 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMap2Thought: Explicit 3D Spatial Reasoning via Metric Cognitive Maps
Jan 16, 2026We propose Map2Thought, a framework that enables explicit and interpretable spatial reasoning for 3D VLMs. The framework is grounded in two key components: Metric Cognitive Map (Metric-CogMap) and Cognitive Chain-of-Thought (Cog-CoT). Metric-CogMap provides a unified spatial representation by integrating a discrete grid for relational reasoning with a continuous, metric-scale representation for precise geometric understanding. Building upon the Metric-CogMap, Cog-CoT performs explicit geometric reasoning through deterministic operations, including vector operations, bounding-box distances, and occlusion-aware appearance order cues, producing interpretable inference traces grounded in 3D structure. Experimental results show that Map2Thought enables explainable 3D understanding, achieving 59.9% accuracy using only half the supervision, closely matching the 60.9% baseline trained with the full dataset. It consistently outperforms state-of-the-art methods by 5.3%, 4.8%, and 4.0% under 10%, 25%, and 50% training subsets, respectively, on the VSI-Bench.
UltraShape 1.0: High-Fidelity 3D Shape Generation via Scalable Geometric Refinement
Dec 24, 2025In this report, we introduce UltraShape 1.0, a scalable 3D diffusion framework for high-fidelity 3D geometry generation. The proposed approach adopts a two-stage generation pipeline: a coarse global structure is first synthesized and then refined to produce detailed, high-quality geometry. To support reliable 3D generation, we develop a comprehensive data processing pipeline that includes a novel watertight processing method and high-quality data filtering. This pipeline improves the geometric quality of publicly available 3D datasets by removing low-quality samples, filling holes, and thickening thin structures, while preserving fine-grained geometric details. To enable fine-grained geometry refinement, we decouple spatial localization from geometric detail synthesis in the diffusion process. We achieve this by performing voxel-based refinement at fixed spatial locations, where voxel queries derived from coarse geometry provide explicit positional anchors encoded via RoPE, allowing the diffusion model to focus on synthesizing local geometric details within a reduced, structured solution space. Our model is trained exclusively on publicly available 3D datasets, achieving strong geometric quality despite limited training resources. Extensive evaluations demonstrate that UltraShape 1.0 performs competitively with existing open-source methods in both data processing quality and geometry generation. All code and trained models will be released to support future research.
Complex-Valued 2D Gaussian Representation for Computer-Generated Holography
Nov 19, 2025
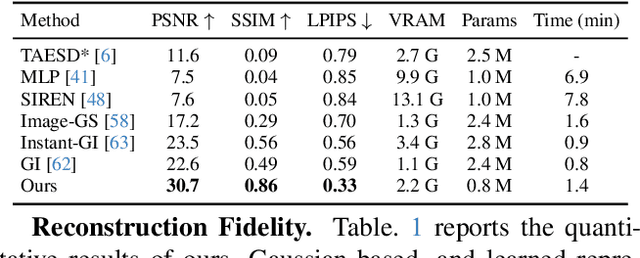

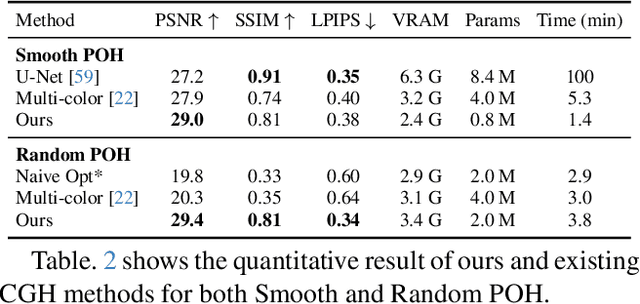
We propose a new hologram representation based on structured complex-valued 2D Gaussian primitives, which replaces per-pixel information storage and reduces the parameter search space by up to 10:1. To enable end-to-end training, we develop a differentiable rasterizer for our representation, integrated with a GPU-optimized light propagation kernel in free space. Our extensive experiments show that our method achieves up to 2.5x lower VRAM usage and 50% faster optimization while producing higher-fidelity reconstructions than existing methods. We further introduce a conversion procedure that adapts our representation to practical hologram formats, including smooth and random phase-only holograms. Our experiments show that this procedure can effectively suppress noise artifacts observed in previous methods. By reducing the hologram parameter search space, our representation enables a more scalable hologram estimation in the next-generation computer-generated holography systems.
Matrix3D: Large Photogrammetry Model All-in-One
Feb 11, 2025We present Matrix3D, a unified model that performs several photogrammetry subtasks, including pose estimation, depth prediction, and novel view synthesis using just the same model. Matrix3D utilizes a multi-modal diffusion transformer (DiT) to integrate transformations across several modalities, such as images, camera parameters, and depth maps. The key to Matrix3D's large-scale multi-modal training lies in the incorporation of a mask learning strategy. This enables full-modality model training even with partially complete data, such as bi-modality data of image-pose and image-depth pairs, thus significantly increases the pool of available training data. Matrix3D demonstrates state-of-the-art performance in pose estimation and novel view synthesis tasks. Additionally, it offers fine-grained control through multi-round interactions, making it an innovative tool for 3D content creation. Project page: https://nju-3dv.github.io/projects/matrix3d.
DepthCrafter: Generating Consistent Long Depth Sequences for Open-world Videos
Sep 03, 2024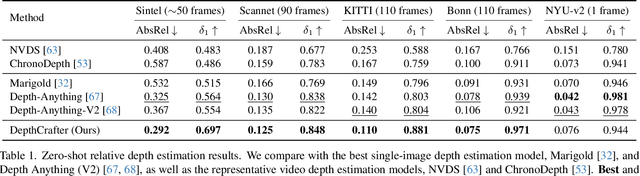
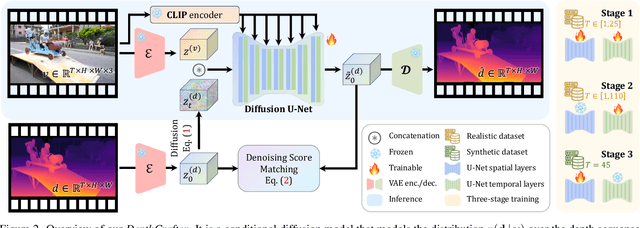
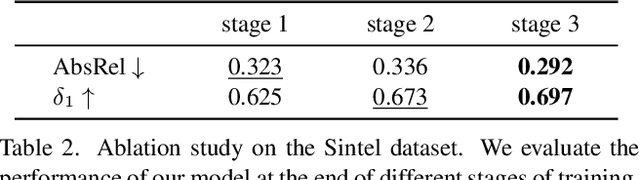
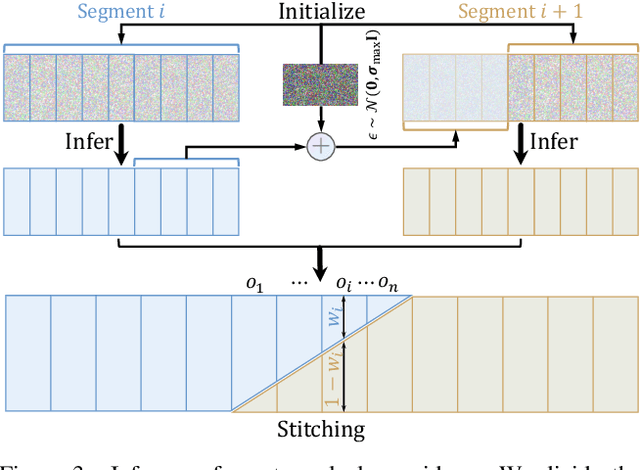
Despite significant advancements in monocular depth estimation for static images, estimating video depth in the open world remains challenging, since open-world videos are extremely diverse in content, motion, camera movement, and length. We present DepthCrafter, an innovative method for generating temporally consistent long depth sequences with intricate details for open-world videos, without requiring any supplementary information such as camera poses or optical flow. DepthCrafter achieves generalization ability to open-world videos by training a video-to-depth model from a pre-trained image-to-video diffusion model, through our meticulously designed three-stage training strategy with the compiled paired video-depth datasets. Our training approach enables the model to generate depth sequences with variable lengths at one time, up to 110 frames, and harvest both precise depth details and rich content diversity from realistic and synthetic datasets. We also propose an inference strategy that processes extremely long videos through segment-wise estimation and seamless stitching. Comprehensive evaluations on multiple datasets reveal that DepthCrafter achieves state-of-the-art performance in open-world video depth estimation under zero-shot settings. Furthermore, DepthCrafter facilitates various downstream applications, including depth-based visual effects and conditional video generation.
Mani-GS: Gaussian Splatting Manipulation with Triangular Mesh
May 28, 2024Neural 3D representations such as Neural Radiance Fields (NeRF), excel at producing photo-realistic rendering results but lack the flexibility for manipulation and editing which is crucial for content creation. Previous works have attempted to address this issue by deforming a NeRF in canonical space or manipulating the radiance field based on an explicit mesh. However, manipulating NeRF is not highly controllable and requires a long training and inference time. With the emergence of 3D Gaussian Splatting (3DGS), extremely high-fidelity novel view synthesis can be achieved using an explicit point-based 3D representation with much faster training and rendering speed. However, there is still a lack of effective means to manipulate 3DGS freely while maintaining rendering quality. In this work, we aim to tackle the challenge of achieving manipulable photo-realistic rendering. We propose to utilize a triangular mesh to manipulate 3DGS directly with self-adaptation. This approach reduces the need to design various algorithms for different types of Gaussian manipulation. By utilizing a triangle shape-aware Gaussian binding and adapting method, we can achieve 3DGS manipulation and preserve high-fidelity rendering after manipulation. Our approach is capable of handling large deformations, local manipulations, and soft body simulations while keeping high-quality rendering. Furthermore, we demonstrate that our method is also effective with inaccurate meshes extracted from 3DGS. Experiments conducted demonstrate the effectiveness of our method and its superiority over baseline approaches.
Affine-based Deformable Attention and Selective Fusion for Semi-dense Matching
May 22, 2024



Identifying robust and accurate correspondences across images is a fundamental problem in computer vision that enables various downstream tasks. Recent semi-dense matching methods emphasize the effectiveness of fusing relevant cross-view information through Transformer. In this paper, we propose several improvements upon this paradigm. Firstly, we introduce affine-based local attention to model cross-view deformations. Secondly, we present selective fusion to merge local and global messages from cross attention. Apart from network structure, we also identify the importance of enforcing spatial smoothness in loss design, which has been omitted by previous works. Based on these augmentations, our network demonstrate strong matching capacity under different settings. The full version of our network achieves state-of-the-art performance among semi-dense matching methods at a similar cost to LoFTR, while the slim version reaches LoFTR baseline's performance with only 15% computation cost and 18% parameters.
ConTex-Human: Free-View Rendering of Human from a Single Image with Texture-Consistent Synthesis
Nov 28, 2023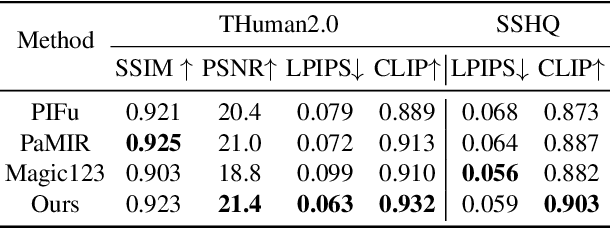

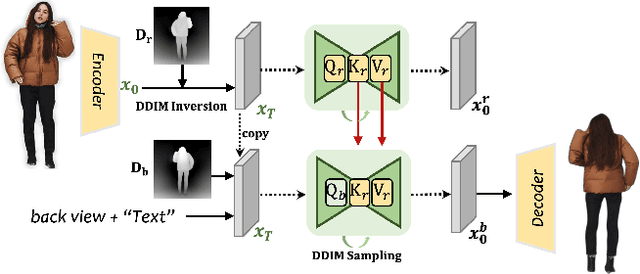
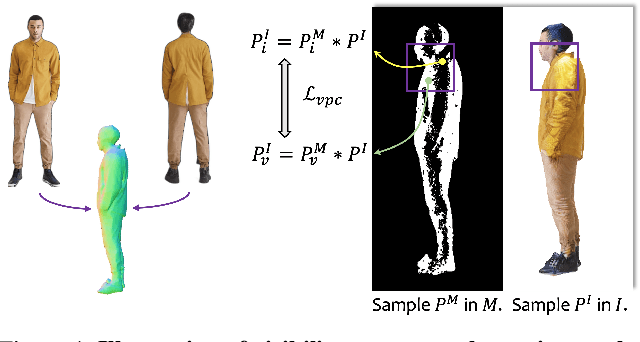
In this work, we propose a method to address the challenge of rendering a 3D human from a single image in a free-view manner. Some existing approaches could achieve this by using generalizable pixel-aligned implicit fields to reconstruct a textured mesh of a human or by employing a 2D diffusion model as guidance with the Score Distillation Sampling (SDS) method, to lift the 2D image into 3D space. However, a generalizable implicit field often results in an over-smooth texture field, while the SDS method tends to lead to a texture-inconsistent novel view with the input image. In this paper, we introduce a texture-consistent back view synthesis module that could transfer the reference image content to the back view through depth and text-guided attention injection. Moreover, to alleviate the color distortion that occurs in the side region, we propose a visibility-aware patch consistency regularization for texture mapping and refinement combined with the synthesized back view texture. With the above techniques, we could achieve high-fidelity and texture-consistent human rendering from a single image. Experiments conducted on both real and synthetic data demonstrate the effectiveness of our method and show that our approach outperforms previous baseline methods.
Direct2.5: Diverse Text-to-3D Generation via Multi-view 2.5D Diffusion
Nov 27, 2023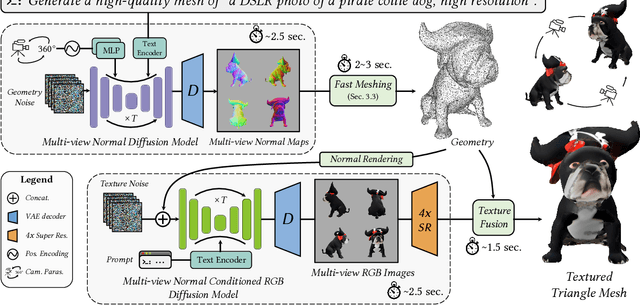



Recent advances in generative AI have unveiled significant potential for the creation of 3D content. However, current methods either apply a pre-trained 2D diffusion model with the time-consuming score distillation sampling (SDS), or a direct 3D diffusion model trained on limited 3D data losing generation diversity. In this work, we approach the problem by employing a multi-view 2.5D diffusion fine-tuned from a pre-trained 2D diffusion model. The multi-view 2.5D diffusion directly models the structural distribution of 3D data, while still maintaining the strong generalization ability of the original 2D diffusion model, filling the gap between 2D diffusion-based and direct 3D diffusion-based methods for 3D content generation. During inference, multi-view normal maps are generated using the 2.5D diffusion, and a novel differentiable rasterization scheme is introduced to fuse the almost consistent multi-view normal maps into a consistent 3D model. We further design a normal-conditioned multi-view image generation module for fast appearance generation given the 3D geometry. Our method is a one-pass diffusion process and does not require any SDS optimization as post-processing. We demonstrate through extensive experiments that, our direct 2.5D generation with the specially-designed fusion scheme can achieve diverse, mode-seeking-free, and high-fidelity 3D content generation in only 10 seconds. Project page: https://nju-3dv.github.io/projects/direct25.
JointNet: Extending Text-to-Image Diffusion for Dense Distribution Modeling
Oct 10, 2023


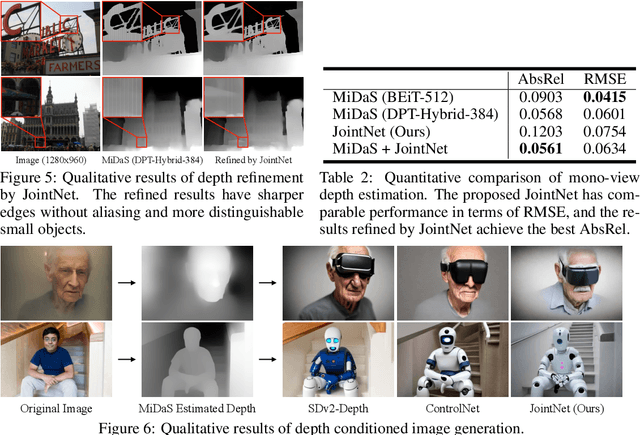
We introduce JointNet, a novel neural network architecture for modeling the joint distribution of images and an additional dense modality (e.g., depth maps). JointNet is extended from a pre-trained text-to-image diffusion model, where a copy of the original network is created for the new dense modality branch and is densely connected with the RGB branch. The RGB branch is locked during network fine-tuning, which enables efficient learning of the new modality distribution while maintaining the strong generalization ability of the large-scale pre-trained diffusion model. We demonstrate the effectiveness of JointNet by using RGBD diffusion as an example and through extensive experiments, showcasing its applicability in a variety of applications, including joint RGBD generation, dense depth prediction, depth-conditioned image generation, and coherent tile-based 3D panorama generation.