 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Alignment vs Joint Training: A Comparative Study and A Simple Unified Framework
Oct 13, 2019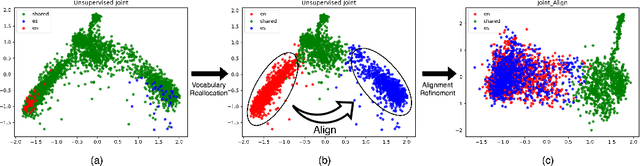
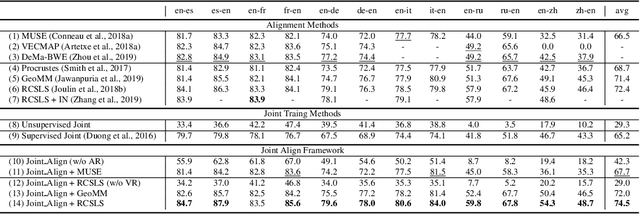


Learning multilingual representations of text has proven a successful method for many cross-lingual transfer learning tasks. There are two main paradigms for learning such representations: (1) alignment, which maps different independently trained monolingual representations into a shared space, and (2) joint training, which directly learns unified multilingual representations using monolingual and cross-lingual objectives jointly. In this paper, we first conduct direct comparisons of representations learned using both of these methods across diverse cross-lingual tasks. Our empirical results reveal a set of pros and cons for both methods, and show that the relative performance of alignment versus joint training is task-dependent. Stemming from this analysis, we propose a simple and novel framework that combines these two previously mutually-exclusive approaches. Extensive experiments on various tasks demonstrate that our proposed framework alleviates limitations of both approaches, and outperforms existing methods on the MUSE bilingual lexicon induction (BLI) benchmark. We further show that our proposed framework can generalize to contextualized representations and achieves state-of-the-art results on the CoNLL cross-lingual NER benchmark.
A Little Annotation does a Lot of Good: A Study in Bootstrapping Low-resource Named Entity Recognizers
Aug 23, 2019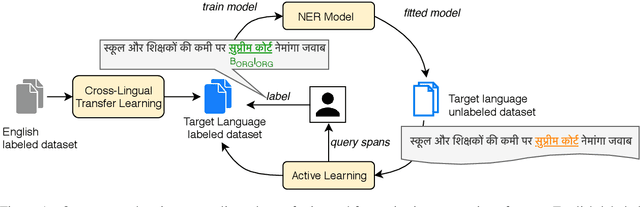
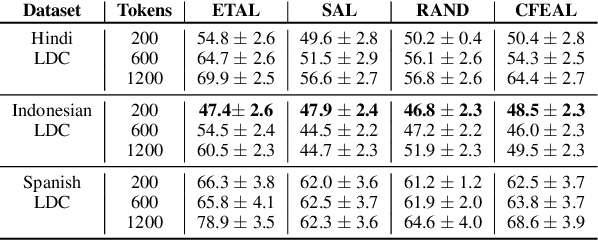
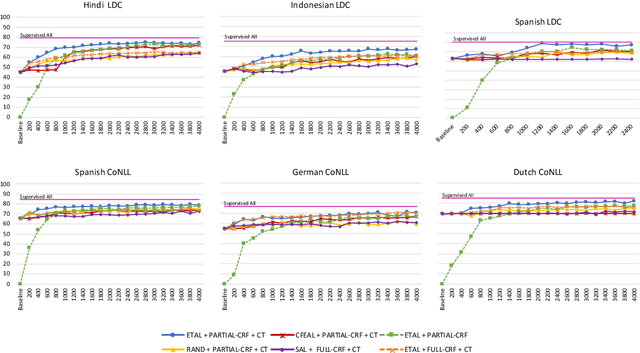
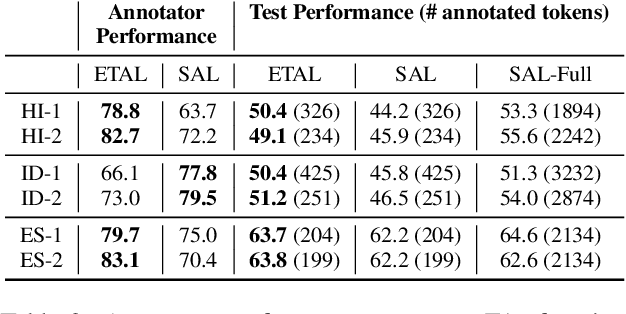
Most state-of-the-art models for named entity recognition (NER) rely on the availability of large amounts of labeled data, making them challenging to extend to new, lower-resourced languages. However, there are now several proposed approaches involving either cross-lingual transfer learning, which learns from other highly resourced languages, or active learning, which efficiently selects effective training data based on model predictions. This paper poses the question: given this recent progress, and limited human annotation, what is the most effective method for efficiently creating high-quality entity recognizers in under-resourced languages? Based on extensive experimentation using both simulated and real human annotation, we find a dual-strategy approach best, starting with a cross-lingual transferred model, then performing targeted annotation of only uncertain entity spans in the target language, minimizing annotator effort. Results demonstrate that cross-lingual transfer is a powerful tool when very little data can be annotated, but an entity-targeted annotation strategy can achieve competitive accuracy quickly, with just one-tenth of training data.
The ARIEL-CMU Systems for LoReHLT18
Feb 24, 2019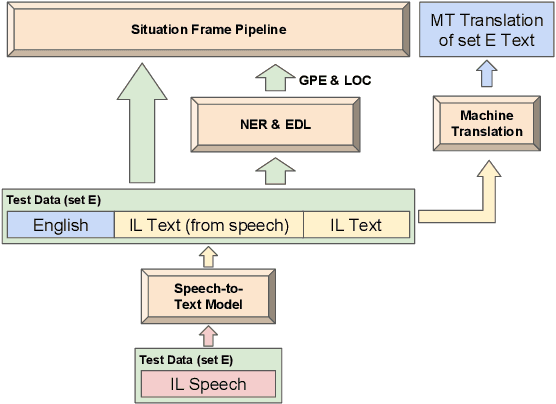
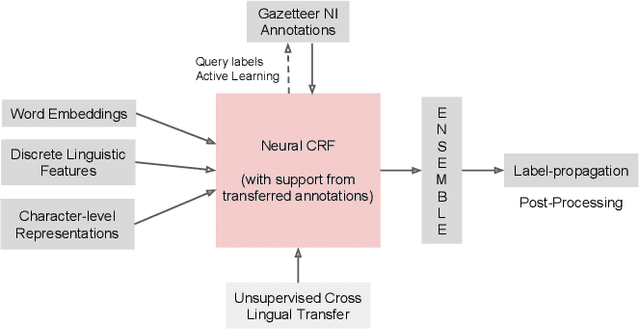
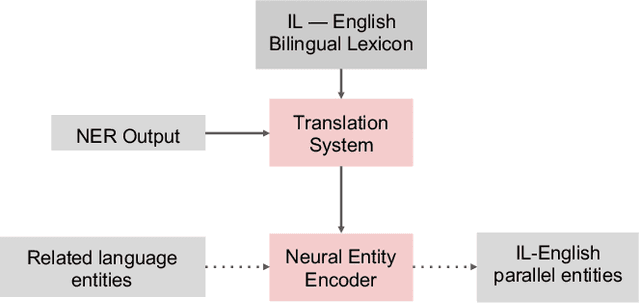
This paper describes the ARIEL-CMU submissions to the Low Resource Human Language Technologies (LoReHLT) 2018 evaluations for the tasks Machine Translation (MT), Entity Discovery and Linking (EDL), and detection of Situation Frames in Text and Speech (SF Text and Speech).
Zero-shot Neural Transfer for Cross-lingual Entity Linking
Nov 09, 2018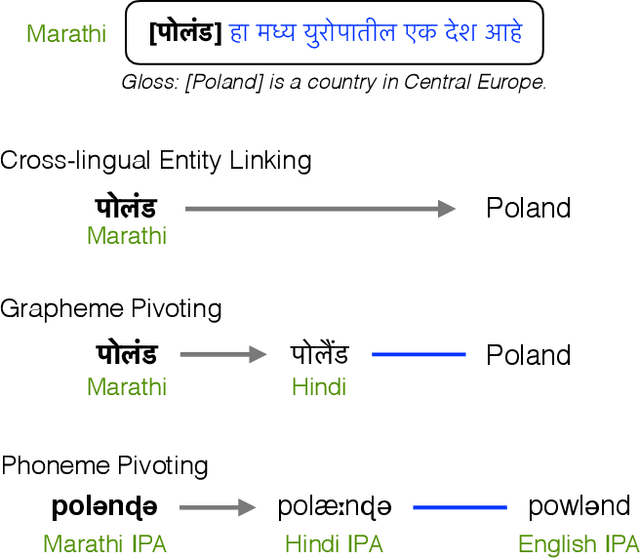



Cross-lingual entity linking maps an entity mention in a source language to its corresponding entry in a structured knowledge base that is in a different (target) language. While previous work relies heavily on bilingual lexical resources to bridge the gap between the source and the target languages, these resources are scarce or unavailable for many low-resource languages. To address this problem, we investigate zero-shot cross-lingual entity linking, in which we assume no bilingual lexical resources are available in the source low-resource language. Specifically, we propose pivot-based entity linking, which leverages information from a high-resource "pivot" language to train character-level neural entity linking models that are transferred to the source low-resource language in a zero-shot manner. With experiments on 9 low-resource languages and transfer through a total of 54 languages, we show that our proposed pivot-based framework improves entity linking accuracy 17% (absolute) on average over the baseline systems, for the zero-shot scenario. Further, we also investigate the use of language-universal phonological representations which improves average accuracy (absolute) by 36% when transferring between languages that use different scripts.
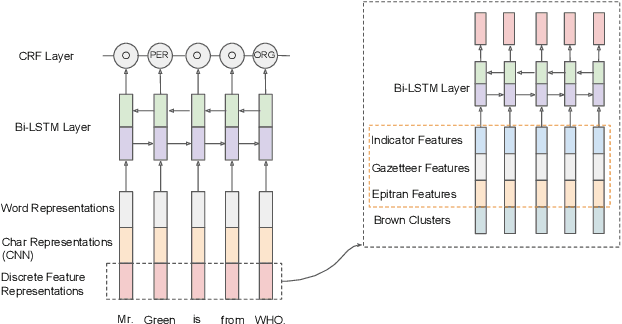
Neural Cross-Lingual Named Entity Recognition with Minimal Resources
Sep 11, 2018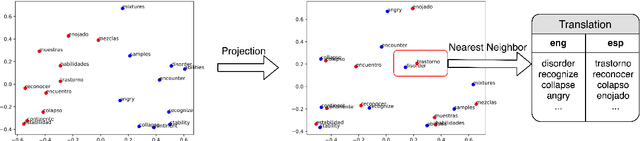

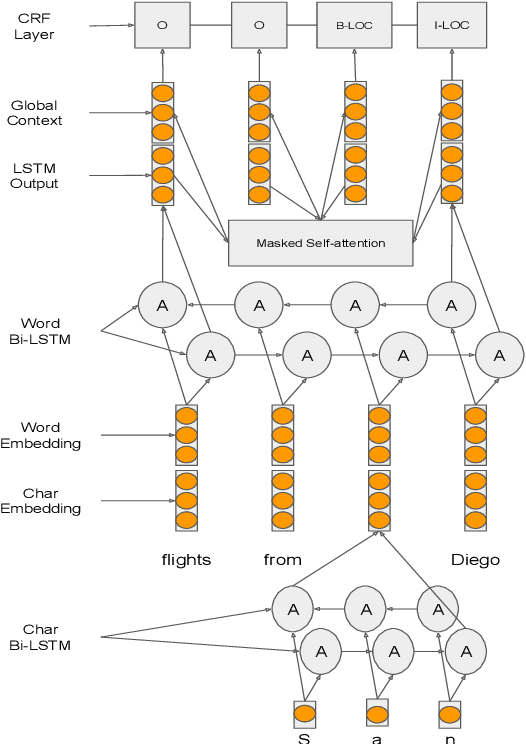
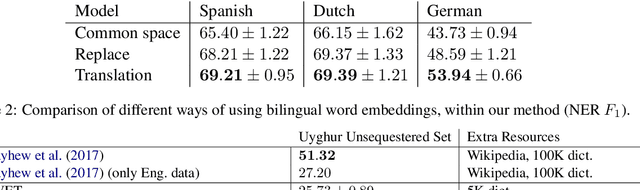
For languages with no annotated resources, unsupervised transfer of natural language processing models such as named-entity recognition (NER) from resource-rich languages would be an appealing capability. However, differences in words and word order across languages make it a challenging problem. To improve mapping of lexical items across languages, we propose a method that finds translations based on bilingual word embeddings. To improve robustness to word order differences, we propose to use self-attention, which allows for a degree of flexibility with respect to word order. We demonstrate that these methods achieve state-of-the-art or competitive NER performance on commonly tested languages under a cross-lingual setting, with much lower resource requirements than past approaches. We also evaluate the challenges of applying these methods to Uyghur, a low-resource language.