 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative and Compact Structured Latents for 3D Generation
Dec 16, 2025Recent advancements in 3D generative modeling have significantly improved the generation realism, yet the field is still hampered by existing representations, which struggle to capture assets with complex topologies and detailed appearance. This paper present an approach for learning a structured latent representation from native 3D data to address this challenge. At its core is a new sparse voxel structure called O-Voxel, an omni-voxel representation that encodes both geometry and appearance. O-Voxel can robustly model arbitrary topology, including open, non-manifold, and fully-enclosed surfaces, while capturing comprehensive surface attributes beyond texture color, such as physically-based rendering parameters. Based on O-Voxel, we design a Sparse Compression VAE which provides a high spatial compression rate and a compact latent space. We train large-scale flow-matching models comprising 4B parameters for 3D generation using diverse public 3D asset datasets. Despite their scale, inference remains highly efficient. Meanwhile, the geometry and material quality of our generated assets far exceed those of existing models. We believe our approach offers a significant advancement in 3D generative modeling.
VASA-3D: Lifelike Audio-Driven Gaussian Head Avatars from a Single Image
Dec 16, 2025We propose VASA-3D, an audio-driven, single-shot 3D head avatar generator. This research tackles two major challenges: capturing the subtle expression details present in real human faces, and reconstructing an intricate 3D head avatar from a single portrait image. To accurately model expression details, VASA-3D leverages the motion latent of VASA-1, a method that yields exceptional realism and vividness in 2D talking heads. A critical element of our work is translating this motion latent to 3D, which is accomplished by devising a 3D head model that is conditioned on the motion latent. Customization of this model to a single image is achieved through an optimization framework that employs numerous video frames of the reference head synthesized from the input image. The optimization takes various training losses robust to artifacts and limited pose coverage in the generated training data. Our experiment shows that VASA-3D produces realistic 3D talking heads that cannot be achieved by prior art, and it supports the online generation of 512x512 free-viewpoint videos at up to 75 FPS, facilitating more immersive engagements with lifelike 3D avatars.
Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos
Oct 24, 2025



This paper presents a novel approach for pretraining robotic manipulation Vision-Language-Action (VLA) models using a large corpus of unscripted real-life video recordings of human hand activities. Treating human hand as dexterous robot end-effector, we show that "in-the-wild" egocentric human videos without any annotations can be transformed into data formats fully aligned with existing robotic V-L-A training data in terms of task granularity and labels. This is achieved by the development of a fully-automated holistic human activity analysis approach for arbitrary human hand videos. This approach can generate atomic-level hand activity segments and their language descriptions, each accompanied with framewise 3D hand motion and camera motion. We process a large volume of egocentric videos and create a hand-VLA training dataset containing 1M episodes and 26M frames. This training data covers a wide range of objects and concepts, dexterous manipulation tasks, and environment variations in real life, vastly exceeding the coverage of existing robot data. We design a dexterous hand VLA model architecture and pretrain the model on this dataset. The model exhibits strong zero-shot capabilities on completely unseen real-world observations. Additionally, fine-tuning it on a small amount of real robot action data significantly improves task success rates and generalization to novel objects in real robotic experiments. We also demonstrate the appealing scaling behavior of the model's task performance with respect to pretraining data scale. We believe this work lays a solid foundation for scalable VLA pretraining, advancing robots toward truly generalizable embodied intelligence.
Gaussian Variation Field Diffusion for High-fidelity Video-to-4D Synthesis
Jul 31, 2025In this paper, we present a novel framework for video-to-4D generation that creates high-quality dynamic 3D content from single video inputs. Direct 4D diffusion modeling is extremely challenging due to costly data construction and the high-dimensional nature of jointly representing 3D shape, appearance, and motion. We address these challenges by introducing a Direct 4DMesh-to-GS Variation Field VAE that directly encodes canonical Gaussian Splats (GS) and their temporal variations from 3D animation data without per-instance fitting, and compresses high-dimensional animations into a compact latent space. Building upon this efficient representation, we train a Gaussian Variation Field diffusion model with temporal-aware Diffusion Transformer conditioned on input videos and canonical GS. Trained on carefully-curated animatable 3D objects from the Objaverse dataset, our model demonstrates superior generation quality compared to existing methods. It also exhibits remarkable generalization to in-the-wild video inputs despite being trained exclusively on synthetic data, paving the way for generating high-quality animated 3D content. Project page: https://gvfdiffusion.github.io/.
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Jul 03, 2025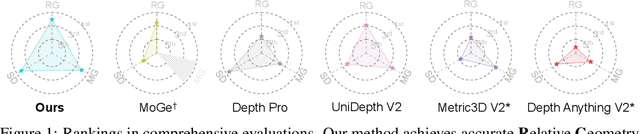
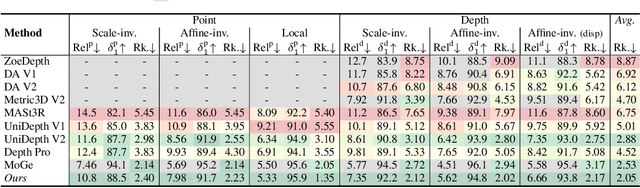
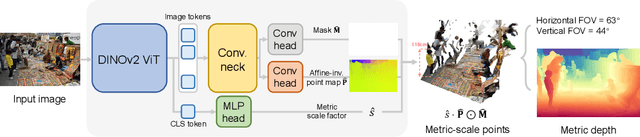
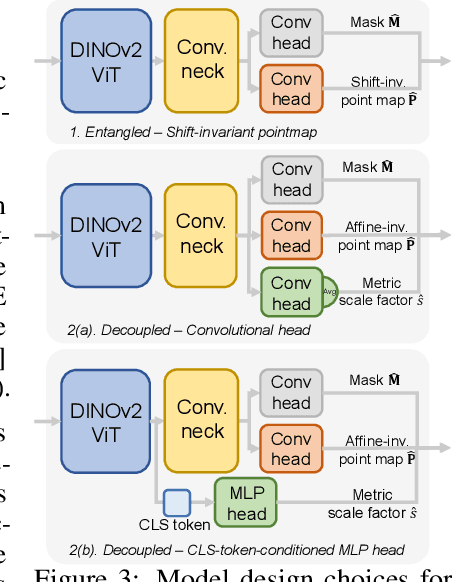
We propose MoGe-2, an advanced open-domain geometry estimation model that recovers a metric scale 3D point map of a scene from a single image. Our method builds upon the recent monocular geometry estimation approach, MoGe, which predicts affine-invariant point maps with unknown scales. We explore effective strategies to extend MoGe for metric geometry prediction without compromising the relative geometry accuracy provided by the affine-invariant point representation. Additionally, we discover that noise and errors in real data diminish fine-grained detail in the predicted geometry. We address this by developing a unified data refinement approach that filters and completes real data from different sources using sharp synthetic labels, significantly enhancing the granularity of the reconstructed geometry while maintaining the overall accuracy. We train our model on a large corpus of mixed datasets and conducted comprehensive evaluations, demonstrating its superior performance in achieving accurate relative geometry, precise metric scale, and fine-grained detail recovery -- capabilities that no previous methods have simultaneously achieved.
Structured 3D Latents for Scalable and Versatile 3D Generation
Dec 02, 2024



We introduce a novel 3D generation method for versatile and high-quality 3D asset creation. The cornerstone is a unified Structured LATent (SLAT) representation which allows decoding to different output formats, such as Radiance Fields, 3D Gaussians, and meshes. This is achieved by integrating a sparsely-populated 3D grid with dense multiview visual features extracted from a powerful vision foundation model, comprehensively capturing both structural (geometry) and textural (appearance) information while maintaining flexibility during decoding. We employ rectified flow transformers tailored for SLAT as our 3D generation models and train models with up to 2 billion parameters on a large 3D asset dataset of 500K diverse objects. Our model generates high-quality results with text or image conditions, significantly surpassing existing methods, including recent ones at similar scales. We showcase flexible output format selection and local 3D editing capabilities which were not offered by previous models. Code, model, and data will be released.
CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation
Nov 29, 2024



The advancement of large Vision-Language-Action (VLA) models has significantly improved robotic manipulation in terms of language-guided task execution and generalization to unseen scenarios. While existing VLAs adapted from pretrained large Vision-Language-Models (VLM) have demonstrated promising generalizability, their task performance is still unsatisfactory as indicated by the low tasks success rates in different environments. In this paper, we present a new advanced VLA architecture derived from VLM. Unlike previous works that directly repurpose VLM for action prediction by simple action quantization, we propose a omponentized VLA architecture that has a specialized action module conditioned on VLM output. We systematically study the design of the action module and demonstrates the strong performance enhancement with diffusion action transformers for action sequence modeling, as well as their favorable scaling behaviors. We also conduct comprehensive experiments and ablation studies to evaluate the efficacy of our models with varied designs. The evaluation on 5 robot embodiments in simulation and real work shows that our model not only significantly surpasses existing VLAs in task performance and but also exhibits remarkable adaptation to new robots and generalization to unseen objects and backgrounds. It exceeds the average success rates of OpenVLA which has similar model size (7B) with ours by over 35% in simulated evaluation and 55% in real robot experiments. It also outperforms the large RT-2-X model (55B) by 18% absolute success rates in simulation. Code and models can be found on our project page (https://cogact.github.io/).
MoGe: Unlocking Accurate Monocular Geometry Estimation for Open-Domain Images with Optimal Training Supervision
Oct 24, 2024



We present MoGe, a powerful model for recovering 3D geometry from monocular open-domain images. Given a single image, our model directly predicts a 3D point map of the captured scene with an affine-invariant representation, which is agnostic to true global scale and shift. This new representation precludes ambiguous supervision in training and facilitate effective geometry learning. Furthermore, we propose a set of novel global and local geometry supervisions that empower the model to learn high-quality geometry. These include a robust, optimal, and efficient point cloud alignment solver for accurate global shape learning, and a multi-scale local geometry loss promoting precise local geometry supervision. We train our model on a large, mixed dataset and demonstrate its strong generalizability and high accuracy. In our comprehensive evaluation on diverse unseen datasets, our model significantly outperforms state-of-the-art methods across all tasks, including monocular estimation of 3D point map, depth map, and camera field of view. Code and models will be released on our project page.
VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
Apr 16, 2024



We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only producing lip movements that are exquisitely synchronized with the audio, but also capturing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos. Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method not only delivers high video quality with realistic facial and head dynamics but also supports the online generation of 512x512 videos at up to 40 FPS with negligible starting latency. It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors.
AniPortraitGAN: Animatable 3D Portrait Generation from 2D Image Collections
Sep 05, 2023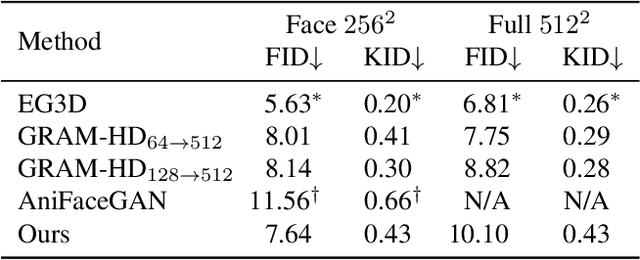
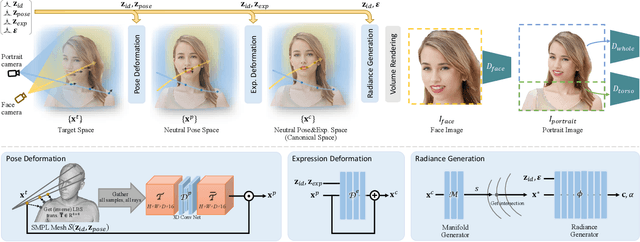


Previous animatable 3D-aware GANs for human generation have primarily focused on either the human head or full body. However, head-only videos are relatively uncommon in real life, and full body generation typically does not deal with facial expression control and still has challenges in generating high-quality results. Towards applicable video avatars, we present an animatable 3D-aware GAN that generates portrait images with controllable facial expression, head pose, and shoulder movements. It is a generative model trained on unstructured 2D image collections without using 3D or video data. For the new task, we base our method on the generative radiance manifold representation and equip it with learnable facial and head-shoulder deformations. A dual-camera rendering and adversarial learning scheme is proposed to improve the quality of the generated faces, which is critical for portrait images. A pose deformation processing network is developed to generate plausible deformations for challenging regions such as long hair. Experiments show that our method, trained on unstructured 2D images, can generate diverse and high-quality 3D portraits with desired control over different properties.