 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSonata: Self-Supervised Learning of Reliable Point Representations
Mar 20, 2025In this paper, we question whether we have a reliable self-supervised point cloud model that can be used for diverse 3D tasks via simple linear probing, even with limited data and minimal computation. We find that existing 3D self-supervised learning approaches fall short when evaluated on representation quality through linear probing. We hypothesize that this is due to what we term the "geometric shortcut", which causes representations to collapse to low-level spatial features. This challenge is unique to 3D and arises from the sparse nature of point cloud data. We address it through two key strategies: obscuring spatial information and enhancing the reliance on input features, ultimately composing a Sonata of 140k point clouds through self-distillation. Sonata is simple and intuitive, yet its learned representations are strong and reliable: zero-shot visualizations demonstrate semantic grouping, alongside strong spatial reasoning through nearest-neighbor relationships. Sonata demonstrates exceptional parameter and data efficiency, tripling linear probing accuracy (from 21.8% to 72.5%) on ScanNet and nearly doubling performance with only 1% of the data compared to previous approaches. Full fine-tuning further advances SOTA across both 3D indoor and outdoor perception tasks.
EFM3D: A Benchmark for Measuring Progress Towards 3D Egocentric Foundation Models
Jun 14, 2024



The advent of wearable computers enables a new source of context for AI that is embedded in egocentric sensor data. This new egocentric data comes equipped with fine-grained 3D location information and thus presents the opportunity for a novel class of spatial foundation models that are rooted in 3D space. To measure progress on what we term Egocentric Foundation Models (EFMs) we establish EFM3D, a benchmark with two core 3D egocentric perception tasks. EFM3D is the first benchmark for 3D object detection and surface regression on high quality annotated egocentric data of Project Aria. We propose Egocentric Voxel Lifting (EVL), a baseline for 3D EFMs. EVL leverages all available egocentric modalities and inherits foundational capabilities from 2D foundation models. This model, trained on a large simulated dataset, outperforms existing methods on the EFM3D benchmark.
Nerfels: Renderable Neural Codes for Improved Camera Pose Estimation
Jun 04, 2022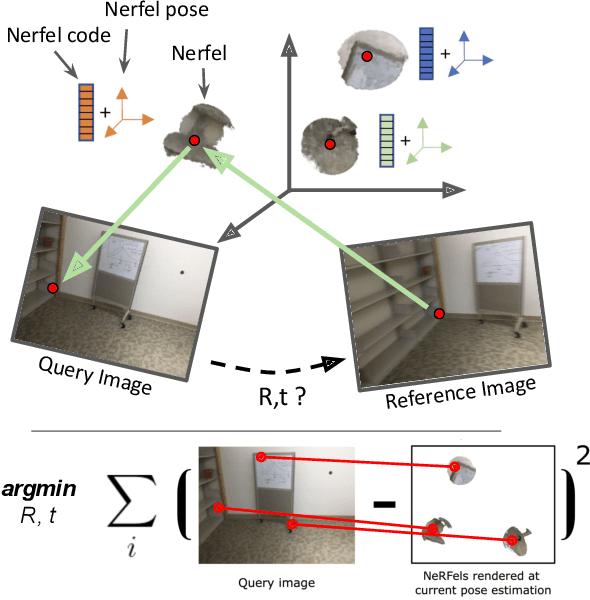
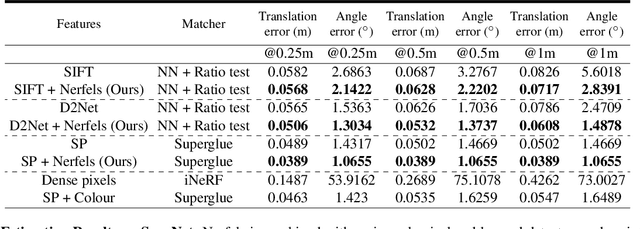


This paper presents a framework that combines traditional keypoint-based camera pose optimization with an invertible neural rendering mechanism. Our proposed 3D scene representation, Nerfels, is locally dense yet globally sparse. As opposed to existing invertible neural rendering systems which overfit a model to the entire scene, we adopt a feature-driven approach for representing scene-agnostic, local 3D patches with renderable codes. By modelling a scene only where local features are detected, our framework effectively generalizes to unseen local regions in the scene via an optimizable code conditioning mechanism in the neural renderer, all while maintaining the low memory footprint of a sparse 3D map representation. Our model can be incorporated to existing state-of-the-art hand-crafted and learned local feature pose estimators, yielding improved performance when evaluating on ScanNet for wide camera baseline scenarios.
NinjaDesc: Content-Concealing Visual Descriptors via Adversarial Learning
Dec 23, 2021

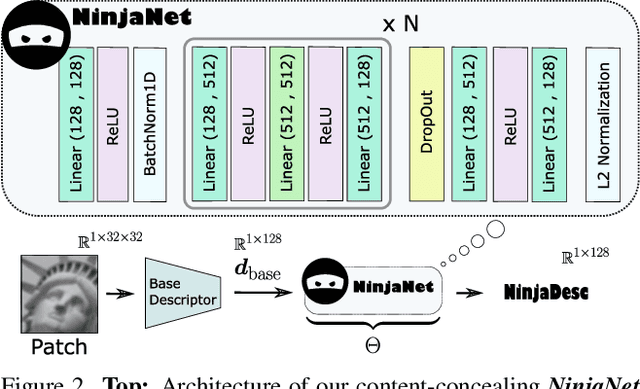
In the light of recent analyses on privacy-concerning scene revelation from visual descriptors, we develop descriptors that conceal the input image content. In particular, we propose an adversarial learning framework for training visual descriptors that prevent image reconstruction, while maintaining the matching accuracy. We let a feature encoding network and image reconstruction network compete with each other, such that the feature encoder tries to impede the image reconstruction with its generated descriptors, while the reconstructor tries to recover the input image from the descriptors. The experimental results demonstrate that the visual descriptors obtained with our method significantly deteriorate the image reconstruction quality with minimal impact on correspondence matching and camera localization performance.
Analysis and Mitigations of Reverse Engineering Attacks on Local Feature Descriptors
May 09, 2021
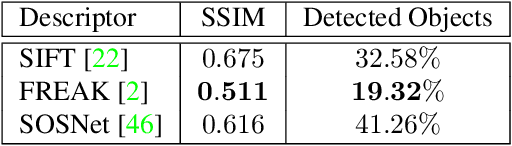
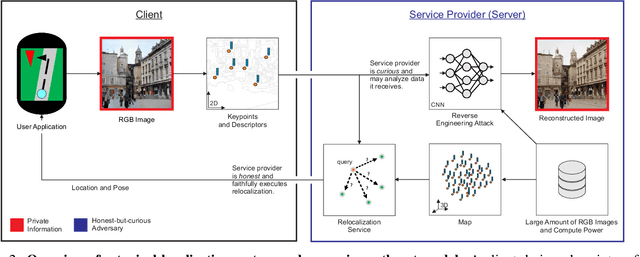
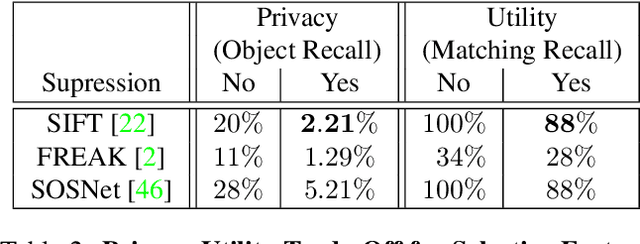
As autonomous driving and augmented reality evolve, a practical concern is data privacy. In particular, these applications rely on localization based on user images. The widely adopted technology uses local feature descriptors, which are derived from the images and it was long thought that they could not be reverted back. However, recent work has demonstrated that under certain conditions reverse engineering attacks are possible and allow an adversary to reconstruct RGB images. This poses a potential risk to user privacy. We take this a step further and model potential adversaries using a privacy threat model. Subsequently, we show under controlled conditions a reverse engineering attack on sparse feature maps and analyze the vulnerability of popular descriptors including FREAK, SIFT and SOSNet. Finally, we evaluate potential mitigation techniques that select a subset of descriptors to carefully balance privacy reconstruction risk while preserving image matching accuracy; our results show that similar accuracy can be obtained when revealing less information.
Domain Adaptation of Learned Features for Visual Localization
Aug 21, 2020


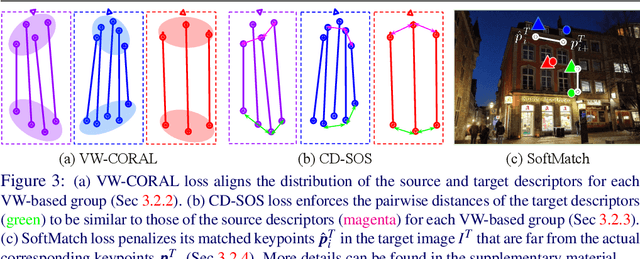
We tackle the problem of visual localization under changing conditions, such as time of day, weather, and seasons. Recent learned local features based on deep neural networks have shown superior performance over classical hand-crafted local features. However, in a real-world scenario, there often exists a large domain gap between training and target images, which can significantly degrade the localization accuracy. While existing methods utilize a large amount of data to tackle the problem, we present a novel and practical approach, where only a few examples are needed to reduce the domain gap. In particular, we propose a few-shot domain adaptation framework for learned local features that deals with varying conditions in visual localization. The experimental results demonstrate the superior performance over baselines, while using a scarce number of training examples from the target domain.
Learning Stereo Matchability in Disparity Regression Networks
Aug 11, 2020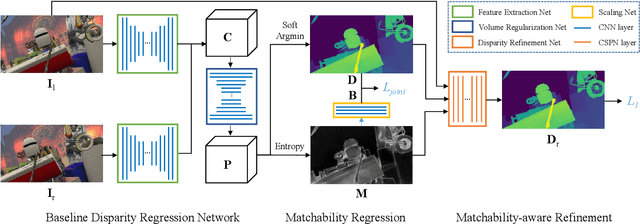



Learning-based stereo matching has recently achieved promising results, yet still suffers difficulties in establishing reliable matches in weakly matchable regions that are textureless, non-Lambertian, or occluded. In this paper, we address this challenge by proposing a stereo matching network that considers pixel-wise matchability. Specifically, the network jointly regresses disparity and matchability maps from 3D probability volume through expectation and entropy operations. Next, a learned attenuation is applied as the robust loss function to alleviate the influence of weakly matchable pixels in the training. Finally, a matchability-aware disparity refinement is introduced to improve the depth inference in weakly matchable regions. The proposed deep stereo matchability (DSM) framework can improve the matching result or accelerate the computation while still guaranteeing the quality. Moreover, the DSM framework is portable to many recent stereo networks. Extensive experiments are conducted on Scene Flow and KITTI stereo datasets to demonstrate the effectiveness of the proposed framework over the state-of-the-art learning-based stereo methods.
Stochastic Bundle Adjustment for Efficient and Scalable 3D Reconstruction
Aug 02, 2020
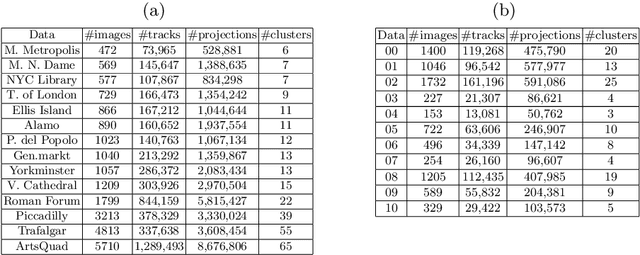


Current bundle adjustment solvers such as the Levenberg-Marquardt (LM) algorithm are limited by the bottleneck in solving the Reduced Camera System (RCS) whose dimension is proportional to the camera number. When the problem is scaled up, this step is neither efficient in computation nor manageable for a single compute node. In this work, we propose a stochastic bundle adjustment algorithm which seeks to decompose the RCS approximately inside the LM iterations to improve the efficiency and scalability. It first reformulates the quadratic programming problem of an LM iteration based on the clustering of the visibility graph by introducing the equality constraints across clusters. Then, we propose to relax it into a chance constrained problem and solve it through sampled convex program. The relaxation is intended to eliminate the interdependence between clusters embodied by the constraints, so that a large RCS can be decomposed into independent linear sub-problems. Numerical experiments on unordered Internet image sets and sequential SLAM image sets, as well as distributed experiments on large-scale datasets, have demonstrated the high efficiency and scalability of the proposed approach. Codes are released at https://github.com/zlthinker/STBA.
Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency
Jul 24, 2020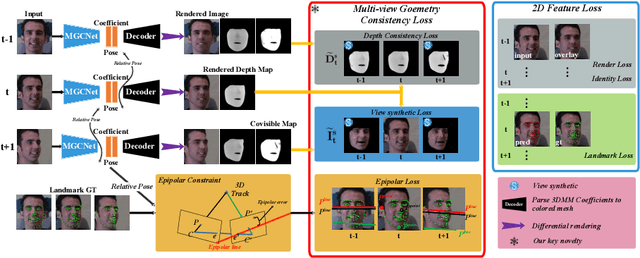
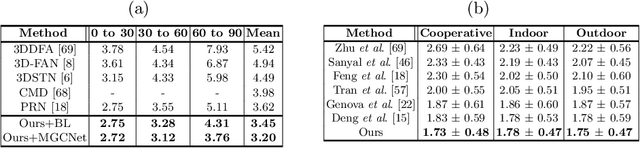

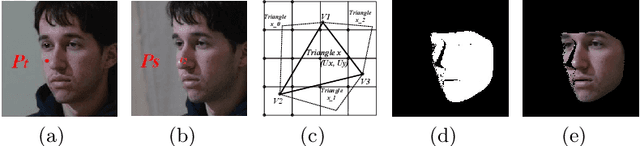
Recent learning-based approaches, in which models are trained by single-view images have shown promising results for monocular 3D face reconstruction, but they suffer from the ill-posed face pose and depth ambiguity issue. In contrast to previous works that only enforce 2D feature constraints, we propose a self-supervised training architecture by leveraging the multi-view geometry consistency, which provides reliable constraints on face pose and depth estimation. We first propose an occlusion-aware view synthesis method to apply multi-view geometry consistency to self-supervised learning. Then we design three novel loss functions for multi-view consistency, including the pixel consistency loss, the depth consistency loss, and the facial landmark-based epipolar loss. Our method is accurate and robust, especially under large variations of expressions, poses, and illumination conditions. Comprehensive experiments on the face alignment and 3D face reconstruction benchmarks have demonstrated superiority over state-of-the-art methods. Our code and model are released in https://github.com/jiaxiangshang/MGCNet.
Joint Semantic Segmentation and Boundary Detection using Iterative Pyramid Contexts
Apr 16, 2020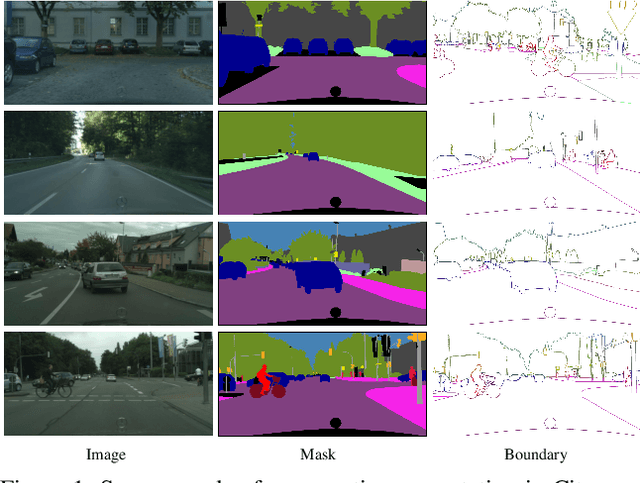
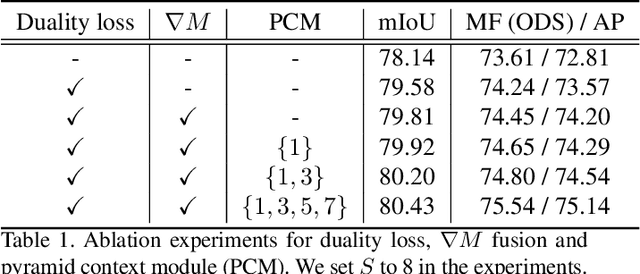
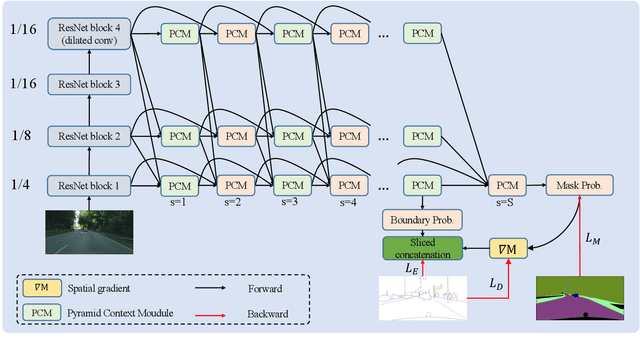
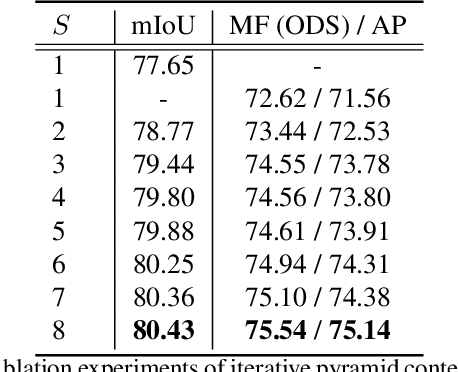
In this paper, we present a joint multi-task learning framework for semantic segmentation and boundary detection. The critical component in the framework is the iterative pyramid context module (PCM), which couples two tasks and stores the shared latent semantics to interact between the two tasks. For semantic boundary detection, we propose the novel spatial gradient fusion to suppress nonsemantic edges. As semantic boundary detection is the dual task of semantic segmentation, we introduce a loss function with boundary consistency constraint to improve the boundary pixel accuracy for semantic segmentation. Our extensive experiments demonstrate superior performance over state-of-the-art works, not only in semantic segmentation but also in semantic boundary detection. In particular, a mean IoU score of 81:8% on Cityscapes test set is achieved without using coarse data or any external data for semantic segmentation. For semantic boundary detection, we improve over previous state-of-the-art works by 9.9% in terms of AP and 6:8% in terms of MF(ODS).