 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Learning for Continuous Control
Feb 03, 2018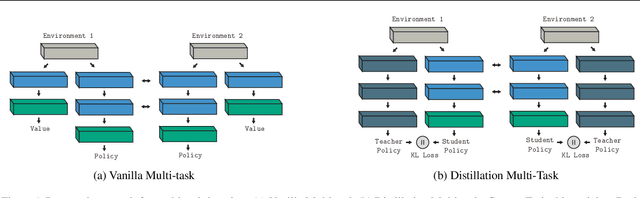

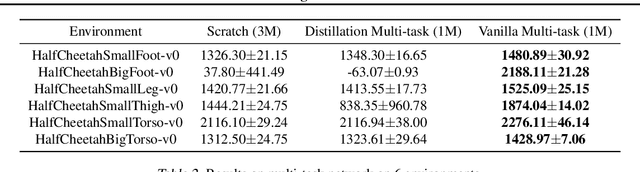
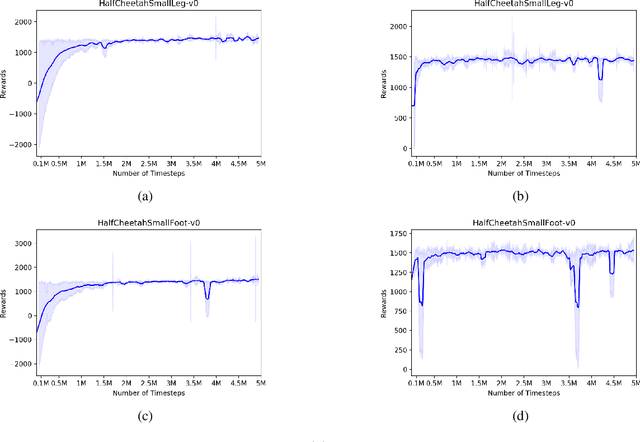
Reliable and effective multi-task learning is a prerequisite for the development of robotic agents that can quickly learn to accomplish related, everyday tasks. However, in the reinforcement learning domain, multi-task learning has not exhibited the same level of success as in other domains, such as computer vision. In addition, most reinforcement learning research on multi-task learning has been focused on discrete action spaces, which are not used for robotic control in the real-world. In this work, we apply multi-task learning methods to continuous action spaces and benchmark their performance on a series of simulated continuous control tasks. Most notably, we show that multi-task learning outperforms our baselines and alternative knowledge sharing methods.
Lip2AudSpec: Speech reconstruction from silent lip movements video
Oct 26, 2017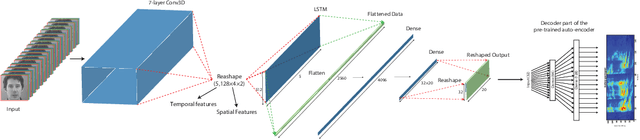
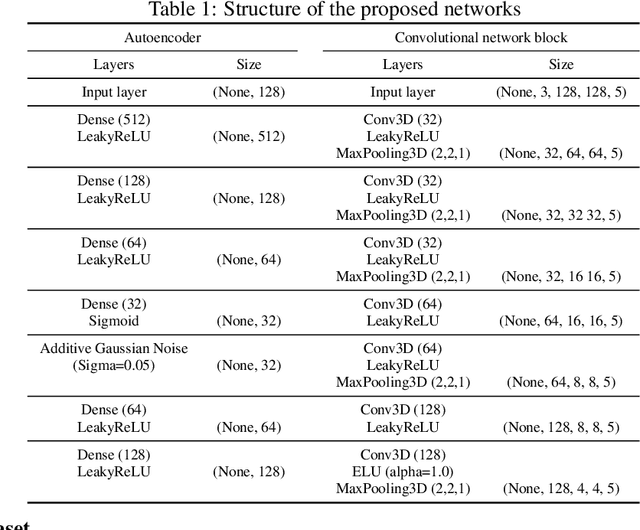

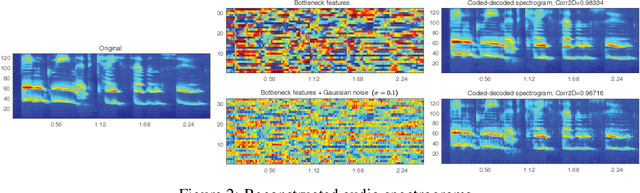
In this study, we propose a deep neural network for reconstructing intelligible speech from silent lip movement videos. We use auditory spectrogram as spectral representation of speech and its corresponding sound generation method resulting in a more natural sounding reconstructed speech. Our proposed network consists of an autoencoder to extract bottleneck features from the auditory spectrogram which is then used as target to our main lip reading network comprising of CNN, LSTM and fully connected layers. Our experiments show that the autoencoder is able to reconstruct the original auditory spectrogram with a 98% correlation and also improves the quality of reconstructed speech from the main lip reading network. Our model, trained jointly on different speakers is able to extract individual speaker characteristics and gives promising results of reconstructing intelligible speech with superior word recognition accuracy.
Computing Egomotion with Local Loop Closures for Egocentric Videos
Jan 17, 2017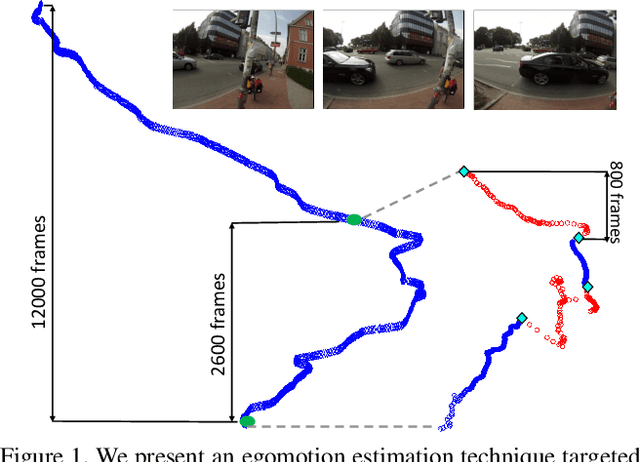
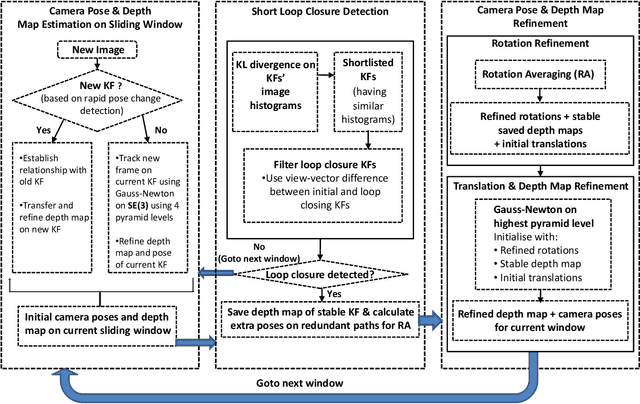

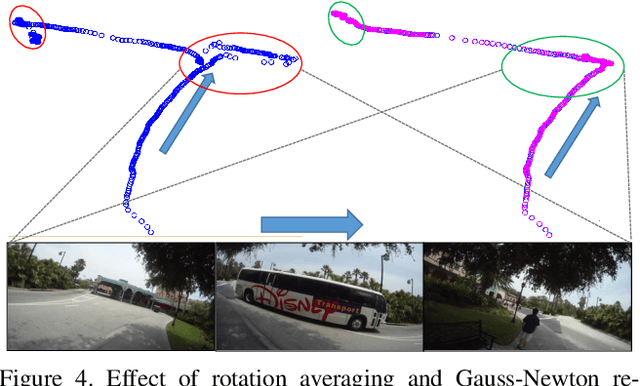
Finding the camera pose is an important step in many egocentric video applications. It has been widely reported that, state of the art SLAM algorithms fail on egocentric videos. In this paper, we propose a robust method for camera pose estimation, designed specifically for egocentric videos. In an egocentric video, the camera views the same scene point multiple times as the wearer's head sweeps back and forth. We use this specific motion profile to perform short loop closures aligned with wearer's footsteps. For egocentric videos, depth estimation is usually noisy. In an important departure, we use 2D computations for rotation averaging which do not rely upon depth estimates. The two modification results in much more stable algorithm as is evident from our experiments on various egocentric video datasets for different egocentric applications. The proposed algorithm resolves a long standing problem in egocentric vision and unlocks new usage scenarios for future applications.