 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnforcing Fairness Where It Matters: An Approach Based on Difference-of-Convex Constraints
May 18, 2025Fairness in machine learning has become a critical concern, particularly in high-stakes applications. Existing approaches often focus on achieving full fairness across all score ranges generated by predictive models, ensuring fairness in both high and low-scoring populations. However, this stringent requirement can compromise predictive performance and may not align with the practical fairness concerns of stakeholders. In this work, we propose a novel framework for building partially fair machine learning models, which enforce fairness within a specific score range of interest, such as the middle range where decisions are most contested, while maintaining flexibility in other regions. We introduce two statistical metrics to rigorously evaluate partial fairness within a given score range, such as the top 20%-40% of scores. To achieve partial fairness, we propose an in-processing method by formulating the model training problem as constrained optimization with difference-of-convex constraints, which can be solved by an inexact difference-of-convex algorithm (IDCA). We provide the complexity analysis of IDCA for finding a nearly KKT point. Through numerical experiments on real-world datasets, we demonstrate that our framework achieves high predictive performance while enforcing partial fairness where it matters most.
Single-loop Algorithms for Stochastic Non-convex Optimization with Weakly-Convex Constraints
Apr 21, 2025Constrained optimization with multiple functional inequality constraints has significant applications in machine learning. This paper examines a crucial subset of such problems where both the objective and constraint functions are weakly convex. Existing methods often face limitations, including slow convergence rates or reliance on double-loop algorithmic designs. To overcome these challenges, we introduce a novel single-loop penalty-based stochastic algorithm. Following the classical exact penalty method, our approach employs a {\bf hinge-based penalty}, which permits the use of a constant penalty parameter, enabling us to achieve a {\bf state-of-the-art complexity} for finding an approximate Karush-Kuhn-Tucker (KKT) solution. We further extend our algorithm to address finite-sum coupled compositional objectives, which are prevalent in artificial intelligence applications, establishing improved complexity over existing approaches. Finally, we validate our method through experiments on fair learning with receiver operating characteristic (ROC) fairness constraints and continual learning with non-forgetting constraints.
Inexact Moreau Envelope Lagrangian Method for Non-Convex Constrained Optimization under Local Error Bound Conditions on Constraint Functions
Feb 27, 2025In this paper, we study the inexact Moreau envelope Lagrangian (iMELa) method for solving smooth non-convex optimization problems over a simple polytope with additional convex inequality constraints. By incorporating a proximal term into the traditional Lagrangian function, the iMELa method approximately solves a convex optimization subproblem over the polyhedral set at each main iteration. Under the assumption of a local error bound condition for subsets of the feasible set defined by subsets of the constraints, we establish that the iMELa method can find an $\epsilon$-Karush-Kuhn-Tucker point with $\tilde O(\epsilon^{-2})$ gradient oracle complexity.
FedPAE: Peer-Adaptive Ensemble Learning for Asynchronous and Model-Heterogeneous Federated Learning
Oct 17, 2024Federated learning (FL) enables multiple clients with distributed data sources to collaboratively train a shared model without compromising data privacy. However, existing FL paradigms face challenges due to heterogeneity in client data distributions and system capabilities. Personalized federated learning (pFL) has been proposed to mitigate these problems, but often requires a shared model architecture and a central entity for parameter aggregation, resulting in scalability and communication issues. More recently, model-heterogeneous FL has gained attention due to its ability to support diverse client models, but existing methods are limited by their dependence on a centralized framework, synchronized training, and publicly available datasets. To address these limitations, we introduce Federated Peer-Adaptive Ensemble Learning (FedPAE), a fully decentralized pFL algorithm that supports model heterogeneity and asynchronous learning. Our approach utilizes a peer-to-peer model sharing mechanism and ensemble selection to achieve a more refined balance between local and global information. Experimental results show that FedPAE outperforms existing state-of-the-art pFL algorithms, effectively managing diverse client capabilities and demonstrating robustness against statistical heterogeneity.
Model Developmental Safety: A Safety-Centric Method and Applications in Vision-Language Models
Oct 13, 2024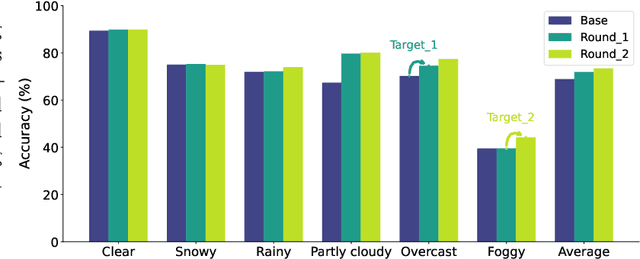
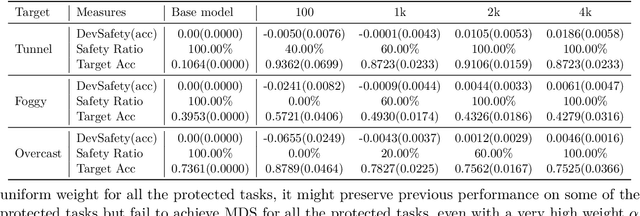
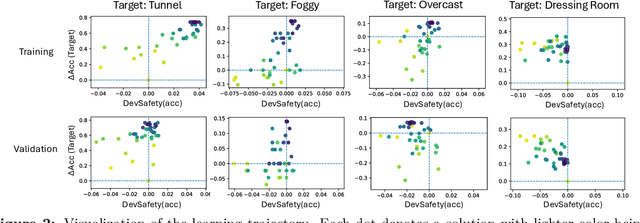
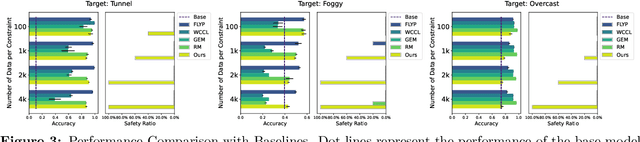
In the real world, a learning-enabled system usually undergoes multiple cycles of model development to enhance the system's ability to handle difficult or emerging tasks. This continual model development process raises a significant issue that the model development for acquiring new or improving existing capabilities may inadvertently lose capabilities of the old model, also known as catastrophic forgetting. Existing continual learning studies focus on mitigating catastrophic forgetting by trading off performance on previous tasks and new tasks to ensure good average performance. However, they are inadequate for many applications especially in safety-critical domains, as failure to strictly preserve the performance of the old model not only introduces safety risks and uncertainties but also imposes substantial expenses in the re-improving and re-validation of existing properties. To address this issue, we introduce model developmental safety as a guarantee of a learning system such that in the model development process the new model should strictly preserve the existing protected capabilities of the old model while improving its performance on target tasks. To ensure the model developmental safety, we present a safety-centric framework by formulating the model developmental safety as data-dependent constraints. Under this framework, we study how to develop a pretrained vision-language model (aka the CLIP model) for acquiring new capabilities or improving existing capabilities of image classification. We propose an efficient constrained optimization algorithm with theoretical guarantee and use its insights to finetune a CLIP model with task-dependent heads for promoting the model developmental safety. Our experiments on improving vision perception capabilities on autonomous driving and scene recognition datasets demonstrate the efficacy of the proposed approach.
Multi-Output Distributional Fairness via Post-Processing
Aug 31, 2024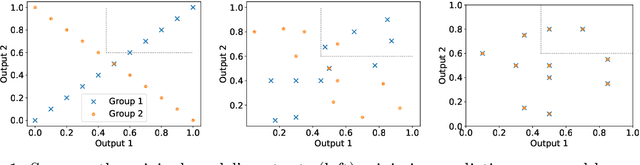
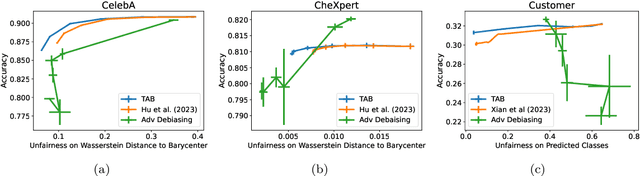
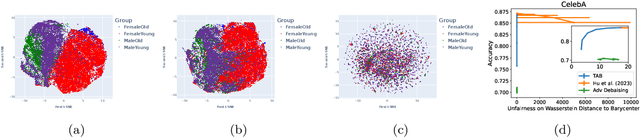
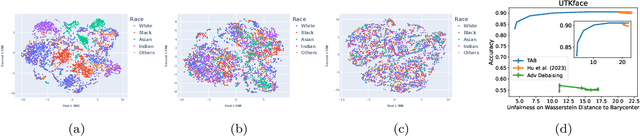
The post-processing approaches are becoming prominent techniques to enhance machine learning models' fairness because of their intuitiveness, low computational cost, and excellent scalability. However, most existing post-processing methods are designed for task-specific fairness measures and are limited to single-output models. In this paper, we introduce a post-processing method for multi-output models, such as the ones used for multi-task/multi-class classification and representation learning, to enhance a model's distributional parity, a task-agnostic fairness measure. Existing techniques to achieve distributional parity are based on the (inverse) cumulative density function of a model's output, which is limited to single-output models. Extending previous works, our method employs an optimal transport mapping to move a model's outputs across different groups towards their empirical Wasserstein barycenter. An approximation technique is applied to reduce the complexity of computing the exact barycenter and a kernel regression method is proposed for extending this process to out-of-sample data. Our empirical studies, which compare our method to current existing post-processing baselines on multi-task/multi-class classification and representation learning tasks, demonstrate the effectiveness of the proposed approach.
Provable Optimization for Adversarial Fair Self-supervised Contrastive Learning
Jun 09, 2024
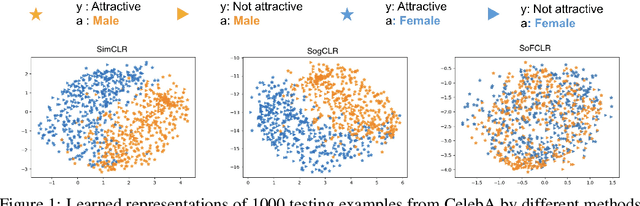
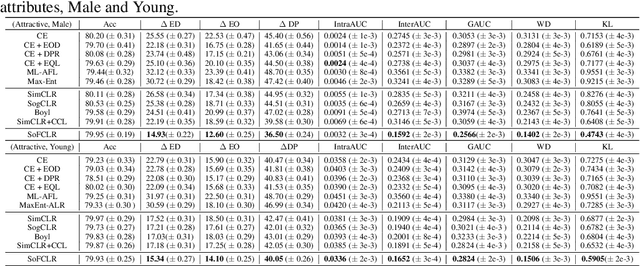
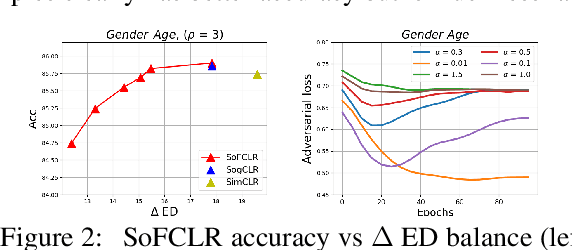
This paper studies learning fair encoders in a self-supervised learning (SSL) setting, in which all data are unlabeled and only a small portion of them are annotated with sensitive attribute. Adversarial fair representation learning is well suited for this scenario by minimizing a contrastive loss over unlabeled data while maximizing an adversarial loss of predicting the sensitive attribute over the data with sensitive attribute. Nevertheless, optimizing adversarial fair representation learning presents significant challenges due to solving a non-convex non-concave minimax game. The complexity deepens when incorporating a global contrastive loss that contrasts each anchor data point against all other examples. A central question is ``{\it can we design a provable yet efficient algorithm for solving adversarial fair self-supervised contrastive learning}?'' Building on advanced optimization techniques, we propose a stochastic algorithm dubbed SoFCLR with a convergence analysis under reasonable conditions without requring a large batch size. We conduct extensive experiments to demonstrate the effectiveness of the proposed approach for downstream classification with eight fairness notions.
First-order Methods for Affinely Constrained Composite Non-convex Non-smooth Problems: Lower Complexity Bound and Near-optimal Methods
Jul 14, 2023Many recent studies on first-order methods (FOMs) focus on \emph{composite non-convex non-smooth} optimization with linear and/or nonlinear function constraints. Upper (or worst-case) complexity bounds have been established for these methods. However, little can be claimed about their optimality as no lower bound is known, except for a few special \emph{smooth non-convex} cases. In this paper, we make the first attempt to establish lower complexity bounds of FOMs for solving a class of composite non-convex non-smooth optimization with linear constraints. Assuming two different first-order oracles, we establish lower complexity bounds of FOMs to produce a (near) $\epsilon$-stationary point of a problem (and its reformulation) in the considered problem class, for any given tolerance $\epsilon>0$. In addition, we present an inexact proximal gradient (IPG) method by using the more relaxed one of the two assumed first-order oracles. The oracle complexity of the proposed IPG, to find a (near) $\epsilon$-stationary point of the considered problem and its reformulation, matches our established lower bounds up to a logarithmic factor. Therefore, our lower complexity bounds and the proposed IPG method are almost non-improvable.
Single-Loop Switching Subgradient Methods for Non-Smooth Weakly Convex Optimization with Non-Smooth Convex Constraints
Jan 30, 2023



In this paper, we consider a general non-convex constrained optimization problem, where the objective function is weakly convex and the constraint function is convex while they can both be non-smooth. This class of problems arises from many applications in machine learning such as fairness-aware supervised learning. To solve this problem, we consider the classical switching subgradient method by Polyak (1965), which is an intuitive and easily implementable first-order method. Before this work, its iteration complexity was only known for convex optimization. We prove its oracle complexity for finding a nearly stationary point when the objective function is non-convex. The analysis is derived separately when the constraint function is deterministic and stochastic. Compared to existing methods, especially the double-loop methods, the switching gradient method can be applied to non-smooth problems and only has a single loop, which saves the effort on tuning the number of inner iterations.
Stochastic Methods for AUC Optimization subject to AUC-based Fairness Constraints
Dec 27, 2022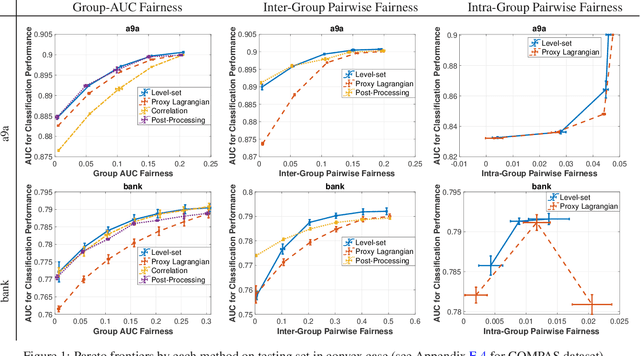
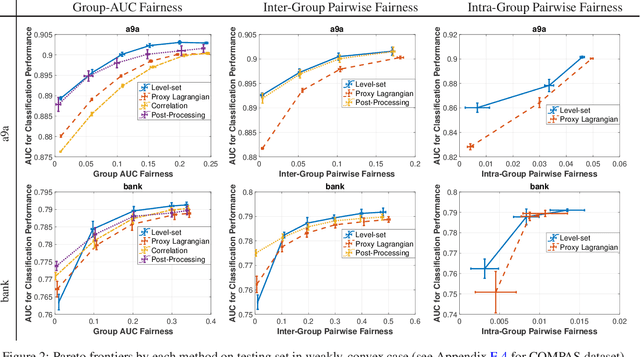
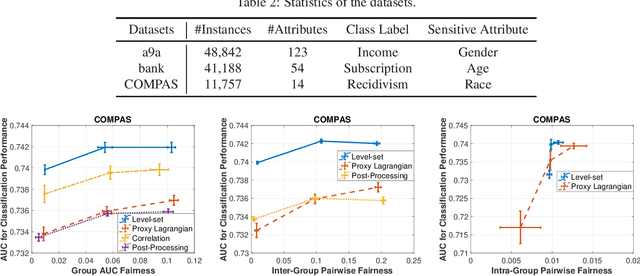
As machine learning being used increasingly in making high-stakes decisions, an arising challenge is to avoid unfair AI systems that lead to discriminatory decisions for protected population. A direct approach for obtaining a fair predictive model is to train the model through optimizing its prediction performance subject to fairness constraints, which achieves Pareto efficiency when trading off performance against fairness. Among various fairness metrics, the ones based on the area under the ROC curve (AUC) are emerging recently because they are threshold-agnostic and effective for unbalanced data. In this work, we formulate the training problem of a fairness-aware machine learning model as an AUC optimization problem subject to a class of AUC-based fairness constraints. This problem can be reformulated as a min-max optimization problem with min-max constraints, which we solve by stochastic first-order methods based on a new Bregman divergence designed for the special structure of the problem. We numerically demonstrate the effectiveness of our approach on real-world data under different fairness metrics.