 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneScript: Reconstructing Scenes With An Autoregressive Structured Language Model
Mar 19, 2024

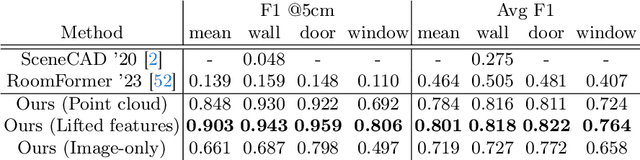
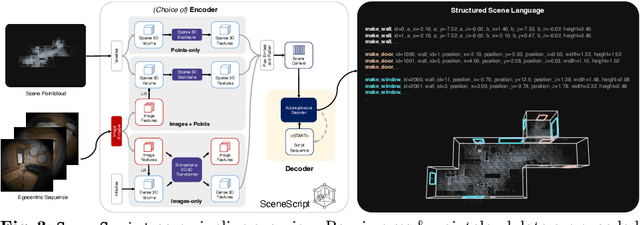
We introduce SceneScript, a method that directly produces full scene models as a sequence of structured language commands using an autoregressive, token-based approach. Our proposed scene representation is inspired by recent successes in transformers & LLMs, and departs from more traditional methods which commonly describe scenes as meshes, voxel grids, point clouds or radiance fields. Our method infers the set of structured language commands directly from encoded visual data using a scene language encoder-decoder architecture. To train SceneScript, we generate and release a large-scale synthetic dataset called Aria Synthetic Environments consisting of 100k high-quality in-door scenes, with photorealistic and ground-truth annotated renders of egocentric scene walkthroughs. Our method gives state-of-the art results in architectural layout estimation, and competitive results in 3D object detection. Lastly, we explore an advantage for SceneScript, which is the ability to readily adapt to new commands via simple additions to the structured language, which we illustrate for tasks such as coarse 3D object part reconstruction.
A Joint 3D-2D based Method for Free Space Detection on Roads
Jan 15, 2018

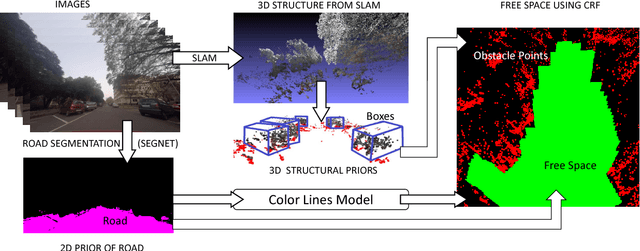
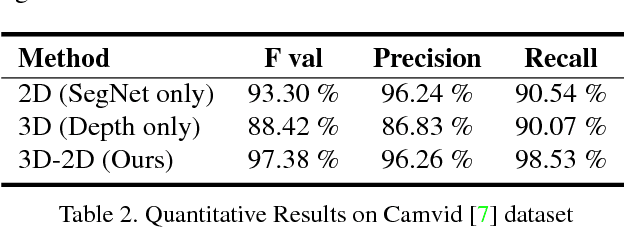
In this paper, we address the problem of road segmentation and free space detection in the context of autonomous driving. Traditional methods either use 3-dimensional (3D) cues such as point clouds obtained from LIDAR, RADAR or stereo cameras or 2-dimensional (2D) cues such as lane markings, road boundaries and object detection. Typical 3D point clouds do not have enough resolution to detect fine differences in heights such as between road and pavement. Image based 2D cues fail when encountering uneven road textures such as due to shadows, potholes, lane markings or road restoration. We propose a novel free road space detection technique combining both 2D and 3D cues. In particular, we use CNN based road segmentation from 2D images and plane/box fitting on sparse depth data obtained from SLAM as priors to formulate an energy minimization using conditional random field (CRF), for road pixels classification. While the CNN learns the road texture and is unaffected by depth boundaries, the 3D information helps in overcoming texture based classification failures. Finally, we use the obtained road segmentation with the 3D depth data from monocular SLAM to detect the free space for the navigation purposes. Our experiments on KITTI odometry dataset, Camvid dataset, as well as videos captured by us, validate the superiority of the proposed approach over the state of the art.
Batch based Monocular SLAM for Egocentric Videos
Jul 18, 2017


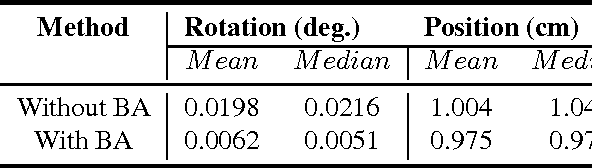
Simultaneous Localization and Mapping (SLAM) from a monocular camera has been a well researched area. However, estimating camera pose and 3d geometry reliably for egocentric videos still remain a challenge. Some of the common causes of failures are dominant 3D rotations and low parallax between successive frames, resulting in unreliable pose and 3d estimates. For forward moving cameras, with no opportunities for loop closures, the drift leads to eventual failures for traditional feature based and direct SLAM techniques. We propose a novel batch mode structure from motion based technique for robust SLAM in such scenarios. In contrast to most of the existing techniques, we process frames in short batches, wherein we exploit short loop closures arising out of to-and-fro motion of wearer's head, and stabilize the egomotion estimates by 2D batch mode techniques such as motion averaging on pairwise epipolar results. Once pose estimates are obtained reliably over a batch, we refine the 3d estimate by triangulation and batch mode Bundle Adjustment (BA). Finally, we merge the batches using 3D correspondences and carry out a BA refinement post merging. We present both qualitative and quantitative comparison of our method on various public first and third person video datasets, to establish the robustness and accuracy of our algorithm over the state of the art.
Computing Egomotion with Local Loop Closures for Egocentric Videos
Jan 17, 2017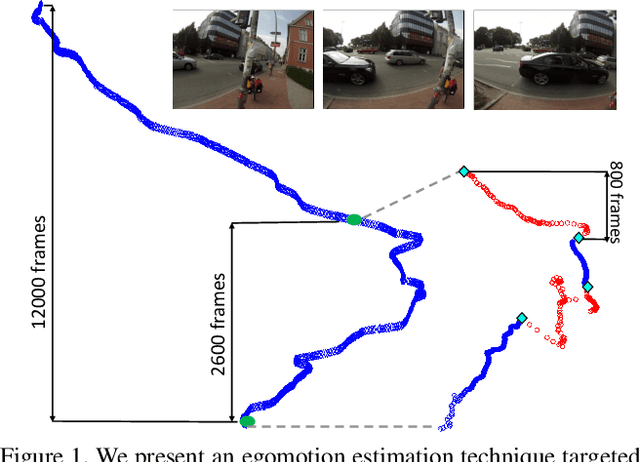
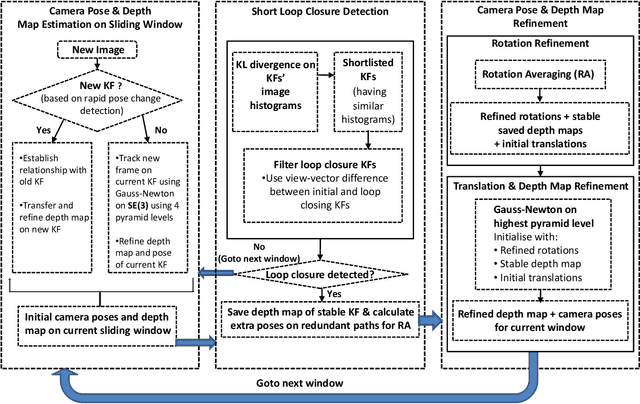

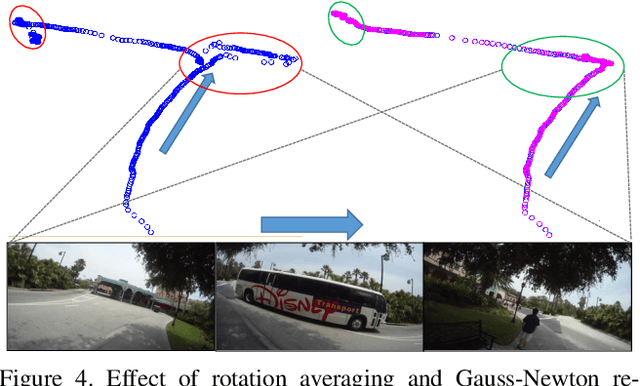
Finding the camera pose is an important step in many egocentric video applications. It has been widely reported that, state of the art SLAM algorithms fail on egocentric videos. In this paper, we propose a robust method for camera pose estimation, designed specifically for egocentric videos. In an egocentric video, the camera views the same scene point multiple times as the wearer's head sweeps back and forth. We use this specific motion profile to perform short loop closures aligned with wearer's footsteps. For egocentric videos, depth estimation is usually noisy. In an important departure, we use 2D computations for rotation averaging which do not rely upon depth estimates. The two modification results in much more stable algorithm as is evident from our experiments on various egocentric video datasets for different egocentric applications. The proposed algorithm resolves a long standing problem in egocentric vision and unlocks new usage scenarios for future applications.