 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntuitive control of supernumerary robotic limbs through a tactile-encoded neural interface
Nov 11, 2025



Brain-computer interfaces (BCIs) promise to extend human movement capabilities by enabling direct neural control of supernumerary effectors, yet integrating augmented commands with multiple degrees of freedom without disrupting natural movement remains a key challenge. Here, we propose a tactile-encoded BCI that leverages sensory afferents through a novel tactile-evoked P300 paradigm, allowing intuitive and reliable decoding of supernumerary motor intentions even when superimposed with voluntary actions. The interface was evaluated in a multi-day experiment comprising of a single motor recognition task to validate baseline BCI performance and a dual task paradigm to assess the potential influence between the BCI and natural human movement. The brain interface achieved real-time and reliable decoding of four supernumerary degrees of freedom, with significant performance improvements after only three days of training. Importantly, after training, performance did not differ significantly between the single- and dual-BCI task conditions, and natural movement remained unimpaired during concurrent supernumerary control. Lastly, the interface was deployed in a movement augmentation task, demonstrating its ability to command two supernumerary robotic arms for functional assistance during bimanual tasks. These results establish a new neural interface paradigm for movement augmentation through stimulation of sensory afferents, expanding motor degrees of freedom without impairing natural movement.
Parallel Scaling Law: Unveiling Reasoning Generalization through A Cross-Linguistic Perspective
Oct 02, 2025Recent advancements in Reinforcement Post-Training (RPT) have significantly enhanced the capabilities of Large Reasoning Models (LRMs), sparking increased interest in the generalization of RL-based reasoning. While existing work has primarily focused on investigating its generalization across tasks or modalities, this study proposes a novel cross-linguistic perspective to investigate reasoning generalization. This raises a crucial question: $\textit{Does the reasoning capability achieved from English RPT effectively transfer to other languages?}$ We address this by systematically evaluating English-centric LRMs on multilingual reasoning benchmarks and introducing a metric to quantify cross-lingual transferability. Our findings reveal that cross-lingual transferability varies significantly across initial model, target language, and training paradigm. Through interventional studies, we find that models with stronger initial English capabilities tend to over-rely on English-specific patterns, leading to diminished cross-lingual generalization. To address this, we conduct a thorough parallel training study. Experimental results yield three key findings: $\textbf{First-Parallel Leap}$, a substantial leap in performance when transitioning from monolingual to just a single parallel language, and a predictable $\textbf{Parallel Scaling Law}$, revealing that cross-lingual reasoning transfer follows a power-law with the number of training parallel languages. Moreover, we identify the discrepancy between actual monolingual performance and the power-law prediction as $\textbf{Monolingual Generalization Gap}$, indicating that English-centric LRMs fail to fully generalize across languages. Our study challenges the assumption that LRM reasoning mirrors human cognition, providing critical insights for the development of more language-agnostic LRMs.
Data Efficacy for Language Model Training
Jun 26, 2025Data is fundamental to the training of language models (LM). Recent research has been dedicated to data efficiency, which aims to maximize performance by selecting a minimal or optimal subset of training data. Techniques such as data filtering, sampling, and selection play a crucial role in this area. To complement it, we define Data Efficacy, which focuses on maximizing performance by optimizing the organization of training data and remains relatively underexplored. This work introduces a general paradigm, DELT, for considering data efficacy in LM training, which highlights the significance of training data organization. DELT comprises three components: Data Scoring, Data Selection, and Data Ordering. Among these components, we design Learnability-Quality Scoring (LQS), as a new instance of Data Scoring, which considers both the learnability and quality of each data sample from the gradient consistency perspective. We also devise Folding Ordering (FO), as a novel instance of Data Ordering, which addresses issues such as model forgetting and data distribution bias. Comprehensive experiments validate the data efficacy in LM training, which demonstrates the following: Firstly, various instances of the proposed DELT enhance LM performance to varying degrees without increasing the data scale and model size. Secondly, among these instances, the combination of our proposed LQS for data scoring and Folding for data ordering achieves the most significant improvement. Lastly, data efficacy can be achieved together with data efficiency by applying data selection. Therefore, we believe that data efficacy is a promising foundational area in LM training.
Efficient Medical VIE via Reinforcement Learning
Jun 16, 2025Visual Information Extraction (VIE) converts unstructured document images into structured formats like JSON, critical for medical applications such as report analysis and online consultations. Traditional methods rely on OCR and language models, while end-to-end multimodal models offer direct JSON generation. However, domain-specific schemas and high annotation costs limit their effectiveness in medical VIE. We base our approach on the Reinforcement Learning with Verifiable Rewards (RLVR) framework to address these challenges using only 100 annotated samples. Our approach ensures dataset diversity, a balanced precision-recall reward mechanism to reduce hallucinations and improve field coverage, and innovative sampling strategies to enhance reasoning capabilities. Fine-tuning Qwen2.5-VL-7B with our RLVR method, we achieve state-of-the-art performance on medical VIE tasks, significantly improving F1, precision, and recall. While our models excel on tasks similar to medical datasets, performance drops on dissimilar tasks, highlighting the need for domain-specific optimization. Case studies further demonstrate the value of reasoning during training and inference for VIE.
Group then Scale: Dynamic Mixture-of-Experts Multilingual Language Model
Jun 14, 2025The curse of multilinguality phenomenon is a fundamental problem of multilingual Large Language Models (LLMs), where the competition between massive languages results in inferior performance. It mainly comes from limited capacity and negative transfer between dissimilar languages. To address this issue, we propose a method to dynamically group and scale up the parameters of multilingual LLM while boosting positive transfer among similar languages. Specifically, the model is first tuned on monolingual corpus to determine the parameter deviation in each layer and quantify the similarity between languages. Layers with more deviations are extended to mixture-of-experts layers to reduce competition between languages, where one expert module serves one group of similar languages. Experimental results on 18 to 128 languages show that our method reduces the negative transfer between languages and significantly boosts multilingual performance with fewer parameters. Such language group specialization on experts benefits the new language adaptation and reduces the inference on the previous multilingual knowledge learned.
DIMT25@ICDAR2025: HW-TSC's End-to-End Document Image Machine Translation System Leveraging Large Vision-Language Model
Apr 24, 2025This paper presents the technical solution proposed by Huawei Translation Service Center (HW-TSC) for the "End-to-End Document Image Machine Translation for Complex Layouts" competition at the 19th International Conference on Document Analysis and Recognition (DIMT25@ICDAR2025). Leveraging state-of-the-art open-source large vision-language model (LVLM), we introduce a training framework that combines multi-task learning with perceptual chain-of-thought to develop a comprehensive end-to-end document translation system. During the inference phase, we apply minimum Bayesian decoding and post-processing strategies to further enhance the system's translation capabilities. Our solution uniquely addresses both OCR-based and OCR-free document image translation tasks within a unified framework. This paper systematically details the training methods, inference strategies, LVLM base models, training data, experimental setups, and results, demonstrating an effective approach to document image machine translation.
DecoFuse: Decomposing and Fusing the "What", "Where", and "How" for Brain-Inspired fMRI-to-Video Decoding
Apr 01, 2025Decoding visual experiences from brain activity is a significant challenge. Existing fMRI-to-video methods often focus on semantic content while overlooking spatial and motion information. However, these aspects are all essential and are processed through distinct pathways in the brain. Motivated by this, we propose DecoFuse, a novel brain-inspired framework for decoding videos from fMRI signals. It first decomposes the video into three components - semantic, spatial, and motion - then decodes each component separately before fusing them to reconstruct the video. This approach not only simplifies the complex task of video decoding by decomposing it into manageable sub-tasks, but also establishes a clearer connection between learned representations and their biological counterpart, as supported by ablation studies. Further, our experiments show significant improvements over previous state-of-the-art methods, achieving 82.4% accuracy for semantic classification, 70.6% accuracy in spatial consistency, a 0.212 cosine similarity for motion prediction, and 21.9% 50-way accuracy for video generation. Additionally, neural encoding analyses for semantic and spatial information align with the two-streams hypothesis, further validating the distinct roles of the ventral and dorsal pathways. Overall, DecoFuse provides a strong and biologically plausible framework for fMRI-to-video decoding. Project page: https://chongjg.github.io/DecoFuse/.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Decoding the Flow: CauseMotion for Emotional Causality Analysis in Long-form Conversations
Jan 01, 2025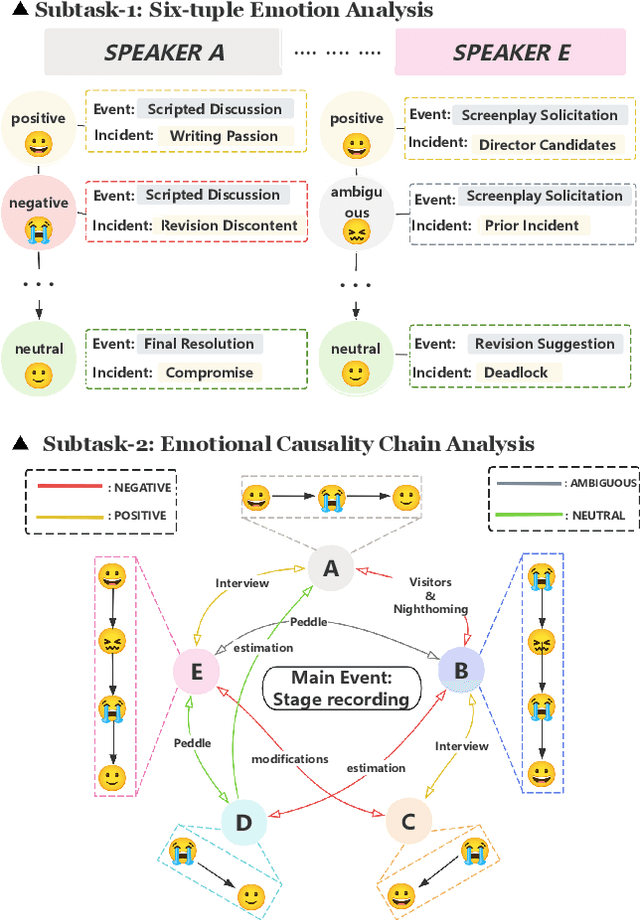
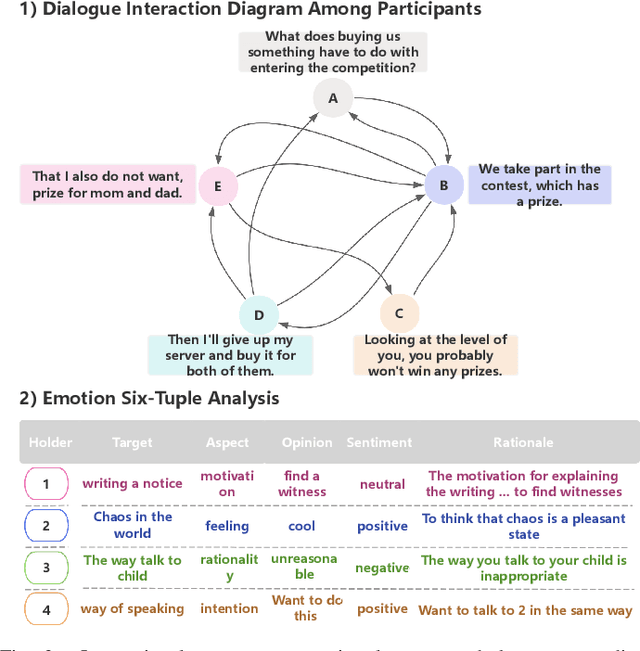
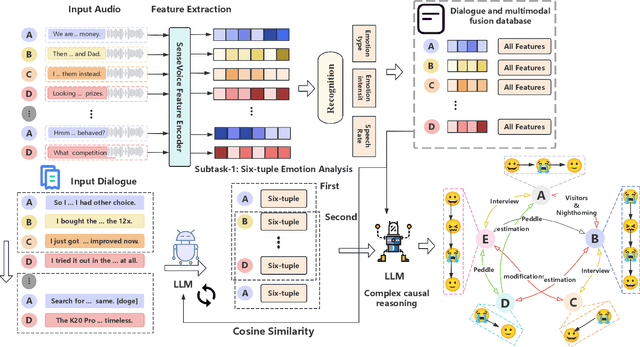
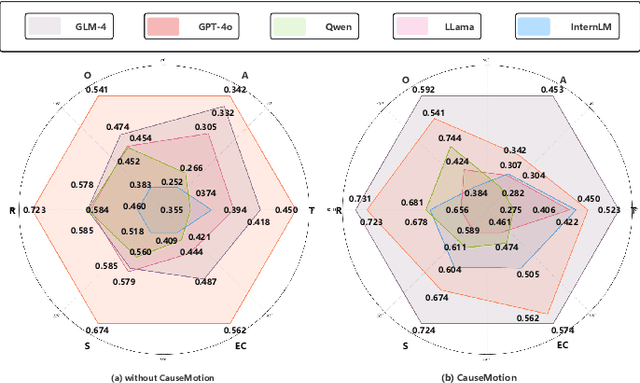
Long-sequence causal reasoning seeks to uncover causal relationships within extended time series data but is hindered by complex dependencies and the challenges of validating causal links. To address the limitations of large-scale language models (e.g., GPT-4) in capturing intricate emotional causality within extended dialogues, we propose CauseMotion, a long-sequence emotional causal reasoning framework grounded in Retrieval-Augmented Generation (RAG) and multimodal fusion. Unlike conventional methods relying only on textual information, CauseMotion enriches semantic representations by incorporating audio-derived features-vocal emotion, emotional intensity, and speech rate-into textual modalities. By integrating RAG with a sliding window mechanism, it effectively retrieves and leverages contextually relevant dialogue segments, thus enabling the inference of complex emotional causal chains spanning multiple conversational turns. To evaluate its effectiveness, we constructed the first benchmark dataset dedicated to long-sequence emotional causal reasoning, featuring dialogues with over 70 turns. Experimental results demonstrate that the proposed RAG-based multimodal integrated approach, the efficacy of substantially enhances both the depth of emotional understanding and the causal inference capabilities of large-scale language models. A GLM-4 integrated with CauseMotion achieves an 8.7% improvement in causal accuracy over the original model and surpasses GPT-4o by 1.2%. Additionally, on the publicly available DiaASQ dataset, CauseMotion-GLM-4 achieves state-of-the-art results in accuracy, F1 score, and causal reasoning accuracy.
LLM$\times$MapReduce: Simplified Long-Sequence Processing using Large Language Models
Oct 12, 2024



Enlarging the context window of large language models (LLMs) has become a crucial research area, particularly for applications involving extremely long texts. In this work, we propose a novel training-free framework for processing long texts, utilizing a divide-and-conquer strategy to achieve comprehensive document understanding. The proposed LLM$\times$MapReduce framework splits the entire document into several chunks for LLMs to read and then aggregates the intermediate answers to produce the final output. The main challenge for divide-and-conquer long text processing frameworks lies in the risk of losing essential long-range information when splitting the document, which can lead the model to produce incomplete or incorrect answers based on the segmented texts. Disrupted long-range information can be classified into two categories: inter-chunk dependency and inter-chunk conflict. We design a structured information protocol to better cope with inter-chunk dependency and an in-context confidence calibration mechanism to resolve inter-chunk conflicts. Experimental results demonstrate that LLM$\times$MapReduce can outperform representative open-source and commercial long-context LLMs, and is applicable to several different models.