 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReScene4D: Temporally Consistent Semantic Instance Segmentation of Evolving Indoor 3D Scenes
Jan 16, 2026Indoor environments evolve as objects move, appear, or disappear. Capturing these dynamics requires maintaining temporally consistent instance identities across intermittently captured 3D scans, even when changes are unobserved. We introduce and formalize the task of temporally sparse 4D indoor semantic instance segmentation (SIS), which jointly segments, identifies, and temporally associates object instances. This setting poses a challenge for existing 3DSIS methods, which require a discrete matching step due to their lack of temporal reasoning, and for 4D LiDAR approaches, which perform poorly due to their reliance on high-frequency temporal measurements that are uncommon in the longer-horizon evolution of indoor environments. We propose ReScene4D, a novel method that adapts 3DSIS architectures for 4DSIS without needing dense observations. It explores strategies to share information across observations, demonstrating that this shared context not only enables consistent instance tracking but also improves standard 3DSIS quality. To evaluate this task, we define a new metric, t-mAP, that extends mAP to reward temporal identity consistency. ReScene4D achieves state-of-the-art performance on the 3RScan dataset, establishing a new benchmark for understanding evolving indoor scenes.
VertexRegen: Mesh Generation with Continuous Level of Detail
Aug 12, 2025We introduce VertexRegen, a novel mesh generation framework that enables generation at a continuous level of detail. Existing autoregressive methods generate meshes in a partial-to-complete manner and thus intermediate steps of generation represent incomplete structures. VertexRegen takes inspiration from progressive meshes and reformulates the process as the reversal of edge collapse, i.e. vertex split, learned through a generative model. Experimental results demonstrate that VertexRegen produces meshes of comparable quality to state-of-the-art methods while uniquely offering anytime generation with the flexibility to halt at any step to yield valid meshes with varying levels of detail.
Sonata: Self-Supervised Learning of Reliable Point Representations
Mar 20, 2025In this paper, we question whether we have a reliable self-supervised point cloud model that can be used for diverse 3D tasks via simple linear probing, even with limited data and minimal computation. We find that existing 3D self-supervised learning approaches fall short when evaluated on representation quality through linear probing. We hypothesize that this is due to what we term the "geometric shortcut", which causes representations to collapse to low-level spatial features. This challenge is unique to 3D and arises from the sparse nature of point cloud data. We address it through two key strategies: obscuring spatial information and enhancing the reliance on input features, ultimately composing a Sonata of 140k point clouds through self-distillation. Sonata is simple and intuitive, yet its learned representations are strong and reliable: zero-shot visualizations demonstrate semantic grouping, alongside strong spatial reasoning through nearest-neighbor relationships. Sonata demonstrates exceptional parameter and data efficiency, tripling linear probing accuracy (from 21.8% to 72.5%) on ScanNet and nearly doubling performance with only 1% of the data compared to previous approaches. Full fine-tuning further advances SOTA across both 3D indoor and outdoor perception tasks.
ReplaceAnything3D:Text-Guided 3D Scene Editing with Compositional Neural Radiance Fields
Jan 31, 2024We introduce ReplaceAnything3D model (RAM3D), a novel text-guided 3D scene editing method that enables the replacement of specific objects within a scene. Given multi-view images of a scene, a text prompt describing the object to replace, and a text prompt describing the new object, our Erase-and-Replace approach can effectively swap objects in the scene with newly generated content while maintaining 3D consistency across multiple viewpoints. We demonstrate the versatility of ReplaceAnything3D by applying it to various realistic 3D scenes, showcasing results of modified foreground objects that are well-integrated with the rest of the scene without affecting its overall integrity.
Predicting Stable Configurations for Semantic Placement of Novel Objects
Aug 26, 2021

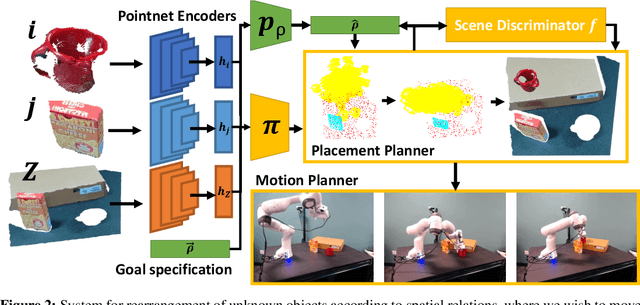
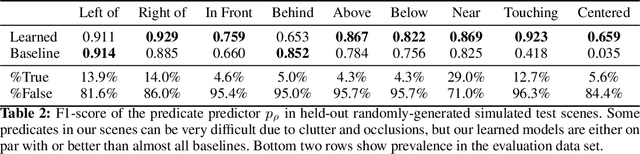
Human environments contain numerous objects configured in a variety of arrangements. Our goal is to enable robots to repose previously unseen objects according to learned semantic relationships in novel environments. We break this problem down into two parts: (1) finding physically valid locations for the objects and (2) determining if those poses satisfy learned, high-level semantic relationships. We build our models and training from the ground up to be tightly integrated with our proposed planning algorithm for semantic placement of unknown objects. We train our models purely in simulation, with no fine-tuning needed for use in the real world. Our approach enables motion planning for semantic rearrangement of unknown objects in scenes with varying geometry from only RGB-D sensing. Our experiments through a set of simulated ablations demonstrate that using a relational classifier alone is not sufficient for reliable planning. We further demonstrate the ability of our planner to generate and execute diverse manipulation plans through a set of real-world experiments with a variety of objects.