 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Code Switching to Transcend the Linguistic Barrier
Jan 30, 2020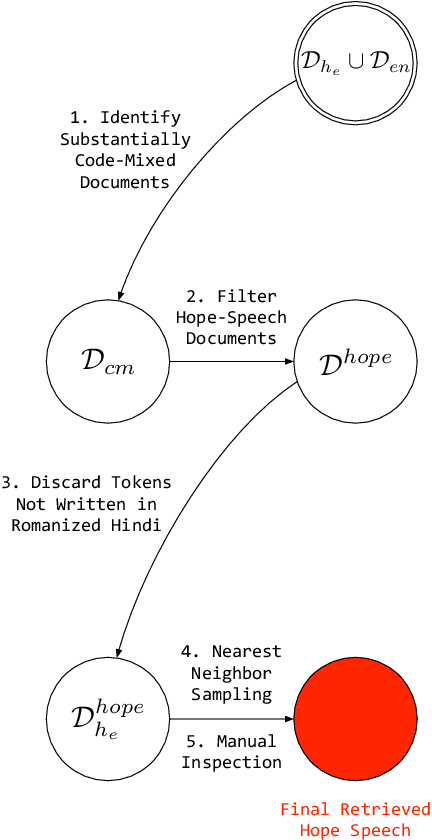
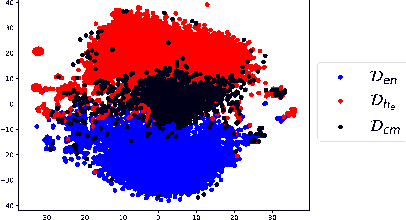

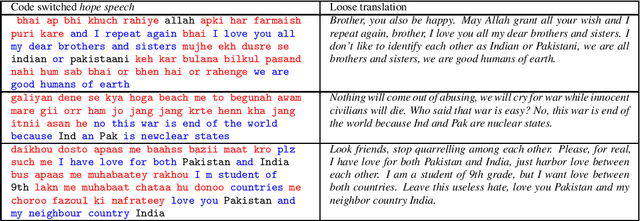
Code mixing (or code switching) is a common phenomenon observed in social-media content generated by a linguistically diverse user-base. Studies show that in the Indian sub-continent, a substantial fraction of social media posts exhibit code switching. While the difficulties posed by code mixed documents to further downstream analyses are well-understood, lending visibility to code mixed documents under certain scenarios may have utility that has been previously overlooked. For instance, a document written in a mixture of multiple languages can be partially accessible to a wider audience; this could be particularly useful if a considerable fraction of the audience lacks fluency in one of the component languages. In this paper, we provide a systematic approach to sample code mixed documents leveraging a polyglot embedding based method that requires minimal supervision. In the context of the 2019 India-Pakistan conflict triggered by the Pulwama terror attack, we demonstrate an untapped potential of harnessing code mixing for human well-being: starting from an existing hostility diffusing \emph{hope speech} classifier solely trained on English documents, code mixed documents are utilized as a bridge to retrieve \emph{hope speech} content written in a low-resource but widely used language - Romanized Hindi. Our proposed pipeline requires minimal supervision and holds promise in substantially reducing web moderation efforts.
Voice for the Voiceless: Active Sampling to Detect Comments Supporting the Rohingyas
Oct 08, 2019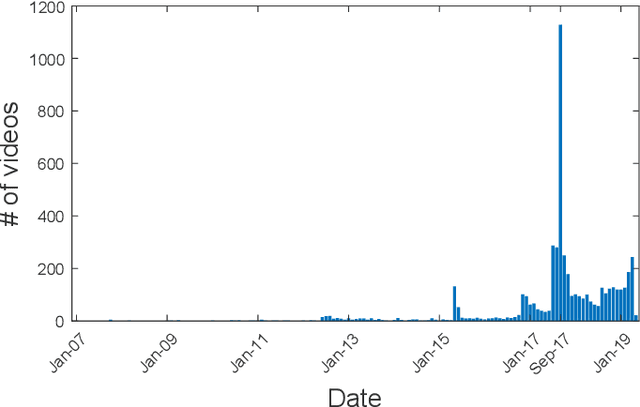
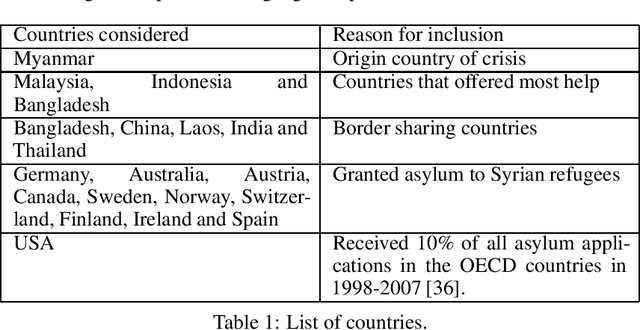
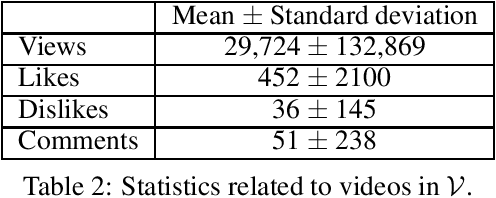

The Rohingya refugee crisis is one of the biggest humanitarian crises of modern times with more than 600,000 Rohingyas rendered homeless according to the United Nations High Commissioner for Refugees. While it has received sustained press attention globally, no comprehensive research has been performed on social media pertaining to this large evolving crisis. In this work, we construct a substantial corpus of YouTube video comments (263,482 comments from 113,250 users in 5,153 relevant videos) with an aim to analyze the possible role of AI in helping a marginalized community. Using a novel combination of multiple Active Learning strategies and a novel active sampling strategy based on nearest-neighbors in the comment-embedding space, we construct a classifier that can detect comments defending the Rohingyas among larger numbers of disparaging and neutral ones. We advocate that beyond the burgeoning field of hate-speech detection, automatic detection of \emph{help-speech} can lend voice to the voiceless people and make the internet safer for marginalized communities.
Kashmir: A Computational Analysis of the Voice of Peace
Sep 11, 2019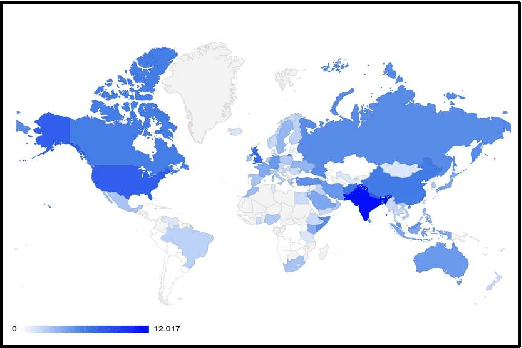

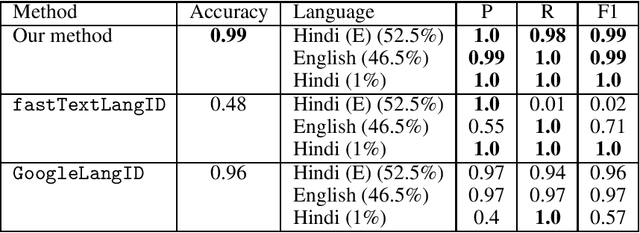
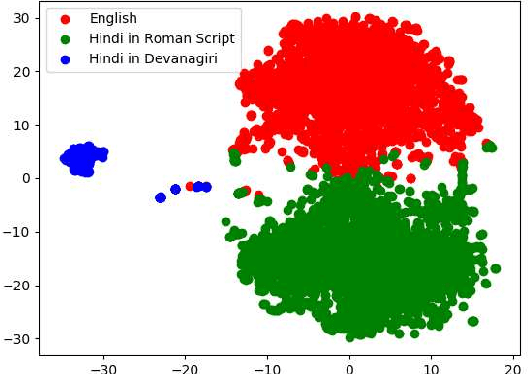
The recent Pulwama terror attack (February 14, 2019, Pulwama, Kashmir) triggered a chain of escalating events between India and Pakistan adding another episode to their 70-year-old dispute over Kashmir. The present era of ubiquitious social media has never seen nuclear powers closer to war. In this paper, we analyze this evolving international crisis via a substantial corpus constructed using comments on YouTube videos (921,235 English comments posted by 392,460 users out of 2.04 million overall comments by 791,289 users on 2,890 videos). Our main contributions in the paper are three-fold. First, we present an observation that polyglot word-embeddings reveal precise and accurate language clusters, and subsequently construct a document language-identification technique with negligible annotation requirements. We demonstrate the viability and utility across a variety of data sets involving several low-resource languages. Second, we present an extensive analysis on temporal trends of pro-peace and pro-war intent through a manually constructed polarity phrase lexicon. We observe that when tensions between the two nations were at their peak, pro-peace intent in the corpus was at its highest point. Finally, in the context of heated discussions in a politically tense situation where two nations are at the brink of a full-fledged war, we argue the importance of automatic identification of user-generated web content that can diffuse hostility and address this prediction task, dubbed \emph{hope-speech detection}.
A Little Annotation does a Lot of Good: A Study in Bootstrapping Low-resource Named Entity Recognizers
Aug 23, 2019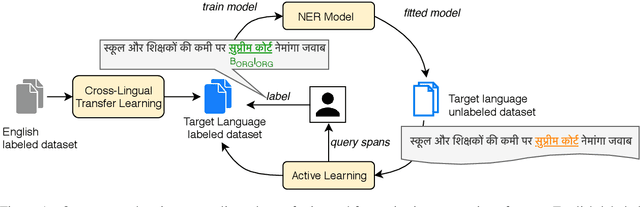
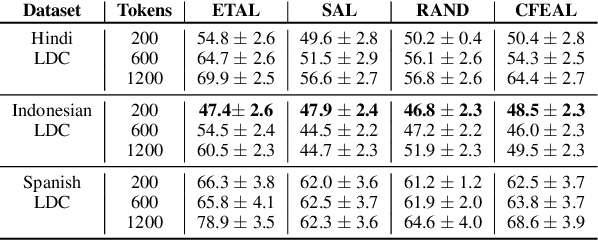
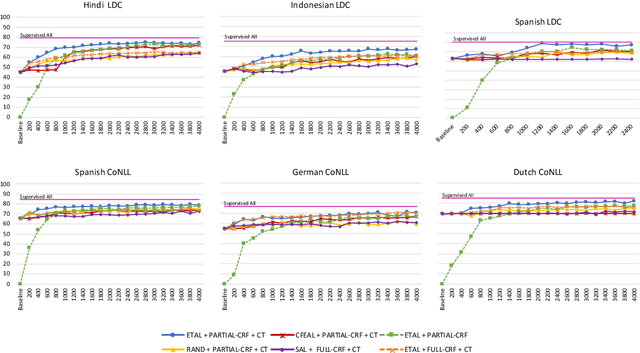
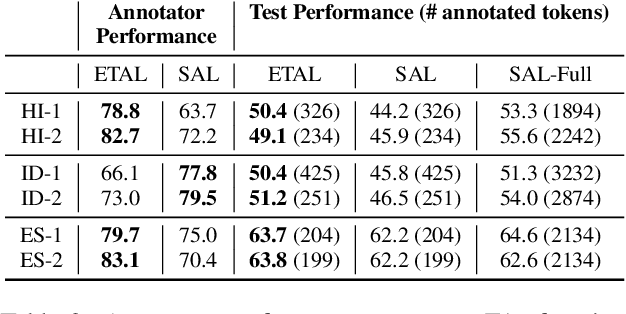
Most state-of-the-art models for named entity recognition (NER) rely on the availability of large amounts of labeled data, making them challenging to extend to new, lower-resourced languages. However, there are now several proposed approaches involving either cross-lingual transfer learning, which learns from other highly resourced languages, or active learning, which efficiently selects effective training data based on model predictions. This paper poses the question: given this recent progress, and limited human annotation, what is the most effective method for efficiently creating high-quality entity recognizers in under-resourced languages? Based on extensive experimentation using both simulated and real human annotation, we find a dual-strategy approach best, starting with a cross-lingual transferred model, then performing targeted annotation of only uncertain entity spans in the target language, minimizing annotator effort. Results demonstrate that cross-lingual transfer is a powerful tool when very little data can be annotated, but an entity-targeted annotation strategy can achieve competitive accuracy quickly, with just one-tenth of training data.
CMU-01 at the SIGMORPHON 2019 Shared Task on Crosslinguality and Context in Morphology
Jul 23, 2019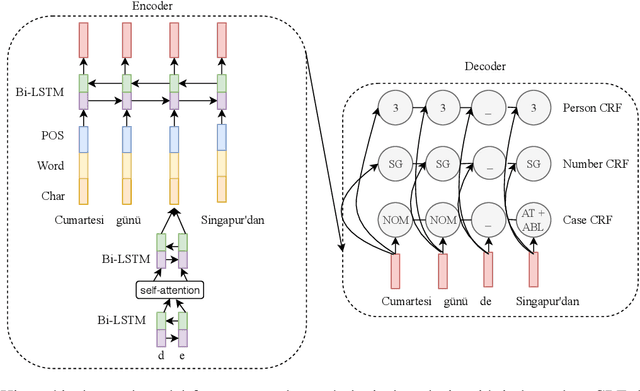
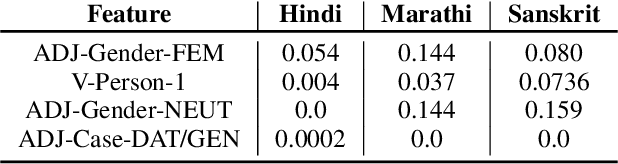
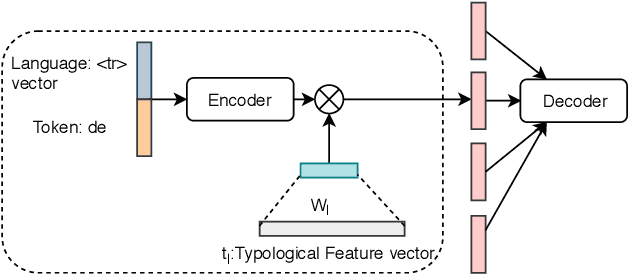
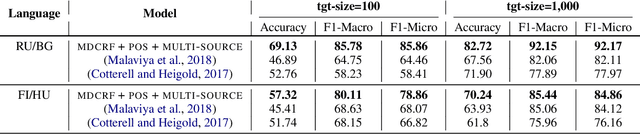
This paper presents the submission by the CMU-01 team to the SIGMORPHON 2019 task 2 of Morphological Analysis and Lemmatization in Context. This task requires us to produce the lemma and morpho-syntactic description of each token in a sequence, for 107 treebanks. We approach this task with a hierarchical neural conditional random field (CRF) model which predicts each coarse-grained feature (eg. POS, Case, etc.) independently. However, most treebanks are under-resourced, thus making it challenging to train deep neural models for them. Hence, we propose a multi-lingual transfer training regime where we transfer from multiple related languages that share similar typology.
Adapting Word Embeddings to New Languages with Morphological and Phonological Subword Representations
Aug 28, 2018
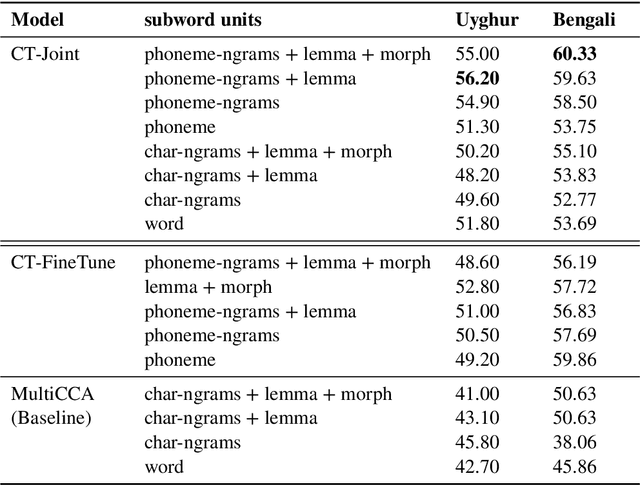
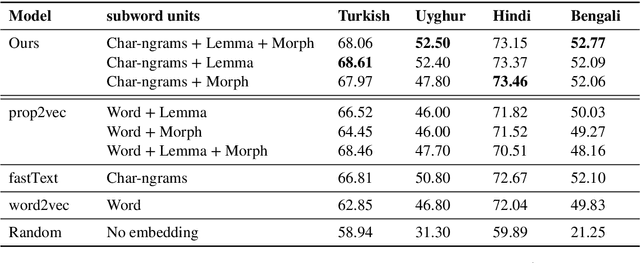
Much work in Natural Language Processing (NLP) has been for resource-rich languages, making generalization to new, less-resourced languages challenging. We present two approaches for improving generalization to low-resourced languages by adapting continuous word representations using linguistically motivated subword units: phonemes, morphemes and graphemes. Our method requires neither parallel corpora nor bilingual dictionaries and provides a significant gain in performance over previous methods relying on these resources. We demonstrate the effectiveness of our approaches on Named Entity Recognition for four languages, namely Uyghur, Turkish, Bengali and Hindi, of which Uyghur and Bengali are low resource languages, and also perform experiments on Machine Translation. Exploiting subwords with transfer learning gives us a boost of +15.2 NER F1 for Uyghur and +9.7 F1 for Bengali. We also show improvements in the monolingual setting where we achieve (avg.) +3 F1 and (avg.) +1.35 BLEU.
The Nonlinearity Coefficient - Predicting Overfitting in Deep Neural Networks
Jun 01, 2018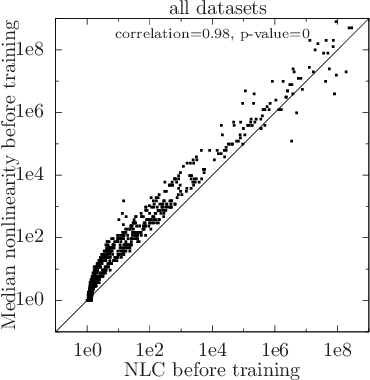
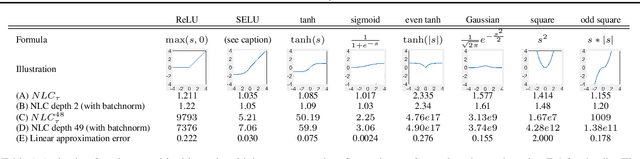
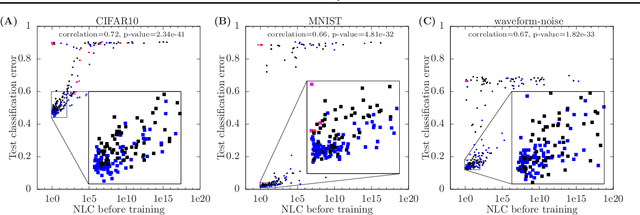

For a long time, designing neural architectures that exhibit high performance was considered a dark art that required expert hand-tuning. One of the few well-known guidelines for architecture design is the avoidance of exploding gradients, though even this guideline has remained relatively vague and circumstantial. We introduce the nonlinearity coefficient (NLC), a measurement of the complexity of the function computed by a neural network that is based on the magnitude of the gradient. Via an extensive empirical study, we show that the NLC is a powerful predictor of test error and that attaining a right-sized NLC is essential for optimal performance. The NLC exhibits a range of intriguing and important properties. It is closely tied to the amount of information gained from computing a single network gradient. It is tied to the error incurred when replacing the nonlinearity operations in the network with linear operations. It is not susceptible to the confounders of multiplicative scaling, additive bias and layer width. It is stable from layer to layer. Hence, we argue that the NLC is the first robust predictor of overfitting in deep networks.
The exploding gradient problem demystified - definition, prevalence, impact, origin, tradeoffs, and solutions
Apr 06, 2018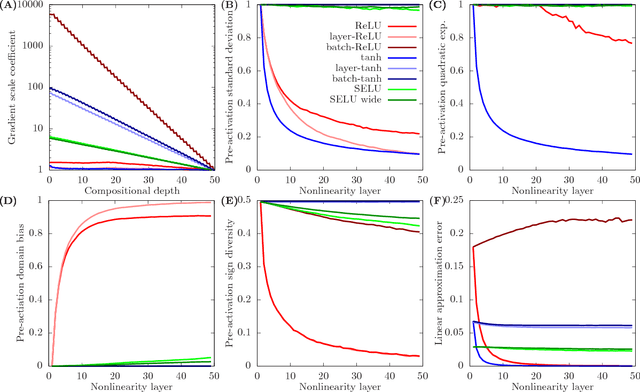
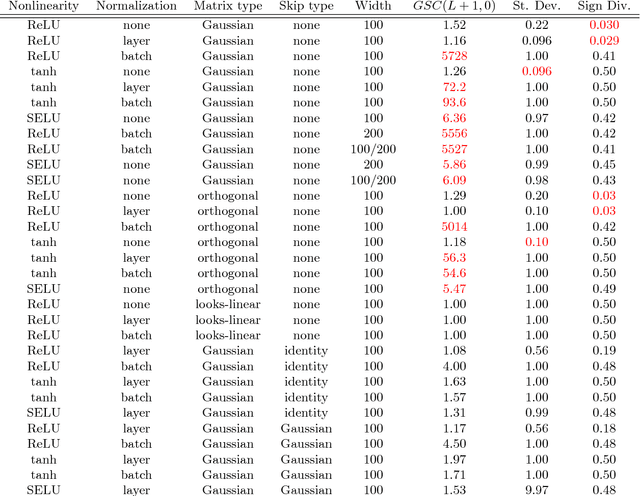

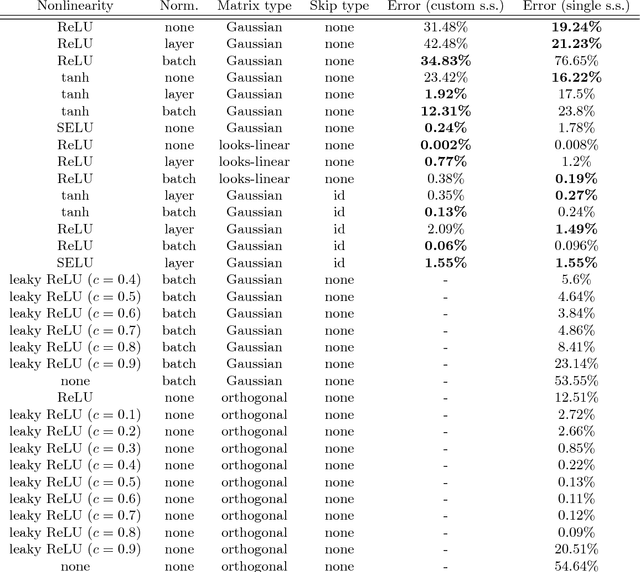
Whereas it is believed that techniques such as Adam, batch normalization and, more recently, SeLU nonlinearities "solve" the exploding gradient problem, we show that this is not the case in general and that in a range of popular MLP architectures, exploding gradients exist and that they limit the depth to which networks can be effectively trained, both in theory and in practice. We explain why exploding gradients occur and highlight the *collapsing domain problem*, which can arise in architectures that avoid exploding gradients. ResNets have significantly lower gradients and thus can circumvent the exploding gradient problem, enabling the effective training of much deeper networks. We show this is a direct consequence of the Pythagorean equation. By noticing that *any neural network is a residual network*, we devise the *residual trick*, which reveals that introducing skip connections simplifies the network mathematically, and that this simplicity may be the major cause for their success.
Nonparametric Neural Networks
Dec 14, 2017
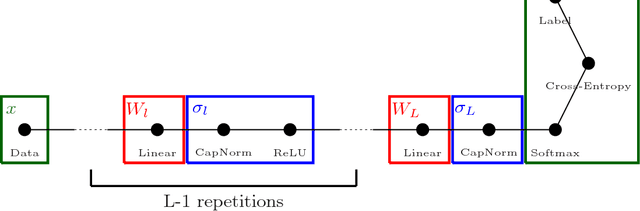
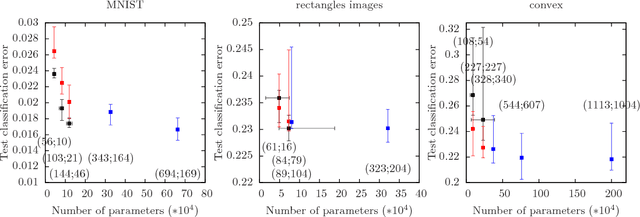

Automatically determining the optimal size of a neural network for a given task without prior information currently requires an expensive global search and training many networks from scratch. In this paper, we address the problem of automatically finding a good network size during a single training cycle. We introduce *nonparametric neural networks*, a non-probabilistic framework for conducting optimization over all possible network sizes and prove its soundness when network growth is limited via an L_p penalty. We train networks under this framework by continuously adding new units while eliminating redundant units via an L_2 penalty. We employ a novel optimization algorithm, which we term *adaptive radial-angular gradient descent* or *AdaRad*, and obtain promising results.
Smoothing proximal gradient method for general structured sparse regression
Jun 29, 2012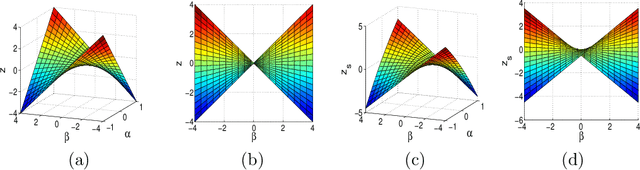
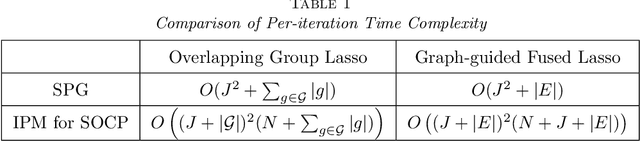
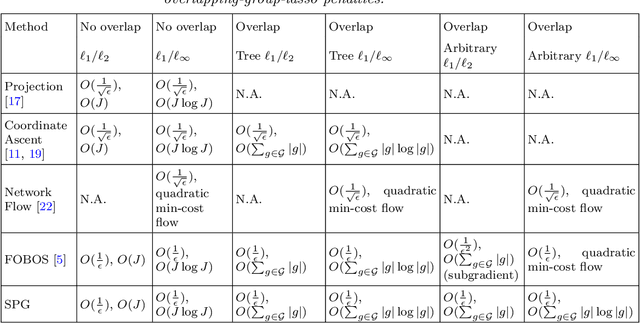
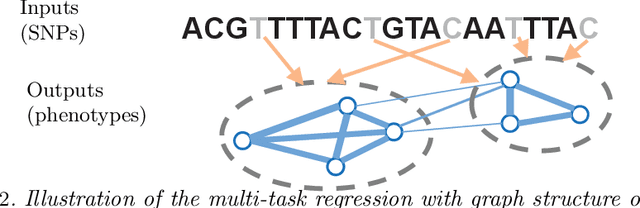
We study the problem of estimating high-dimensional regression models regularized by a structured sparsity-inducing penalty that encodes prior structural information on either the input or output variables. We consider two widely adopted types of penalties of this kind as motivating examples: (1) the general overlapping-group-lasso penalty, generalized from the group-lasso penalty; and (2) the graph-guided-fused-lasso penalty, generalized from the fused-lasso penalty. For both types of penalties, due to their nonseparability and nonsmoothness, developing an efficient optimization method remains a challenging problem. In this paper we propose a general optimization approach, the smoothing proximal gradient (SPG) method, which can solve structured sparse regression problems with any smooth convex loss under a wide spectrum of structured sparsity-inducing penalties. Our approach combines a smoothing technique with an effective proximal gradient method. It achieves a convergence rate significantly faster than the standard first-order methods, subgradient methods, and is much more scalable than the most widely used interior-point methods. The efficiency and scalability of our method are demonstrated on both simulation experiments and real genetic data sets.
* Published in at http://dx.doi.org/10.1214/11-AOAS514 the Annals of Applied Statistics (http://www.imstat.org/aoas/) by the Institute of Mathematical Statistics (http://www.imstat.org)