 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeR: Robust Conditional 3D Shape Generation from Casual Captures
Jan 16, 2026Recent advances in 3D shape generation have achieved impressive results, but most existing methods rely on clean, unoccluded, and well-segmented inputs. Such conditions are rarely met in real-world scenarios. We present ShapeR, a novel approach for conditional 3D object shape generation from casually captured sequences. Given an image sequence, we leverage off-the-shelf visual-inertial SLAM, 3D detection algorithms, and vision-language models to extract, for each object, a set of sparse SLAM points, posed multi-view images, and machine-generated captions. A rectified flow transformer trained to effectively condition on these modalities then generates high-fidelity metric 3D shapes. To ensure robustness to the challenges of casually captured data, we employ a range of techniques including on-the-fly compositional augmentations, a curriculum training scheme spanning object- and scene-level datasets, and strategies to handle background clutter. Additionally, we introduce a new evaluation benchmark comprising 178 in-the-wild objects across 7 real-world scenes with geometry annotations. Experiments show that ShapeR significantly outperforms existing approaches in this challenging setting, achieving an improvement of 2.7x in Chamfer distance compared to state of the art.
Monocular Online Reconstruction with Enhanced Detail Preservation
May 14, 2025We propose an online 3D Gaussian-based dense mapping framework for photorealistic details reconstruction from a monocular image stream. Our approach addresses two key challenges in monocular online reconstruction: distributing Gaussians without relying on depth maps and ensuring both local and global consistency in the reconstructed maps. To achieve this, we introduce two key modules: the Hierarchical Gaussian Management Module for effective Gaussian distribution and the Global Consistency Optimization Module for maintaining alignment and coherence at all scales. In addition, we present the Multi-level Occupancy Hash Voxels (MOHV), a structure that regularizes Gaussians for capturing details across multiple levels of granularity. MOHV ensures accurate reconstruction of both fine and coarse geometries and textures, preserving intricate details while maintaining overall structural integrity. Compared to state-of-the-art RGB-only and even RGB-D methods, our framework achieves superior reconstruction quality with high computational efficiency. Moreover, it integrates seamlessly with various tracking systems, ensuring generality and scalability.
Sonata: Self-Supervised Learning of Reliable Point Representations
Mar 20, 2025In this paper, we question whether we have a reliable self-supervised point cloud model that can be used for diverse 3D tasks via simple linear probing, even with limited data and minimal computation. We find that existing 3D self-supervised learning approaches fall short when evaluated on representation quality through linear probing. We hypothesize that this is due to what we term the "geometric shortcut", which causes representations to collapse to low-level spatial features. This challenge is unique to 3D and arises from the sparse nature of point cloud data. We address it through two key strategies: obscuring spatial information and enhancing the reliance on input features, ultimately composing a Sonata of 140k point clouds through self-distillation. Sonata is simple and intuitive, yet its learned representations are strong and reliable: zero-shot visualizations demonstrate semantic grouping, alongside strong spatial reasoning through nearest-neighbor relationships. Sonata demonstrates exceptional parameter and data efficiency, tripling linear probing accuracy (from 21.8% to 72.5%) on ScanNet and nearly doubling performance with only 1% of the data compared to previous approaches. Full fine-tuning further advances SOTA across both 3D indoor and outdoor perception tasks.
EgoLifter: Open-world 3D Segmentation for Egocentric Perception
Mar 26, 2024In this paper we present EgoLifter, a novel system that can automatically segment scenes captured from egocentric sensors into a complete decomposition of individual 3D objects. The system is specifically designed for egocentric data where scenes contain hundreds of objects captured from natural (non-scanning) motion. EgoLifter adopts 3D Gaussians as the underlying representation of 3D scenes and objects and uses segmentation masks from the Segment Anything Model (SAM) as weak supervision to learn flexible and promptable definitions of object instances free of any specific object taxonomy. To handle the challenge of dynamic objects in ego-centric videos, we design a transient prediction module that learns to filter out dynamic objects in the 3D reconstruction. The result is a fully automatic pipeline that is able to reconstruct 3D object instances as collections of 3D Gaussians that collectively compose the entire scene. We created a new benchmark on the Aria Digital Twin dataset that quantitatively demonstrates its state-of-the-art performance in open-world 3D segmentation from natural egocentric input. We run EgoLifter on various egocentric activity datasets which shows the promise of the method for 3D egocentric perception at scale.
SceneScript: Reconstructing Scenes With An Autoregressive Structured Language Model
Mar 19, 2024

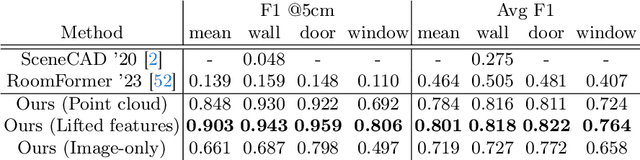
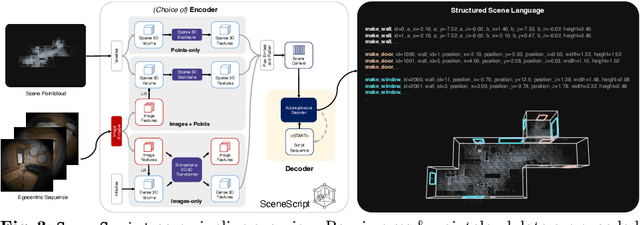
We introduce SceneScript, a method that directly produces full scene models as a sequence of structured language commands using an autoregressive, token-based approach. Our proposed scene representation is inspired by recent successes in transformers & LLMs, and departs from more traditional methods which commonly describe scenes as meshes, voxel grids, point clouds or radiance fields. Our method infers the set of structured language commands directly from encoded visual data using a scene language encoder-decoder architecture. To train SceneScript, we generate and release a large-scale synthetic dataset called Aria Synthetic Environments consisting of 100k high-quality in-door scenes, with photorealistic and ground-truth annotated renders of egocentric scene walkthroughs. Our method gives state-of-the art results in architectural layout estimation, and competitive results in 3D object detection. Lastly, we explore an advantage for SceneScript, which is the ability to readily adapt to new commands via simple additions to the structured language, which we illustrate for tasks such as coarse 3D object part reconstruction.
Real-Time Dense Stereo Matching With ELAS on FPGA Accelerated Embedded Devices
Feb 20, 2018
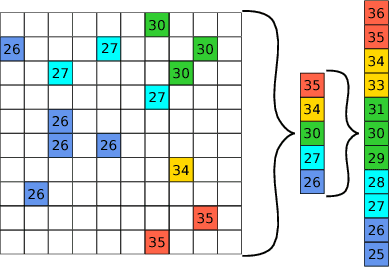

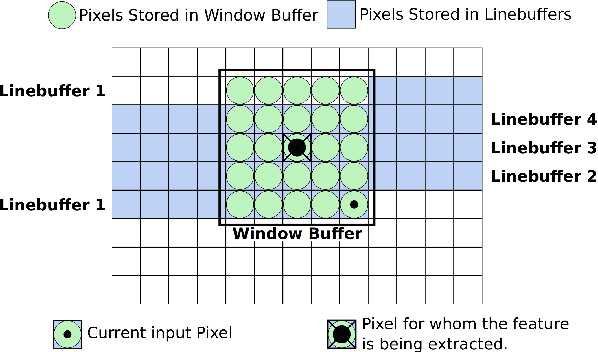
For many applications in low-power real-time robotics, stereo cameras are the sensors of choice for depth perception as they are typically cheaper and more versatile than their active counterparts. Their biggest drawback, however, is that they do not directly sense depth maps; instead, these must be estimated through data-intensive processes. Therefore, appropriate algorithm selection plays an important role in achieving the desired performance characteristics. Motivated by applications in space and mobile robotics, we implement and evaluate a FPGA-accelerated adaptation of the ELAS algorithm. Despite offering one of the best trade-offs between efficiency and accuracy, ELAS has only been shown to run at 1.5-3 fps on a high-end CPU. Our system preserves all intriguing properties of the original algorithm, such as the slanted plane priors, but can achieve a frame rate of 47fps whilst consuming under 4W of power. Unlike previous FPGA based designs, we take advantage of both components on the CPU/FPGA System-on-Chip to showcase the strategy necessary to accelerate more complex and computationally diverse algorithms for such low power, real-time systems.