 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSASNet: Spatially-Adaptive Sinusoidal Neural Networks
Mar 12, 2025Sinusoidal neural networks (SNNs) have emerged as powerful implicit neural representations (INRs) for low-dimensional signals in computer vision and graphics. They enable high-frequency signal reconstruction and smooth manifold modeling; however, they often suffer from spectral bias, training instability, and overfitting. To address these challenges, we propose SASNet, Spatially-Adaptive SNNs that robustly enhance the capacity of compact INRs to fit detailed signals. SASNet integrates a frequency embedding layer to control frequency components and mitigate spectral bias, along with jointly optimized, spatially-adaptive masks that localize neuron influence, reducing network redundancy and improving convergence stability. Robust to hyperparameter selection, SASNet faithfully reconstructs high-frequency signals without overfitting low-frequency regions. Our experiments show that SASNet outperforms state-of-the-art INRs, achieving strong fitting accuracy, super-resolution capability, and noise suppression, without sacrificing model compactness.
Critical Features Tracking on Triangulated Irregular Networks by a Scale-Space Method
Sep 10, 2024The scale-space method is a well-established framework that constructs a hierarchical representation of an input signal and facilitates coarse-to-fine visual reasoning. Considering the terrain elevation function as the input signal, the scale-space method can identify and track significant topographic features across different scales. The number of scales a feature persists, called its life span, indicates the importance of that feature. In this way, important topographic features of a landscape can be selected, which are useful for many applications, including cartography, nautical charting, and land-use planning. The scale-space methods developed for terrain data use gridded Digital Elevation Models (DEMs) to represent the terrain. However, gridded DEMs lack the flexibility to adapt to the irregular distribution of input data and the varied topological complexity of different regions. Instead, Triangulated Irregular Networks (TINs) can be directly generated from irregularly distributed point clouds and accurately preserve important features. In this work, we introduce a novel scale-space analysis pipeline for TINs, addressing the multiple challenges in extending grid-based scale-space methods to TINs. Our pipeline can efficiently identify and track topologically important features on TINs. Moreover, it is capable of analyzing terrains with irregular boundaries, which poses challenges for grid-based methods. Comprehensive experiments show that, compared to grid-based methods, our TIN-based pipeline is more efficient, accurate, and has better resolution robustness.
ImplicitTerrain: a Continuous Surface Model for Terrain Data Analysis
May 31, 2024Digital terrain models (DTMs) are pivotal in remote sensing, cartography, and landscape management, requiring accurate surface representation and topological information restoration. While topology analysis traditionally relies on smooth manifolds, the absence of an easy-to-use continuous surface model for a large terrain results in a preference for discrete meshes. Structural representation based on topology provides a succinct surface description, laying the foundation for many terrain analysis applications. However, on discrete meshes, numerical issues emerge, and complex algorithms are designed to handle them. This paper brings the context of terrain data analysis back to the continuous world and introduces ImplicitTerrain (Project homepage available at https://fengyee.github.io/implicit-terrain/), an implicit neural representation (INR) approach for modeling high-resolution terrain continuously and differentiably. Our comprehensive experiments demonstrate superior surface fitting accuracy, effective topological feature retrieval, and various topographical feature extraction that are implemented over this compact representation in parallel. To our knowledge, ImplicitTerrain pioneers a feasible continuous terrain surface modeling pipeline that provides a new research avenue for our community.
Learning Discriminative Feature with CRF for Unsupervised Video Object Segmentation
Aug 04, 2020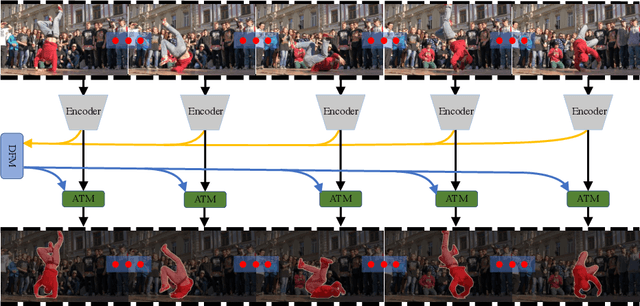
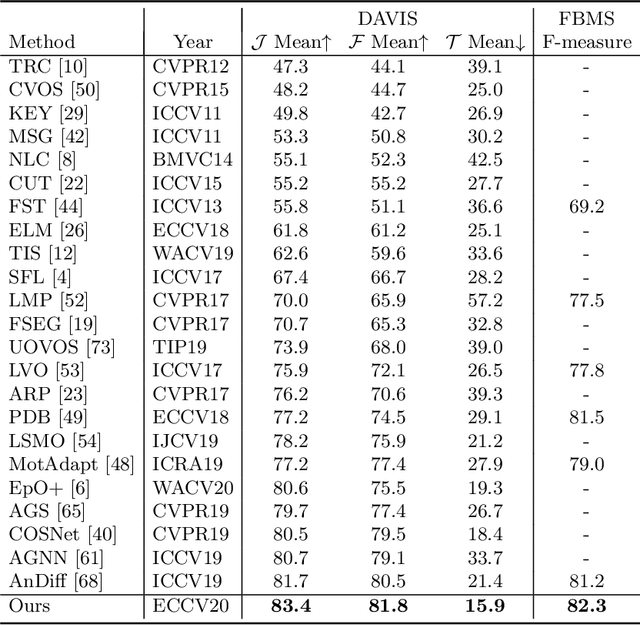
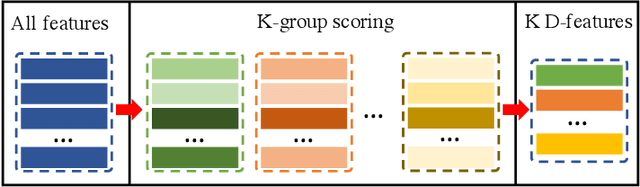
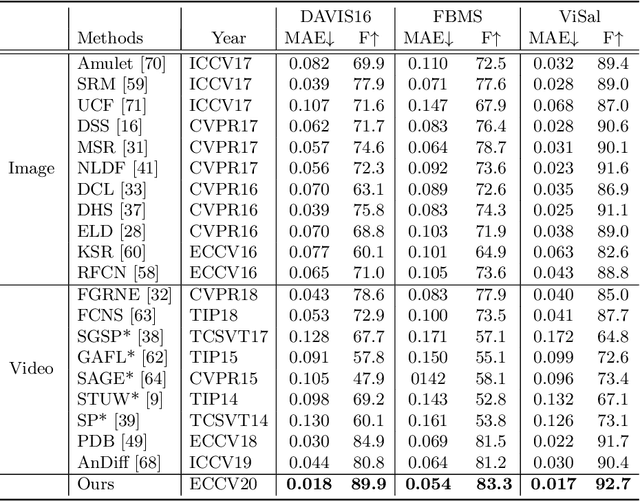
In this paper, we introduce a novel network, called discriminative feature network (DFNet), to address the unsupervised video object segmentation task. To capture the inherent correlation among video frames, we learn discriminative features (D-features) from the input images that reveal feature distribution from a global perspective. The D-features are then used to establish correspondence with all features of test image under conditional random field (CRF) formulation, which is leveraged to enforce consistency between pixels. The experiments verify that DFNet outperforms state-of-the-art methods by a large margin with a mean IoU score of 83.4% and ranks first on the DAVIS-2016 leaderboard while using much fewer parameters and achieving much more efficient performance in the inference phase. We further evaluate DFNet on the FBMS dataset and the video saliency dataset ViSal, reaching a new state-of-the-art. To further demonstrate the generalizability of our framework, DFNet is also applied to the image object co-segmentation task. We perform experiments on a challenging dataset PASCAL-VOC and observe the superiority of DFNet. The thorough experiments verify that DFNet is able to capture and mine the underlying relations of images and discover the common foreground objects.