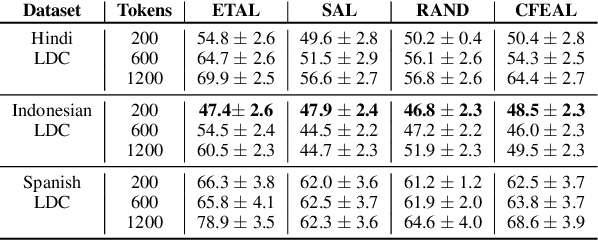
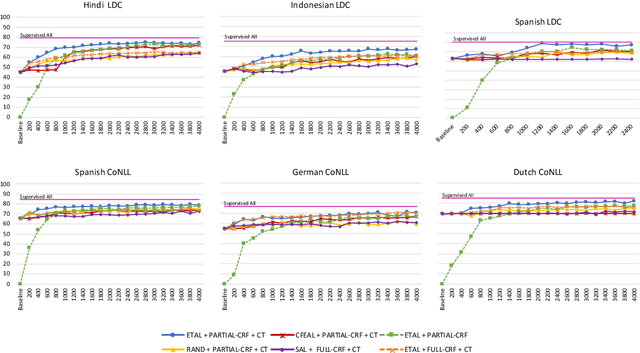
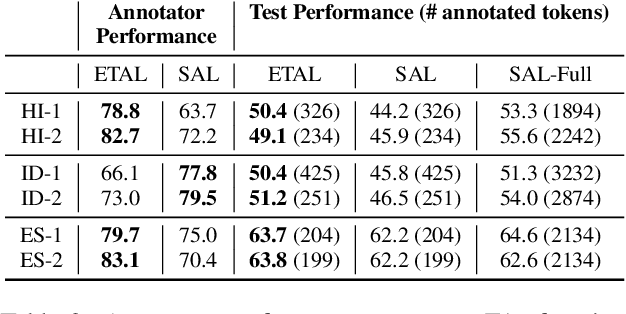
Most state-of-the-art models for named entity recognition (NER) rely on the availability of large amounts of labeled data, making them challenging to extend to new, lower-resourced languages. However, there are now several proposed approaches involving either cross-lingual transfer learning, which learns from other highly resourced languages, or active learning, which efficiently selects effective training data based on model predictions. This paper poses the question: given this recent progress, and limited human annotation, what is the most effective method for efficiently creating high-quality entity recognizers in under-resourced languages? Based on extensive experimentation using both simulated and real human annotation, we find a dual-strategy approach best, starting with a cross-lingual transferred model, then performing targeted annotation of only uncertain entity spans in the target language, minimizing annotator effort. Results demonstrate that cross-lingual transfer is a powerful tool when very little data can be annotated, but an entity-targeted annotation strategy can achieve competitive accuracy quickly, with just one-tenth of training data.
The ARIEL-CMU Systems for LoReHLT18
Feb 24, 2019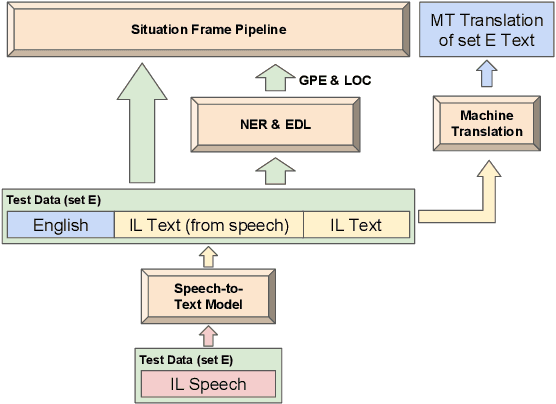
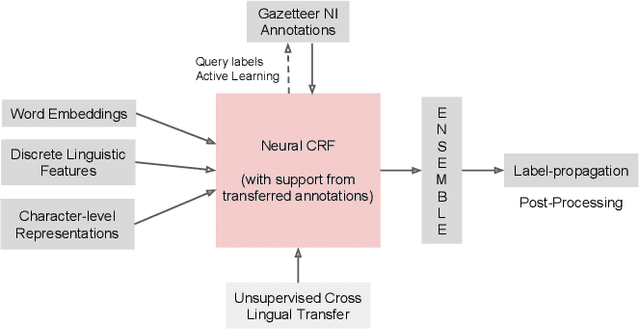
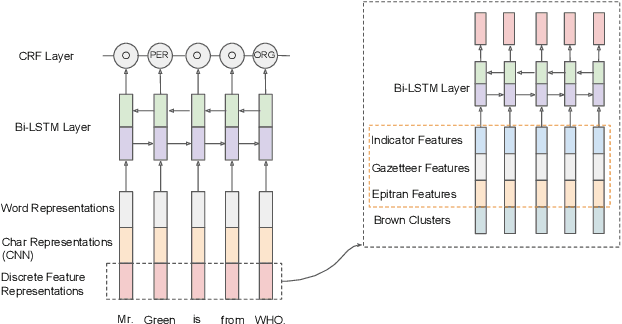
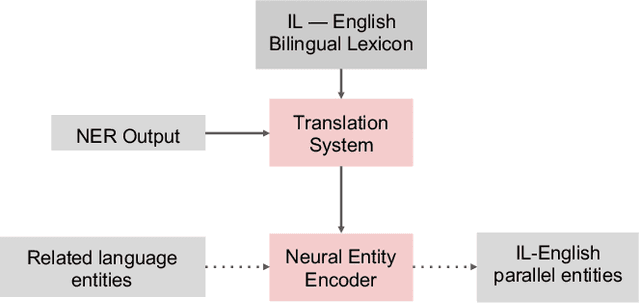
This paper describes the ARIEL-CMU submissions to the Low Resource Human Language Technologies (LoReHLT) 2018 evaluations for the tasks Machine Translation (MT), Entity Discovery and Linking (EDL), and detection of Situation Frames in Text and Speech (SF Text and Speech).