 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Monocular View Synthesis in Less Than a Second
Dec 11, 2025We present SHARP, an approach to photorealistic view synthesis from a single image. Given a single photograph, SHARP regresses the parameters of a 3D Gaussian representation of the depicted scene. This is done in less than a second on a standard GPU via a single feedforward pass through a neural network. The 3D Gaussian representation produced by SHARP can then be rendered in real time, yielding high-resolution photorealistic images for nearby views. The representation is metric, with absolute scale, supporting metric camera movements. Experimental results demonstrate that SHARP delivers robust zero-shot generalization across datasets. It sets a new state of the art on multiple datasets, reducing LPIPS by 25-34% and DISTS by 21-43% versus the best prior model, while lowering the synthesis time by three orders of magnitude. Code and weights are provided at https://github.com/apple/ml-sharp
Affine-based Deformable Attention and Selective Fusion for Semi-dense Matching
May 22, 2024



Identifying robust and accurate correspondences across images is a fundamental problem in computer vision that enables various downstream tasks. Recent semi-dense matching methods emphasize the effectiveness of fusing relevant cross-view information through Transformer. In this paper, we propose several improvements upon this paradigm. Firstly, we introduce affine-based local attention to model cross-view deformations. Secondly, we present selective fusion to merge local and global messages from cross attention. Apart from network structure, we also identify the importance of enforcing spatial smoothness in loss design, which has been omitted by previous works. Based on these augmentations, our network demonstrate strong matching capacity under different settings. The full version of our network achieves state-of-the-art performance among semi-dense matching methods at a similar cost to LoFTR, while the slim version reaches LoFTR baseline's performance with only 15% computation cost and 18% parameters.
ASpanFormer: Detector-Free Image Matching with Adaptive Span Transformer
Aug 30, 2022
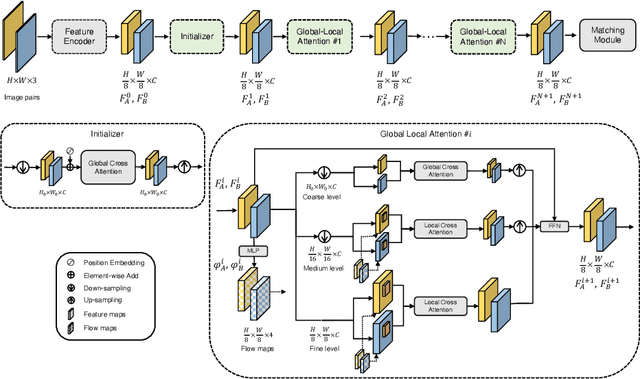
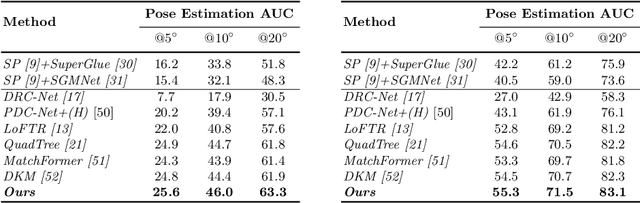

Generating robust and reliable correspondences across images is a fundamental task for a diversity of applications. To capture context at both global and local granularity, we propose ASpanFormer, a Transformer-based detector-free matcher that is built on hierarchical attention structure, adopting a novel attention operation which is capable of adjusting attention span in a self-adaptive manner. To achieve this goal, first, flow maps are regressed in each cross attention phase to locate the center of search region. Next, a sampling grid is generated around the center, whose size, instead of being empirically configured as fixed, is adaptively computed from a pixel uncertainty estimated along with the flow map. Finally, attention is computed across two images within derived regions, referred to as attention span. By these means, we are able to not only maintain long-range dependencies, but also enable fine-grained attention among pixels of high relevance that compensates essential locality and piece-wise smoothness in matching tasks. State-of-the-art accuracy on a wide range of evaluation benchmarks validates the strong matching capability of our method.
Learning Discriminative Feature with CRF for Unsupervised Video Object Segmentation
Aug 04, 2020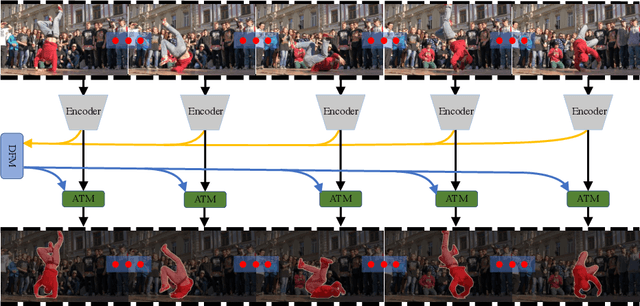
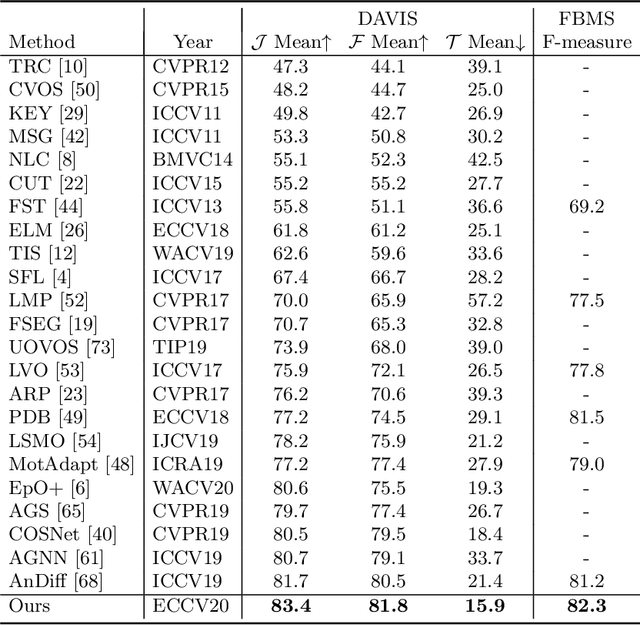
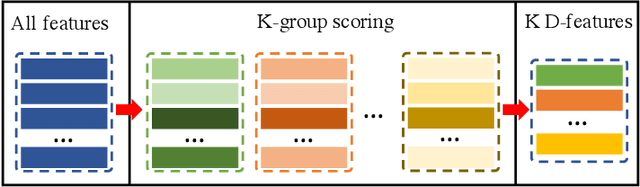
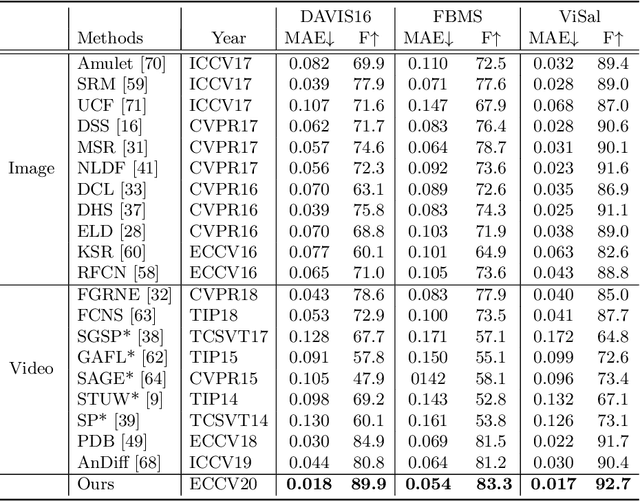
In this paper, we introduce a novel network, called discriminative feature network (DFNet), to address the unsupervised video object segmentation task. To capture the inherent correlation among video frames, we learn discriminative features (D-features) from the input images that reveal feature distribution from a global perspective. The D-features are then used to establish correspondence with all features of test image under conditional random field (CRF) formulation, which is leveraged to enforce consistency between pixels. The experiments verify that DFNet outperforms state-of-the-art methods by a large margin with a mean IoU score of 83.4% and ranks first on the DAVIS-2016 leaderboard while using much fewer parameters and achieving much more efficient performance in the inference phase. We further evaluate DFNet on the FBMS dataset and the video saliency dataset ViSal, reaching a new state-of-the-art. To further demonstrate the generalizability of our framework, DFNet is also applied to the image object co-segmentation task. We perform experiments on a challenging dataset PASCAL-VOC and observe the superiority of DFNet. The thorough experiments verify that DFNet is able to capture and mine the underlying relations of images and discover the common foreground objects.
Stochastic Bundle Adjustment for Efficient and Scalable 3D Reconstruction
Aug 02, 2020
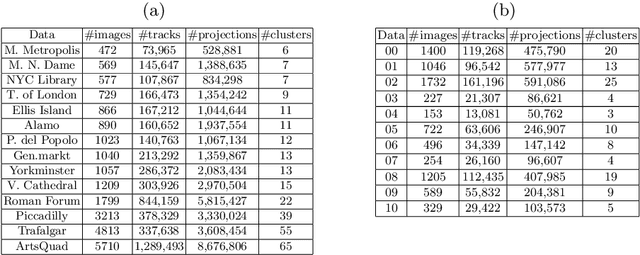


Current bundle adjustment solvers such as the Levenberg-Marquardt (LM) algorithm are limited by the bottleneck in solving the Reduced Camera System (RCS) whose dimension is proportional to the camera number. When the problem is scaled up, this step is neither efficient in computation nor manageable for a single compute node. In this work, we propose a stochastic bundle adjustment algorithm which seeks to decompose the RCS approximately inside the LM iterations to improve the efficiency and scalability. It first reformulates the quadratic programming problem of an LM iteration based on the clustering of the visibility graph by introducing the equality constraints across clusters. Then, we propose to relax it into a chance constrained problem and solve it through sampled convex program. The relaxation is intended to eliminate the interdependence between clusters embodied by the constraints, so that a large RCS can be decomposed into independent linear sub-problems. Numerical experiments on unordered Internet image sets and sequential SLAM image sets, as well as distributed experiments on large-scale datasets, have demonstrated the high efficiency and scalability of the proposed approach. Codes are released at https://github.com/zlthinker/STBA.
Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency
Jul 24, 2020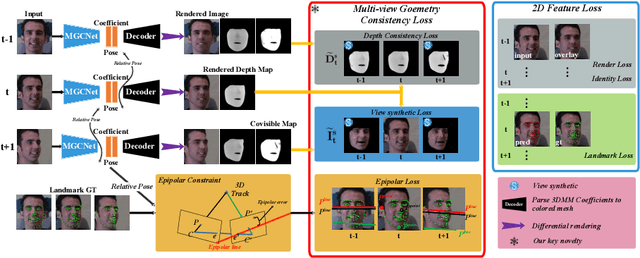
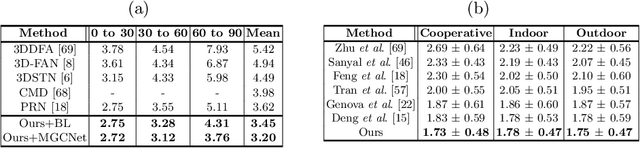

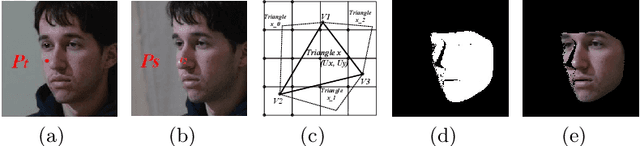
Recent learning-based approaches, in which models are trained by single-view images have shown promising results for monocular 3D face reconstruction, but they suffer from the ill-posed face pose and depth ambiguity issue. In contrast to previous works that only enforce 2D feature constraints, we propose a self-supervised training architecture by leveraging the multi-view geometry consistency, which provides reliable constraints on face pose and depth estimation. We first propose an occlusion-aware view synthesis method to apply multi-view geometry consistency to self-supervised learning. Then we design three novel loss functions for multi-view consistency, including the pixel consistency loss, the depth consistency loss, and the facial landmark-based epipolar loss. Our method is accurate and robust, especially under large variations of expressions, poses, and illumination conditions. Comprehensive experiments on the face alignment and 3D face reconstruction benchmarks have demonstrated superiority over state-of-the-art methods. Our code and model are released in https://github.com/jiaxiangshang/MGCNet.
JSENet: Joint Semantic Segmentation and Edge Detection Network for 3D Point Clouds
Jul 14, 2020


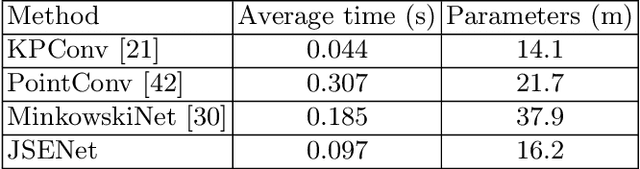
Semantic segmentation and semantic edge detection can be seen as two dual problems with close relationships in computer vision. Despite the fast evolution of learning-based 3D semantic segmentation methods, little attention has been drawn to the learning of 3D semantic edge detectors, even less to a joint learning method for the two tasks. In this paper, we tackle the 3D semantic edge detection task for the first time and present a new two-stream fully-convolutional network that jointly performs the two tasks. In particular, we design a joint refinement module that explicitly wires region information and edge information to improve the performances of both tasks. Further, we propose a novel loss function that encourages the network to produce semantic segmentation results with better boundaries. Extensive evaluations on S3DIS and ScanNet datasets show that our method achieves on par or better performance than the state-of-the-art methods for semantic segmentation and outperforms the baseline methods for semantic edge detection. Code release: https://github.com/hzykent/JSENet
Joint Semantic Segmentation and Boundary Detection using Iterative Pyramid Contexts
Apr 16, 2020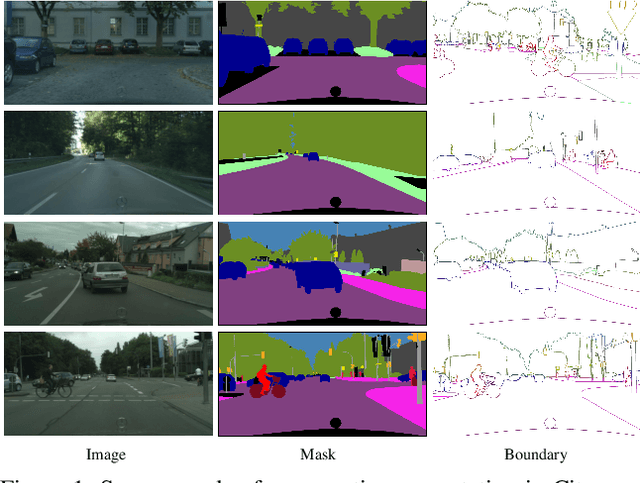
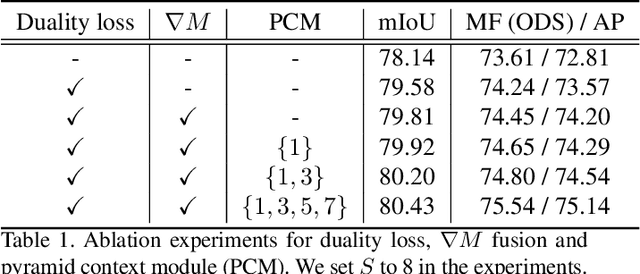
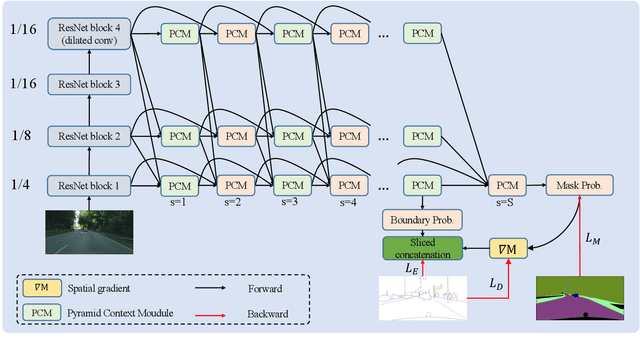
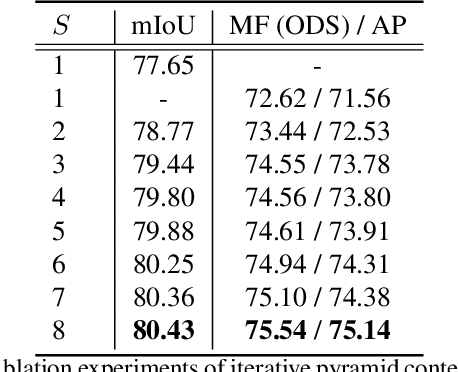
In this paper, we present a joint multi-task learning framework for semantic segmentation and boundary detection. The critical component in the framework is the iterative pyramid context module (PCM), which couples two tasks and stores the shared latent semantics to interact between the two tasks. For semantic boundary detection, we propose the novel spatial gradient fusion to suppress nonsemantic edges. As semantic boundary detection is the dual task of semantic segmentation, we introduce a loss function with boundary consistency constraint to improve the boundary pixel accuracy for semantic segmentation. Our extensive experiments demonstrate superior performance over state-of-the-art works, not only in semantic segmentation but also in semantic boundary detection. In particular, a mean IoU score of 81:8% on Cityscapes test set is achieved without using coarse data or any external data for semantic segmentation. For semantic boundary detection, we improve over previous state-of-the-art works by 9.9% in terms of AP and 6:8% in terms of MF(ODS).
KFNet: Learning Temporal Camera Relocalization using Kalman Filtering
Mar 24, 2020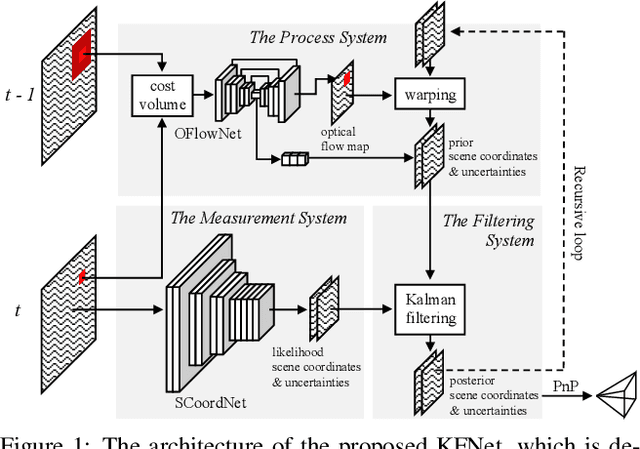

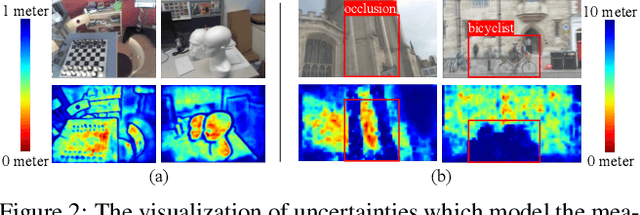

Temporal camera relocalization estimates the pose with respect to each video frame in sequence, as opposed to one-shot relocalization which focuses on a still image. Even though the time dependency has been taken into account, current temporal relocalization methods still generally underperform the state-of-the-art one-shot approaches in terms of accuracy. In this work, we improve the temporal relocalization method by using a network architecture that incorporates Kalman filtering (KFNet) for online camera relocalization. In particular, KFNet extends the scene coordinate regression problem to the time domain in order to recursively establish 2D and 3D correspondences for the pose determination. The network architecture design and the loss formulation are based on Kalman filtering in the context of Bayesian learning. Extensive experiments on multiple relocalization benchmarks demonstrate the high accuracy of KFNet at the top of both one-shot and temporal relocalization approaches. Our codes are released at https://github.com/zlthinker/KFNet.
Learning Fully Dense Neural Networks for Image Semantic Segmentation
May 22, 2019



Semantic segmentation is pixel-wise classification which retains critical spatial information. The "feature map reuse" has been commonly adopted in CNN based approaches to take advantage of feature maps in the early layers for the later spatial reconstruction. Along this direction, we go a step further by proposing a fully dense neural network with an encoder-decoder structure that we abbreviate as FDNet. For each stage in the decoder module, feature maps of all the previous blocks are adaptively aggregated to feed-forward as input. On the one hand, it reconstructs the spatial boundaries accurately. On the other hand, it learns more efficiently with the more efficient gradient backpropagation. In addition, we propose the boundary-aware loss function to focus more attention on the pixels near the boundary, which boosts the "hard examples" labeling. We have demonstrated the best performance of the FDNet on the two benchmark datasets: PASCAL VOC 2012, NYUDv2 over previous works when not considering training on other datasets.