 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Open-source World Models
Jan 28, 2026We present LingBot-World, an open-sourced world simulator stemming from video generation. Positioned as a top-tier world model, LingBot-World offers the following features. (1) It maintains high fidelity and robust dynamics in a broad spectrum of environments, including realism, scientific contexts, cartoon styles, and beyond. (2) It enables a minute-level horizon while preserving contextual consistency over time, which is also known as "long-term memory". (3) It supports real-time interactivity, achieving a latency of under 1 second when producing 16 frames per second. We provide public access to the code and model in an effort to narrow the divide between open-source and closed-source technologies. We believe our release will empower the community with practical applications across areas like content creation, gaming, and robot learning.
SlingBAG Pro: Accelerating point cloud-based iterative reconstruction for 3D photoacoustic imaging with arbitrary array geometries
Jan 06, 2026High-quality three-dimensional (3D) photoacoustic imaging (PAI) is gaining increasing attention in clinical applications. To address the challenges of limited space and high costs, irregular geometric transducer arrays that conform to specific imaging regions are promising for achieving high-quality 3D PAI with fewer transducers. However, traditional iterative reconstruction algorithms struggle with irregular array configurations, suffering from high computational complexity, substantial memory requirements, and lengthy reconstruction times. In this work, we introduce SlingBAG Pro, an advanced reconstruction algorithm based on the point cloud iteration concept of the Sliding ball adaptive growth (SlingBAG) method, while extending its compatibility to arbitrary array geometries. SlingBAG Pro maintains high reconstruction quality, reduces the number of required transducers, and employs a hierarchical optimization strategy that combines zero-gradient filtering with progressively increased temporal sampling rates during iteration. This strategy rapidly removes redundant spatial point clouds, accelerates convergence, and significantly shortens overall reconstruction time. Compared to the original SlingBAG algorithm, SlingBAG Pro achieves up to a 2.2-fold speed improvement in point cloud-based 3D PA reconstruction under irregular array geometries. The proposed method is validated through both simulation and in vivo mouse experiments, and the source code is publicly available at https://github.com/JaegerCQ/SlingBAG_Pro.
A Review of Machine Learning for Cavitation Intensity Recognition in Complex Industrial Systems
Nov 19, 2025Cavitation intensity recognition (CIR) is a critical technology for detecting and evaluating cavitation phenomena in hydraulic machinery, with significant implications for operational safety, performance optimization, and maintenance cost reduction in complex industrial systems. Despite substantial research progress, a comprehensive review that systematically traces the development trajectory and provides explicit guidance for future research is still lacking. To bridge this gap, this paper presents a thorough review and analysis of hundreds of publications on intelligent CIR across various types of mechanical equipment from 2002 to 2025, summarizing its technological evolution and offering insights for future development. The early stages are dominated by traditional machine learning approaches that relied on manually engineered features under the guidance of domain expert knowledge. The advent of deep learning has driven the development of end-to-end models capable of automatically extracting features from multi-source signals, thereby significantly improving recognition performance and robustness. Recently, physical informed diagnostic models have been proposed to embed domain knowledge into deep learning models, which can enhance interpretability and cross-condition generalization. In the future, transfer learning, multi-modal fusion, lightweight network architectures, and the deployment of industrial agents are expected to propel CIR technology into a new stage, addressing challenges in multi-source data acquisition, standardized evaluation, and industrial implementation. The paper aims to systematically outline the evolution of CIR technology and highlight the emerging trend of integrating deep learning with physical knowledge. This provides a significant reference for researchers and practitioners in the field of intelligent cavitation diagnosis in complex industrial systems.
Pressure2Motion: Hierarchical Motion Synthesis from Ground Pressure with Text Guidance
Nov 07, 2025We present Pressure2Motion, a novel motion capture algorithm that synthesizes human motion from a ground pressure sequence and text prompt. It eliminates the need for specialized lighting setups, cameras, or wearable devices, making it suitable for privacy-preserving, low-light, and low-cost motion capture scenarios. Such a task is severely ill-posed due to the indeterminate nature of the pressure signals to full-body motion. To address this issue, we introduce Pressure2Motion, a generative model that leverages pressure features as input and utilizes a text prompt as a high-level guiding constraint. Specifically, our model utilizes a dual-level feature extractor that accurately interprets pressure data, followed by a hierarchical diffusion model that discerns broad-scale movement trajectories and subtle posture adjustments. Both the physical cues gained from the pressure sequence and the semantic guidance derived from descriptive texts are leveraged to guide the motion generation with precision. To the best of our knowledge, Pressure2Motion is a pioneering work in leveraging both pressure data and linguistic priors for motion generation, and the established MPL benchmark is the first benchmark for this task. Experiments show our method generates high-fidelity, physically plausible motions, establishing a new state-of-the-art for this task. The codes and benchmarks will be publicly released upon publication.
ComGS: Efficient 3D Object-Scene Composition via Surface Octahedral Probes
Oct 09, 2025Gaussian Splatting (GS) enables immersive rendering, but realistic 3D object-scene composition remains challenging. Baked appearance and shadow information in GS radiance fields cause inconsistencies when combining objects and scenes. Addressing this requires relightable object reconstruction and scene lighting estimation. For relightable object reconstruction, existing Gaussian-based inverse rendering methods often rely on ray tracing, leading to low efficiency. We introduce Surface Octahedral Probes (SOPs), which store lighting and occlusion information and allow efficient 3D querying via interpolation, avoiding expensive ray tracing. SOPs provide at least a 2x speedup in reconstruction and enable real-time shadow computation in Gaussian scenes. For lighting estimation, existing Gaussian-based inverse rendering methods struggle to model intricate light transport and often fail in complex scenes, while learning-based methods predict lighting from a single image and are viewpoint-sensitive. We observe that 3D object-scene composition primarily concerns the object's appearance and nearby shadows. Thus, we simplify the challenging task of full scene lighting estimation by focusing on the environment lighting at the object's placement. Specifically, we capture a 360 degrees reconstructed radiance field of the scene at the location and fine-tune a diffusion model to complete the lighting. Building on these advances, we propose ComGS, a novel 3D object-scene composition framework. Our method achieves high-quality, real-time rendering at around 28 FPS, produces visually harmonious results with vivid shadows, and requires only 36 seconds for editing. Code and dataset are available at https://nju-3dv.github.io/projects/ComGS/.
SpatialVID: A Large-Scale Video Dataset with Spatial Annotations
Sep 11, 2025Significant progress has been made in spatial intelligence, spanning both spatial reconstruction and world exploration. However, the scalability and real-world fidelity of current models remain severely constrained by the scarcity of large-scale, high-quality training data. While several datasets provide camera pose information, they are typically limited in scale, diversity, and annotation richness, particularly for real-world dynamic scenes with ground-truth camera motion. To this end, we collect \textbf{SpatialVID}, a dataset consists of a large corpus of in-the-wild videos with diverse scenes, camera movements and dense 3D annotations such as per-frame camera poses, depth, and motion instructions. Specifically, we collect more than 21,000 hours of raw video, and process them into 2.7 million clips through a hierarchical filtering pipeline, totaling 7,089 hours of dynamic content. A subsequent annotation pipeline enriches these clips with detailed spatial and semantic information, including camera poses, depth maps, dynamic masks, structured captions, and serialized motion instructions. Analysis of SpatialVID's data statistics reveals a richness and diversity that directly foster improved model generalization and performance, establishing it as a key asset for the video and 3D vision research community.
From Drone Imagery to Livability Mapping: AI-powered Environment Perception in Rural China
Aug 29, 2025



With the deepening of poverty alleviation and rural revitalization strategies, improving the rural living environment and enhancing the quality of life have become key priorities. Rural livability is a key indicator for measuring the effectiveness of these efforts. Current measurement approaches face significant limitations, as questionnaire-based methods are difficult to scale, while urban-oriented visual perception methods are poorly suited for rural contexts. In this paper, a rural-specific livability assessment framework was proposed based on drone imagery and multimodal large language models (MLLMs). To comprehensively assess village livability, this study first used a top-down approach to collect large-scale drone imagery of 1,766 villages in 146 counties across China. In terms of the model framework, an efficient image comparison mechanism was developed, incorporating binary search interpolation to determine effective image pairs while reducing comparison iterations. Building on expert knowledge, a chain-of-thought prompting suitable for nationwide rural livability measurement was constructed, considering both living quality and ecological habitability dimensions. This approach enhanced the rationality and reliability of the livability assessment. Finally, this study characterized the spatial heterogeneity of rural livability across China and thoroughly analyzed its influential factors. The results show that: (1) The rural livability in China demonstrates a dual-core-periphery spatial pattern, radiating outward from Sichuan and Zhejiang provinces with declining gradients; (2) Among various influential factors, government fiscal expenditure emerged as the core determinant, with each unit increase corresponding to a 3.9 - 4.9 unit enhancement in livability. The findings provide valuable insights for rural construction policy-making.
A Survey: Learning Embodied Intelligence from Physical Simulators and World Models
Jul 01, 2025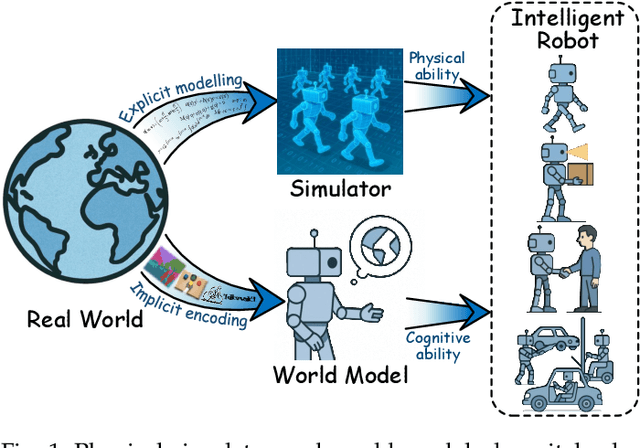
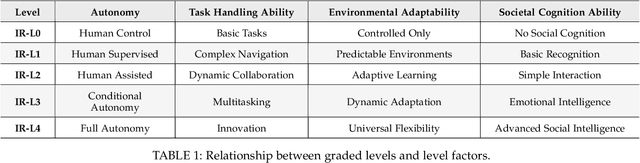
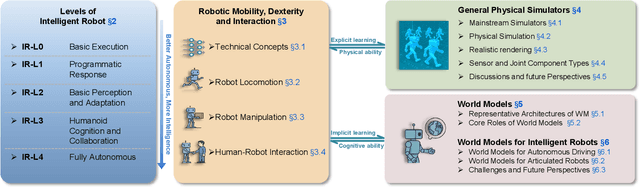

The pursuit of artificial general intelligence (AGI) has placed embodied intelligence at the forefront of robotics research. Embodied intelligence focuses on agents capable of perceiving, reasoning, and acting within the physical world. Achieving robust embodied intelligence requires not only advanced perception and control, but also the ability to ground abstract cognition in real-world interactions. Two foundational technologies, physical simulators and world models, have emerged as critical enablers in this quest. Physical simulators provide controlled, high-fidelity environments for training and evaluating robotic agents, allowing safe and efficient development of complex behaviors. In contrast, world models empower robots with internal representations of their surroundings, enabling predictive planning and adaptive decision-making beyond direct sensory input. This survey systematically reviews recent advances in learning embodied AI through the integration of physical simulators and world models. We analyze their complementary roles in enhancing autonomy, adaptability, and generalization in intelligent robots, and discuss the interplay between external simulation and internal modeling in bridging the gap between simulated training and real-world deployment. By synthesizing current progress and identifying open challenges, this survey aims to provide a comprehensive perspective on the path toward more capable and generalizable embodied AI systems. We also maintain an active repository that contains up-to-date literature and open-source projects at https://github.com/NJU3DV-LoongGroup/Embodied-World-Models-Survey.
Hallo4: High-Fidelity Dynamic Portrait Animation via Direct Preference Optimization and Temporal Motion Modulation
May 29, 2025Generating highly dynamic and photorealistic portrait animations driven by audio and skeletal motion remains challenging due to the need for precise lip synchronization, natural facial expressions, and high-fidelity body motion dynamics. We propose a human-preference-aligned diffusion framework that addresses these challenges through two key innovations. First, we introduce direct preference optimization tailored for human-centric animation, leveraging a curated dataset of human preferences to align generated outputs with perceptual metrics for portrait motion-video alignment and naturalness of expression. Second, the proposed temporal motion modulation resolves spatiotemporal resolution mismatches by reshaping motion conditions into dimensionally aligned latent features through temporal channel redistribution and proportional feature expansion, preserving the fidelity of high-frequency motion details in diffusion-based synthesis. The proposed mechanism is complementary to existing UNet and DiT-based portrait diffusion approaches, and experiments demonstrate obvious improvements in lip-audio synchronization, expression vividness, body motion coherence over baseline methods, alongside notable gains in human preference metrics. Our model and source code can be found at: https://github.com/xyz123xyz456/hallo4.
Direct3D-S2: Gigascale 3D Generation Made Easy with Spatial Sparse Attention
May 26, 2025Generating high-resolution 3D shapes using volumetric representations such as Signed Distance Functions (SDFs) presents substantial computational and memory challenges. We introduce Direct3D-S2, a scalable 3D generation framework based on sparse volumes that achieves superior output quality with dramatically reduced training costs. Our key innovation is the Spatial Sparse Attention (SSA) mechanism, which greatly enhances the efficiency of Diffusion Transformer (DiT) computations on sparse volumetric data. SSA allows the model to effectively process large token sets within sparse volumes, substantially reducing computational overhead and achieving a 3.9x speedup in the forward pass and a 9.6x speedup in the backward pass. Our framework also includes a variational autoencoder (VAE) that maintains a consistent sparse volumetric format across input, latent, and output stages. Compared to previous methods with heterogeneous representations in 3D VAE, this unified design significantly improves training efficiency and stability. Our model is trained on public available datasets, and experiments demonstrate that Direct3D-S2 not only surpasses state-of-the-art methods in generation quality and efficiency, but also enables training at 1024 resolution using only 8 GPUs, a task typically requiring at least 32 GPUs for volumetric representations at 256 resolution, thus making gigascale 3D generation both practical and accessible. Project page: https://www.neural4d.com/research/direct3d-s2.